Refer [1], always-inline is not suggested to be used if you have indirect
calls. so replace force_inline with inline to fix error like:
In function ‘combine_inner’,
inlined from ‘combine_soft_light_ca_float’ at ../pixman/pixman-combine-float.c:655:511:
../pixman/pixman-combine-float.c:655:211: error: inlining failed in call to ‘always_inline’ ‘combine_soft_light_c’: function not considered for inlining
Test with gcc-9 and gcc-14, both works well
[1] https://gcc.gnu.org/bugzilla/show_bug.cgi?id=115679
Signed-off-by: Changqing Li <changqing.li@windriver.com>
Temporary version pin of gcovr due to errors in coverage report
generation when running with newly released version 8.x.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
https://github.com/mesonbuild/meson/pull/13604 got merged and released
with Meson 1.6.0, which we already use in the Docker images, so the
workaround can be dropped.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
Some targets require different version of LLVM, so now it's possible to
set it in the target's environment. Mind that the highest available
version depends on the base Debian image.
The change bumps LLVM version for all Linux targets:
- by default from 14 to 16,
- from 16 to 18 for riscv64 (based on Sid; for now, LLVM 19 doesn't have
libomp packaged),
- mipsel stays at 14 as there seem to be some missing packages for
higher versions.
Windows targets stay the same, as they use a different source of LLVM
(MinGW-compatible, which is currently version 18).
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
To ensure that the runtime discovery works correctly, and RVV code is
disabled for target without RVV extension.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
RVV compilation will be enabled for RVV implementation alone, similar to
other platforms. This prevents introducing autovectorized code in the
main library, thus making pixman compatible with RISC-V targets without
RVV.
If rule condition for selectively running Docker image builds was ill
formed. It resulted in build of all images even when not all targets
were selected with ACTIVE_TARGET_PATTERN variable.
If the MR doesn't modify the Docker context, the pipeline should use the
image from upstream.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
This commit unifies codecov and pltcov build and test stages as single
parametrizable GitLab job templates. This cleans up the pipeline flow in
preparation for LLVM support in the pipeline.
Each target has now a Meson cross file, even when using a native
compiler, so that the job template can be better generalized. This also
allows to move architecture-specific build configuration to the cross
file instead of using the additional Meson flags in the job declaration.
This commit merges codecov and pltcov Dockerfiles into a single,
multi-stage Dockerfile. This results in more streamlined Docker image
builds with some common layers which can be reused by multiple images.
Also, by making a common Dockerfile, all common dependencies have the
same exact description, which decreases disparity between different
images for all the supported architectures. Mind that package version
disparity cannot be prevented 100%, as different base images may be used
for different architectures (e.g., Debian Sid for riscv64 instead of
Bookworm).
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
It replaces CODE- and PLT- specific target enable variables. It is a
ground work for unification of codecov and pltcov flows.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
It makes per-targe environment declaration more extensible, as it's
possible now to set custom env variables only for the selected target
for the entire pipeline workflow in a centralized way.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
There was a missing wildcard for Docker directory
change detection, so basically this rule was not
checked correctly.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
Platform coverage checks if the code builds and executes properly for
architectures that are not officially supported by Debian. They don't
contribute to general code coverage report but provide a valuable
insight if all supported platforms are working correctly.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
Add images providing an environment for architecture coverage tests.
There is a separate build for Linux and Windows, as the Windows image is
really large compared to Linux one. It decreases the execution time of
both targets, as the images needed to be pulled by runners are smaller.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
This commit introduces a build and test CI workflow, which tests the
correctness of execution for nearly all configurations supported by
pixman. The notable exception is ARM iWMMXt, which is omitted as it's
soon to be deprecated as mentioned in #98.
The build and test stage is separated, as a single build can be used to
test multiple configurations for a given platform (e.g., MMX, SSE2,
SSSE3 for x86).
Execution is performed using multi-arch Docker images built in the
`docker` stage. The important thing to note is that the runner needs to
have a relatively recent version of Docker and QEMU, and needs to have
the qemu-user-static+binfmt execution enabled.
Once all tests are complete, coverage reports are merged together in the
`summary` stage. Then the result can be used in a GitLab-native coverage
report summary.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
Used to force feature discovery in CI where /proc/cpuinfo is unreliable.
It can happen, e.g., if executed in qemu-user-static mode.
For such a build, MIPS-specific features need to be manually disabled by
using `PIXMAN_DISABLE` env variable.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
DSPr2 can be available for targets other than mips32. Some distros
(e.g., Debian) don't support mips32 but still support mipsel. Extending
the check enables use of such images for testing.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
The image is used in CI pipeline to build and test on different
architectures.
This commit introduces more extensible GitLab CI scheme borrowed from
qemu project.
Signed-off-by: Marek Pikuła <m.pikula@partner.samsung.com>
This avoids callers to have to optimize this codepath, in case this scenario happens.
And definitely it may happen when the function is not explicitly called.
Enable Pointer Authentication Codes (PAC) and Branch Target
Identification (BTI) support for ARM 64 targets.
PAC works by signing the LR with either an A key or B key and verifying
the return address. There are quite a few instructions capable of doing
this, however, the Linux ARM ABI is to use hint compatible instructions
that can be safely NOP'd on older hardware and can be assembled and
linked with older binutils. This limits the instruction set to paciasp,
pacibsp, autiasp and autibsp. Instructions prefixed with pac are for
signing and instructions prefixed with aut are for signing. Both
instructions are then followed with an a or b to indicate which signing
key they are using. The keys can be controlled using
-mbranch-protection=pac-ret for the A key and
-mbranch-protection=pac-ret+b-key for the B key.
BTI works by marking all call and jump positions with bti c and bti
j instructions. If execution control transfers to an instruction other
than a BTI instruction, the execution is killed via SIGILL. Note that
to remove one instruction, the aforementioned pac instructions will
also work as a BTI landing pad for bti c usages.
For BTI to work, all object files linked for a unit of execution,
whether an executable or a library must have the GNU Notes section of
the ELF file marked to indicate BTI support. This is so loader/linkers
can apply the proper permission bits (PROT_BRI) on the memory region.
PAC can also be annotated in the GNU ELF notes section, but it's not
required for enablement, as interleaved PAC and non-pac code works as
expected since it's the callee that performs all the checking. The
linker follows the same rules as BTI for discarding the PAC flag from
the GNU Notes section.
Testing was done under the following CFLAGS and CXXFLAGS for all
combinations:
1. -mbranch-protection=none
2. -mbranch-protection=standard
3. -mbranch-protection=pac-ret
4. -mbranch-protection=pac-ret+b-key
5. -mbranch-protection=bti
Signed-off-by: Bill Roberts <bill.roberts@arm.com>
This reverts commit b4a105d772.
There is an endianness issue in pixman-fast-path.c. In the function
bits_image_fetch_separable_convolution_affine we have this code:
#ifdef WORDS_BIGENDIAN
buffer[k] = (satot << 0) | (srtot << 8) | (sgtot << 16) | (sbtot << 24);
#else
buffer[k] = (satot << 24) | (srtot << 16) | (sgtot << 8) | (sbtot << 0);
#endif
This will write out the pixels as BGRA on big endian systems but
obviously that's wrong. Pixel order should be ARGB on big endian systems
so we don't need any #ifdef for big endian here at all. Instead, the
code should be the same on little and big endian, i.e. it should be just
this line instead of the 5 lines above:
buffer[k] = (satot << 24) | (srtot << 16) | (sgtot << 8) | (sbtot << 0);
Changing the code like this fixes the wrong colors that I get with
pixman on my PowerPC/s390x system.
Here is what cairo.h has to say (which is rooted in pixman):
* @CAIRO_FORMAT_ARGB32: each pixel is a 32-bit quantity, with
* alpha in the upper 8 bits, then red, then green, then blue.
* The 32-bit quantities are stored native-endian. Pre-multiplied
* alpha is used. (That is, 50% transparent red is 0x80800000,
* not 0x80ff0000.) (Since 1.0)
Closes: https://gitlab.freedesktop.org/pixman/pixman/-/issues/78
Signed-off-by: Gayathri Berli <gayathri.berli@ibm.com>
We don't use the historical odd stable release numbering scheme
anymore.
Developers can still enable this debugging code via CFLAGS=-DDEBUG.
Signed-off-by: Simon Ser <contact@emersion.fr>
Closes: https://gitlab.freedesktop.org/pixman/pixman/-/issues/87
The variable is accessed through uint32_t pointer, so it needs to be
aligned to avoid undefined behavior (crashes on architectures which
require aligned accesses).
Closes: https://gitlab.freedesktop.org/pixman/pixman/-/issues/84
GCC 14 introduces a new -Walloc-size included in -Wextra which gives (when forced
to be an error):
```
../pixman/pixman-bits-image.c: In function ‘create_bits’:
../pixman/pixman-bits-image.c:1273:16: error: allocation of insufficient size ‘1’ for type ‘uint32_t’ {aka ‘unsigned int’} with size ‘4’ [-Werror=alloc-size]
1273 | return calloc (buf_size, 1);
| ^~~~~~~~~~~~~~~~~~~~
```
The calloc prototype is:
```
void *calloc(size_t nmemb, size_t size);
```
So, just swap the number of members and size arguments to match the prototype, as
we're initialising 1 element of size `buf_size`. GCC then sees we're not
doing anything wrong.
Signed-off-by: Sam James <sam@gentoo.org>
Based on suggestion from @siamashka.
This lets the compiler pick the vector instruction to use which is
usually the best idea.
Use create_mask_32_128() instead of create_mask_1x32_128() in
vmx_fill(), avoiding loading memory beyond the filler argument on the
stack.
Remove the now-unused create_mask_1x32_128(). This gets rid of some
(correct) warnings from the compiler about indexing beyond the variable
in question.
Since combine4() does not take vector variables as arguments, there's no
need to use a vector variable and casts back and forth to normal scalars
for the arguments.
meson can handle building for win32 (including using visual studio, and
mingw), and does a good deal more than these could. Since we're dropping
autotools, we might as well drop these too.
At this point meson is pretty well tested and seems to pretty much work,
so we can consider dropping an extra build system.
This doesn't solve the problem that pixman's release scripts are part of
the autotools build system (as make targets). One solution might be to
use xorg's release.sh instead.
This enables building the aarch64 assembly with clang.
Changes:
1. Use `.func` or `.endfunc` only if available
2. Prefix macro arg names with `\`
3. Use `\()` instead of `&`
4. Always use commas to separate macro arguments
5. Prefix asm symbols with an undderscore if necessary
As of mingw-w64 commit 463f00975, winnt.h includes emmintrin.h when
compiling with SSE2, causing redefinition errors for our copied MMX
intrinsics. If the build is assuming SSE2 anyway, just use the system
header instead.
Inverse of pixman_region32_not_empty().
Most of the time, callers want to check whether a region is empty,
not whether a region is not empty. This results in code with
double-negatives such as !pixman_region32_not_empty(), which is
confusing to read.
Signed-off-by: Simon Ser <contact@emersion.fr>
After the latest changes and separation of demo- and test-targets,
it was visible that a dependency towards `libtestutils_dep` was
missing in one of the demo-dependencies. This change will fix
this particular problem.
This reverts commit aaf59b0338.
This commit regressed the scaling-test unit test, by apparently allowing
the compiler to emit fused multiply-add instructions in cases they
wouldn't have been allowed before. While using gcc's -ffp-contract=...
flag avoids the issue on amd64, it does not on at least aarch64 and
ppc64.
This is unfortunate, because the commit being reverted resolved
https://gitlab.freedesktop.org/pixman/pixman/-/issues/43 so we will
reintroduce this failure, but after more than a year without a fix for
the unit test, I think it's time to bite the bullet.
Fixes: https://gitlab.freedesktop.org/pixman/pixman/-/issues/49
This explicitly indicates that GNU extensions (like asm) are used.
This fixes build errors when Pixman is used as a Meson subproject.
Signed-off-by: Simon Ser <contact@emersion.fr>
When compiling with MinGW, use of the __thread attribute causes pixman
to gain a dependency on the winpthread DLL. With Autotools, this could
be avoided by configuring with ac_cv_tls=none, causing pixman to fall
back to TlsSetValue() instead.
Add a Meson 'tls' option that can be 'disabled' to skip support for TLS
compiler attributes, or 'enabled' to require a working TLS attribute.
Override the x64 hardware capability autodetection by Solaris Studio
compilers for x64 libraries the same way we do for x86 libraries.
Also fix configure test for this override to work in out-of-tree builds.
Signed-off-by: Alan Coopersmith <alan.coopersmith@oracle.com>
The library that the pkgconfig file is for should be the first
positional argument. The `libraries:` kwarg is for libraries that the
user must also link against, and which meson does not know about (and
hence cannot automatically add to the `Libs:` or `Requires:` section
in the .pc file).
Fixes:
```
subprojects/pixman/meson.build:564: DEPRECATION: Library pixman-1 was
passed to the "libraries" keyword argument of a previous call to
generate() method instead of first positional argument. Adding
pixman-1 to "Requires" field, but this is a deprecated behaviour that
will change in a future version of Meson. Please report the issue if
this warning cannot be avoided in your case.
```
We use this because of a meson bug that was fixed in 0.52:
https://mesonbuild.com/Release-notes-for-0-52-0.html#improved-support-for-static-libraries
Bump the requirement and remove the extract_all_objects workaround.
This gets rid of a meson warning:
WARNING: extract_all_objects called without setting recursive
keyword argument. Meson currently defaults to
non-recursive to maintain backward compatibility but
the default will be changed in the future.
GTK2 has reached end of life, and GTK3 has been available for a
almost a decade.
Signed-off-by: Manuel Stoeckl <code@mstoeckl.com>
Reviewed-by: Simon Ser <contact@emersion.fr>
Since aarch64 has different neon syntax from aarch32 and has no
support for (older) arm-simd,
there are no SIMD accelerations for pixman on aarch64.
We need new implementations.
This patch also contains Ben Avions's series of patches for aarch32
and now the benchmark results are fine to aarch64.
Please find the result at the below ticket.
Added: https://bugs.freedesktop.org/show_bug.cgi?id=94758
Signed-off-by: Mizuki Asakura <ed6e117f@gmail.com>
This allows callers to pass around const Pixman region in their
APIs, improving type safety and documentation.
Signed-off-by: Simon Ser <contact@emersion.fr>
prng_state and prng_state_data are getting classified as a "Common
symbol" by the compiler due to the convoluted way in which it is
`#include`-ed in various test sources, and that's not read as a valid
symbol by the linker later.
Initializing the symbol clarifies it to the compiler that this
specific declaration is the canonical location for this variable, and
that it's not a "Common symbol".
Fixes https://gitlab.freedesktop.org/pixman/pixman/-/issues/42
Adding const to the return type does nothing and means that the function
pointer types do not match exactly:
error: incompatible function pointer types passing 'const float (int, int)' to parameter of type 'dither_factor_t' (aka 'float (*)(int, int)')
In __bits_image_fetch_affine_no_alpha and __bits_image_fetch_general,
when `wide` is true, the mask is actually an array of argb_t instead
of the array of uint32_t it was cast to, and the access to `mask[i]`
does not correctly detect when the pixel is nontrivial. The code now
uses a check appropriate for argb_t when `wide` is true.
One caveat: this new check only skips entries when the mask pixel data
is binary all zero; this misses cases like `-0.f` which would be caught
by the FLOAT_IS_ZERO macro. As the mask check only appears to be a
performance optimization to avoid loading inconsequential pixels, it
erring on the side of loading more pixels is safe.
Signed-off-by: Manuel Stoeckl <code@mstoeckl.com>
The important changes here are a handful of places where we replace
memcpy(&m, mask++, sizeof(uint32_t));
or similar code with
uint8_t m = *mask++;
because we're only supposed to be reading a single byte from *mask,
and accessing a 32-bit value may read out of bounds (besides that
it reads values we don't actually want; whether this matters would
depend exactly how the value in m is subsequently used).
I've also changed a bunch of other places to use this same pattern
(a local 8-bit variable) when reading individual bytes from the mask;
the code was inconsistent about this, sometimes casting the byte to
a uint32_t instead. This makes no actual difference, it just seemed
better to use a consistent pattern throughout the file.
AFAICT from the git history, what happened is that the gtk demos rely on
gtk being built with pixman support. pkg-config isn't really expressive
enough to have that information, so the solution that was come up with
was to search for pixman as well as gtk+ and hope that pixman being
installed was.
This isn't actually used anywhere in the meson build anyway, and it's
causing problems for projects that want to use pixman as a supproject
(there's a port of cairo underway that's hitting this), because it
confuses meson.
Add option to include cpu-features.[ch] from a given path
into the build for platforms that don't provide this out
of the box. This is needed on Android.
Reviewed-by: Dylan Baker <dylan@pnwbakers.com>
This should resolve https://gitlab.freedesktop.org/pixman/pixman/-/issues/22
and make the tests pass with clang.
-ftrapping-math is already the default[1] for gcc, so this should not change
behavior when compiling with gcc. However, clang defaults[2] to -fno-trapping-math,
so -ftrapping-math is needed to avoid floating-point expceptions when running the
combiner and stress tests.
The root causes of this issue is that that pixman-combine-float.c guards floating-point
division operations with a FLOAT_IS_ZERO check e.g.
if (FLOAT_IS_ZERO (sa))
f = 1.0f;
else
f = CLAMP (da / sa);
With -fno-trapping-math, the compiler assumes that division will never trap, so it may
re-order the division and the guard and execute the division first. In most cases,
this would not be an issue, because floating-point exceptions are ignored. However,
these tests call enable_divbyzero_exceptions() which causes the SIGFPE signal to
be sent to the program when a divide by zero exception is raised.
[1] https://gcc.gnu.org/onlinedocs/gcc/Optimize-Options.html
[2] https://clang.llvm.org/docs/UsersManual.html#controlling-floating-point-behavior
The expansion of PIXMAN_DEFINE_THREAD_LOCAL(...) may end in a
function definition, so the following semicolon is considered an
empty top-level declaration, which is not allowed in ISO C.
Reviewed-by: Matt Turner <mattst88@gmail.com>
We want a uint8_t * at the end of this math, because that's what the
function we're about to pass it to takes. But ->bits is a uint32_t, so
if we just do the math in units of that we can avoid the explicit factor
of four which would risk an integer overflow.
Fixes: pixman/pixman#14
MinGW supports __declspec(dllexport) but the current logic that sets
PIXMAN_EXPORT only uses it when building with MSVC, leaving some symbols
hidden when building with MinGW.
This results in an error when trying to link the tests:
-----------------------------------------------------------------------
FAILED: subprojects/pixman/test/combiner-test.exe
x86_64-w64-mingw32-gcc -o subprojects/pixman/test/combiner-test.exe 'subprojects/pixman/test/f48fa9c@@combiner-test@exe/combiner-test.c.obj' -Wl,--allow-shlib-undefined -Wl,--start-group subprojects/pixman/test/libtestutils.a subprojects/pixman/pixman/libpixman-1.dll.a -pthread -fopenmp -fopenmp -lm -mconsole -lkernel32 -luser32 -lgdi32 -lwinspool -lshell32 -lole32 -loleaut32 -luuid -lcomdlg32 -ladvapi32 -Wl,--end-group
/usr/bin/x86_64-w64-mingw32-ld: subprojects/pixman/test/f48fa9c@@combiner-test@exe/combiner-test.c.obj: in function `main':
.../build/../subprojects/pixman/test/combiner-test.c:124: undefined reference to `_pixman_internal_only_get_implementation'
collect2: error: ld returned 1 exit status
ninja: build stopped: subcommand failed.
-----------------------------------------------------------------------
By using PIXMAN_API also when building with MinGW, the tests can link
successfully and the build succeed.
Tested with x86_64-w64-mingw32-gcc (GCC) 8.3-win32 20191201.
...When we don't have a pthreads implementation available, which is
normally the case on Windows. This attempts to make it easier for people
on Windows to verify whether their builds of Pixman (and Cairo component,
if applicable) are thread-safe. Also, make the number of threads
a #define, so if we need to change it at some point, it's easier.
This re-enables the thread-test program on Windows in Meson builds.
Define the existing PIXMAN_EXPORT to be PIXMAN_API, which can overriden
to be __declspec(dllexport) during the build of the pixman DLL on MSVC
builds, which will be in the next patch.
Also, export more private symbols as they are needed for the test
programs.
This prepares to mark the public APIs that we have in pixman.h so that
we can use compiler directives such as __declspec(dllexport) to export
those symbols.
The build system for libpng for MSVC does not generate a pkg-config file
for us, and CMake support in Meson does not work very well. So, look
for libpng manually on MSVC builds if depedency discovery did not work
out via pkg-config or the CMake config files.
Look also for pthread.h if threading support is found by Meson, as the
underlying threading support may not be PThreads, depending on platform.
For now, disable the thread-test test program if pthread.h and if
necessary, the PThreads library, cannot be found, as the current
implementation assumes the use of PThreads.
Also bump the required Meson version to 0.50.0 since we need it for
-cc.get_argument_syntax()
-For a later commit, the has_headers sub-method for cc.find_library()
The implementation of OpenMP is not compliant for our uses, so disable
it for now by just not checking for it on MSVC builds, as we implicitly
add an /openmp switch to the build, which will cause linking the tests
programs to fail, as the OpenMP implementation is not enough.
-For MSVC builds, do not use the GCC-specific CFlags when checking for
these features.
-For the MMX check, assume that we have good enough MMX intrinsics and
inline assembly support (on ix86), since MSVC provides sufficient
support for those since before the times of MSVC 2008, and 2008 is the
oldest version that we can support, as with the pre-C99 GTK+ stack.
Unfortunately due to x64 compiler issues, pre-Visual Studio 2010 will
crash when building SSSE3 code, so we do not enable building SSSE3 code
on pre-2010 Visual Studio.
Also, for all x64 Visual Studio builds, we do not enable USE_X86_MMX
as inline assembly is not allowed for x64 Visual Studio builds, and
instead use the compatibility instrinsics that we already have in the
code.
Does not make the test pass, but does fix this error:
../test/stress-test.c:538:25: runtime error: signed integer overflow: 2147483647 - -2 cannot be represented in type 'int'
../pixman/pixman-combine32.c:657:1: runtime error: left shift of 128 by 24 places cannot be represented in type 'int'
../pixman/pixman-combine32.c:694:1: runtime error: left shift of 232 by 24 places cannot be represented in type 'int'
../pixman/pixman-combine32.c:712:1: runtime error: left shift of 255 by 24 places cannot be represented in type 'int'
../pixman/pixman-combine32.c:786:1: runtime error: left shift of 255 by 24 places cannot be represented in type 'int'
../pixman/pixman-combine32.c:805:1: runtime error: left shift of 255 by 24 places cannot be represented in type 'int'
../pixman/pixman-access.c:389:2: runtime error: left shift of 1 by 31 places cannot be represented in type 'int'
../pixman/pixman-access.c:1101:2: runtime error: left shift of 2 by 30 places cannot be represented in type 'int'
../pixman/pixman-access.c:1152:2: runtime error: left shift of 2 by 30 places cannot be represented in type 'int'
Reported in https://bugzilla.mozilla.org/show_bug.cgi?id=1580352. Casting the argument to uint32_t should avoid invoking undefined behavior here. We'll still have *implementation-defined* behavior when casting the result back to pixman_fixed_t, but that's better than *undefined*.
Meson doesn't do the expected thing when library() creates a static
library. Instead of combining the libraries together into a single
archive it effectively discards them, resulting in missing symbols.
To work around this we manually unpack the archives and shove the .o
files into the final library. This doesn't affect the shared library at
all, but makes the static library have the necessary symbols
Fixes#33
To avoid potential signed integer overflow (undefined behavior), as implicit integer promotion means the operand becomes a (signed) int.
(Issue originally reported at https://bugzilla.mozilla.org/show_bug.cgi?id=1577669)
GCC on Windows complains that "__declspec(thread)" doesn't work, but still
compiles it, so the meson check doesn't work. The warning printed by gcc:
"warning: 'thread' attribute directive ignored [-Wattributes]"
Pass -Werror=attributes to make the check fail instead.
This fixes the test suite (minus gtk tests) on Windows with mingw.
So that passing "-Ddefault_library=both" also creates a static lib.
Note that Libs.private in the .pc file will still be wrong because of
https://github.com/mesonbuild/meson/issues/3934 (it contains things like
-lpixman-mmx)
The dithering code (specifically `dither_factor_bayer_8`) uses a GNU
extension for binary notation, eg 0b001. This is not supported by MSVC
(at least) and breaks the build on this platform [1].
This patches uses hexadecimal notation instead, fixing the build.
[1]: https://lists.freedesktop.org/archives/pixman/2019-June/004883.html
Reviewed-by: Matt Turner <mattst88@gmail.com>
On some screens (typically low quality laptop screens), using Bayer
ordered dithering has been observed to cause color changes depending on
*where the gradient is rendered on the screen*, causing visible
flickering when moving an image on the screen.
To alleviate the issue, this patch adds support for ordered dithering
using a 64x64 matrix tuned from blue noise. In addition to being devoid
of the positional dependency on screen, the blue noise matrix also
generates more pleasing and less discernable patterns. As such, it is
now the method used for PIXMAN_DITHER_GOOD and PIXMAN_DITHER_BEST
dithering methods.
The 64x64 blue noise matrix has been generated using the provided
`pixman/dither/make-blue-noise.c` script, which uses the
void-and-cluster method.
Changes since v1 (thanks Bill):
- Use uint16_t for the blue noise matrix for lower memory usage
- Use bitwise computation for array index
This adds a dither.c which provides a demo of the dithering feature.
This is based on the scale.c demo for scaling and provides a selection
of intermediate formats and dithering operators (currently, only
PIXMAN_DITHER_ORDERED_BAYER_8) to use. Images are first blitted onto a
surface of the intermediate format with the requested dither setup, then
blitted back onto a a8r8g8b8 surface for display.
This adds support for testing dithered destinations in tolerance-test.
When dithering is enabled, the pixel checker allows for an additional
quantization error.
This patch implements dithering in pixman. A "dither" property is added
to BITS images, which is used to:
- Force rendering to the image to go through the floating point
pipeline. Note that this is different from FAST_PATH_NARROW_FORMAT
as it should not enable the floating point pipeline when reading from
the image.
- Enable dithering in dest_write_back_wide. The dithering uses the
destination format to determine noise amplitude.
This does not change pixman's behavior when dithering is disabled (the
default).
Additional types and functions are added to the public API:
- The `pixman_dither_t` enum exposes the available dithering methods.
Currently a single dithering method based on 8x8 Bayer matrices is
implemented (PIXMAN_DITHER_ORDERED_BAYER_8). The PIXMAN_DITHER_FAST,
PIXMAN_DITHER_GOOD and PIXMAN_DITHER_BEST aliases are provided and
should be used to benefit from future specializations.
- The `pixman_image_set_dither` function allows to set the dithering
method to use when rendering to a bits image.
- The `pixman_image_set_dither_offset` function allows to set a
vertical and horizontal offsets for the dither matrix. This can be
used after scrolling to ensure a consistent spatial positioning of
the dither matrix.
Changes since previous version (v2):
- linear_gradient_is_horizontal optimization is still compatible with
the wide pipeline. The code disabling it was a remnant of a previous
patch which performed dithering directly inside linear_get_scanline,
and thus needed to be called independently for each scanline.
Changes since v1:
- Renamed PIXMAN_DITHER_BAYER_8 to PIXMAN_DITHER_ORDERED_BAYER_8
- Disable dithering for channels with 32bpp or more (since they can
represent exactly the wide values already). This makes the patches
compatible with the newly added floating point format.
Dithering is compatible with linear_gradient_is_horizontal
The recently introduced wide pipeline for filters has a typo which
causes it to improperly compute bilinear interpolation positions,
causing various glitches when enabled.
This patch uses the proper computation for bilinear interpolation in the
wide pipeline. It also makes related `if` statements conformant to the
CODING_STYLE:
* If a substatement spans multiple lines, then there must be braces
around it.
* If one substatement of an if statement has braces, then the other
must too.
Signed-off-by: Maarten Lankhorst <maarten.lankhorst@linux.intel.com>
These were forgotten in commit 0ea37df428 (meson: store ARM SIMD and
NEON tests as text files) and since autotools doesn't use them make
distcheck still succeeded.
Fixes#30
Signed-off-by: Matt Turner <mattst88@gmail.com>
This is unfortunately required to make the tests work correctly, as
otherwise meson assumes that the files are C code not assembly. I've
opened https://github.com/mesonbuild/meson/issues/5151, to discuss
fixing the issue in meson upstream.
Fixes#29
This issue causes openmp arguments to be injected into compilers that
can support openmp, even if they don't. This issue will be fixed in
0.51 (code already landed in mesonbuild#5116), for older versions lets
work around the issue.
pixman-bits-image's wide helpers first obtains the 8-bits image,
then converts it to float. This destroys all the precision that
the wide path was offering.
Fix this by making get_pixel() take a pointer instead of returning
a value. Floating point will fill in a argb_t, while the 8-bits path
will fill a 32-bits ARGB value. This also requires writing a floating
point bilinear interpolator. With this change pixman can use the full
floating point precision internally in all paths.
Changes since v1:
- Make accum and reduce an argument to convolution functions,
to remove duplication.
Signed-off-by: Maarten Lankhorst <maarten.lankhorst@linux.intel.com>
Acked-by: Basile Clement <basile-pixman@clement.pm>
This patch modifies the gradient walker to be able to generate floating
point values directly in addition to a8r8g8b8 32 bit values. This is
then used by the various gradient implementations to render in floating
point when asked to do so, instead of rendering to a8r8g8b8 and then
expanding to floating point as they were doing previously.
Changes since v1 (mlankhorst):
- Implement pixman_gradient_walker_pixel_32 without calling
pixman_gradient_walker_pixel_float, to prevent performance degradation.
Suggested by Adam Jackson.
- Fix whitespace errors.
- Remove unnecessary function prototypes in pixman-private.h
Signed-off-by: Maarten Lankhorst <maarten.lankhorst@linux.intel.com>
[mlankhorst: Add comment about pixman_contract_from_float,
based on Basille's suggestion]
Acked-by: Basile Clement <basile-pixman@clement.pm>
This commit adds a meson build system for pixman. It carries the usual
improvements of meson, better clean build time, much better incremental
build times, while being simpler and easier to understand.
This takes advantage of some features from the most recent versions of
meson: the builtin openmp dependency and the feature option type.
There are a couple of things that I've done a bit differently than the
autotools build system, I've built a libdemos which is the utilities
from the demos folder, and I've linked the demos with libtestutils from
tetsts, otherwise I expect that most things will be the same.
I've tested so far cross compiling from x86_64 -> x86, x86_64 ->
Aarch64, and Linux to Windows via mingw, as well as native x86_64 Linux
builds which all work. I've also built with mingw nativly, there are
some test failures there. An MSVC build can be generated, but fails.
v2: - set WORDS_BIGENDIAN in the config for big endian systems.
Add some basic tests to ensure that the newly added formats work as
intended.
Signed-off-by: Maarten Lankhorst <maarten.lankhorst@linux.intel.com>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
Pixman is already using the floating point formats internally, expose
this capability in case someone wants to support higher bit per
component formats.
This is useful for igt which depends on cairo to do the rendering.
It can use it to convert floats internally to planar Y'CbCr formats,
or to F16.
We add a new type PIXMAN_TYPE_RGBA_FLOAT for this format, which is an
all float array of R, G, B, and A. Formats that use mixed float/int
RGBA aren't supported, and will probably need their own type.
Changes since v1:
- Use RGBA 128 bits and RGB 96 bits memory layouts, to better match the opengl format.
Changes since v2:
- Add asserts in accessor and for strides to force alignment.
- Move test changes to their own commit.
Changes since v3:
- Define 32bpc as PIXMAN_FORMAT_PACKED_C32
- Rename pixman accessors from rgb*_float_float to rgb*f_float
Changes since v4:
- Create a new PIXMAN_FORMAT_BYTE for fitting up to 64 bits per component.
(based on Siarhei Siamashka's suggestion)
- Use new format type PIXMAN_TYPE_RGBA_FLOAT
Signed-off-by: Maarten Lankhorst <maarten.lankhorst@linux.intel.com>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk> #v4
[mlankhorst: Fix missing braces in PIXMAN_FORMAT_RESHIFT macro]
Currently the number of bits per pixel is used instead of the
number of bytes per pixel when calculating image strides. This
does not cause any real problems, but the gaps between scanlines
are excessively large.
This patch actually converts bits to bytes and rounds up the result
to the nearest byte boundary.
Signed-off-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
Reviewed-by: soren.sandmann@gmail.com
__builtin_shuffle was removed in clang 5.0.
Build log says:
test/utils-prng.c:207:27: error: use of unknown builtin '__builtin_shuffle' [-Wimplicit-function-declaration]
randdata.vb = __builtin_shuffle (randdata.vb, bswap_shufflemask);
^
test/utils-prng.c:207:25: error: assigning to 'uint8x16' (vector of 16 'uint8_t' values) from incompatible type 'int'
randdata.vb = __builtin_shuffle (randdata.vb, bswap_shufflemask);
^ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
2 errors generated
Link to original discussion:
http://lists.llvm.org/pipermail/cfe-dev/2017-August/055140.html
It's possible to build pixman if attached patch is applied. Basically
patch adds check for __builtin_shuffle support and in case there is
none, falls back to clang-specific __builtin_shufflevector that do the
same but have different API.
Bugzilla: https://bugs.gentoo.org/646360
Bugzilla: https://bugs.freedesktop.org/show_bug.cgi?id=104886
Tested-by: Philip Chimento <philip.chimento@gmail.com>
Reviewed-by: Matt Turner <mattst88@gmail.com>
Reviewed-by: Adam Jackson <ajax@redhat.com>
Just builds on Fedora 28 for x86_64 at the moment, but it's a start.
Credit to Daniel Stone for eliminating the nested docker image.
Signed-off-by: Adam Jackson <ajax@redhat.com>
Use vector intrinsic for loading possibly unaligned data instead of a
typecast.
Bugzilla: https://bugzilla.redhat.com/1572540
Signed-off-by: Dan Horák <dan@danny.cz>
Signed-off-by: Adam Jackson <ajax@redhat.com>
Tested-by: Matt Turner <mattst88@gmail.com>
Reviewed-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
Expanded the size slightly (from ~4.25 to 5) to make the cutoff less
noticable. Previouly the value at the cutoff was
gaussian_filter(sqrt(2)*3/2) = 0.00626 which is larger than the
difference between 8-bit pixels (1/255 = 0.003921). New cutoff is
gaussian_filter(2.5) = 0.001089 which is smaller.
v11: added some math to commit message
v14: left SIGMA in there
Signed-off-by: Bill Spitzak <spitzak@gmail.com>
Acked-by: Oded Gabbay <oded.gabbay@gmail.com>
Reviewed-by: Søren Sandmann <soren.sandmann@gmail.com>
There are a few bugs in the current normalization code
(1) The normalization is based on the sum of the *floating point*
values generated by integral(). But in order to get the sum to be
close to pixman_fixed_1, the sum of the rounded fixed point values
should be used.
(2) The multiplications in the normalization loops often round the
same way, so the residual error can fairly large.
(3) The residual error is added to the sample located at index
(width - width / 2), which is not the midpoint for odd widths (and
for width 1 is in fact outside the array).
This patch fixes these issues by (1) using the sum of the fixed point
values as the total to divide by, (2) doing error diffusion in the
normalization loop, and (3) putting any residual error (which is now
guaranteed to be less than pixman_fixed_e) at the first sample, which
is the only one that didn't get any error diffused into it.
Signed-off-by: Søren Sandmann <soren.sandmann@gmail.com>
The convolution of two BOX filters is simply the length of the
interval where both are non-zero, so we can simply return width from
the integral() function because the integration region has already
been restricted to be such that both functions are non-zero on it.
This is both faster and more accurate than doing numerical integration.
This patch is based on one by Bill Spitzak
https://lists.freedesktop.org/archives/pixman/2016-March/004446.html
with these changes:
- Rebased to not assume any changes in the arguments to integral().
- Dropped the multiplication by scale
- Added more details in the commit message.
Signed-off-by: Søren Sandmann <soren.sandmann@gmail.com>
Reviewed-by: Bill Spitzak <spitzak@gmail.com>
Only the triangle is discontinuous at 0. The other filters resemble a
cubic closely enough that Simpsons integration works without
splitting.
Changes by Søren: Rebase without the changes to the integral function,
update comment to match the new code.
Signed-off-by: Bill Spitzak <spitzak@gmail.com>
Signed-off-by: Søren Sandmann <soren.sandmann@gmail.com>
Reviewed-by: Søren Sandmann <soren.sandmann@gmail.com>
Simpsons uses cubic curve fitting, with 3 samples defining each
cubic. This makes the weights of the samples be in a pattern of
1,4,2,4,2...4,1, and then dividing the result by 3.
The previous code was using weights of 1,2,0,6,0,6...,2,1.
With this fix the integration is accurate enough that the number of
samples could be reduced a lot. Multiples of 12 seem to work best.
v7: Merged with patch to reduce from 128 samples to 16
v9: Changed samples from 16 to 12
v10: Fixed rebase error that made it not compile
v11: minor whitespace change
v14: more whitespace changes
Signed-off-by: Bill Spitzak <spitzak@gmail.com>
Reviewed-by: Oded Gabbay <oded.gabbay@gmail.com>
Reviewed-by: Søren Sandmann <soren.sandmann@gmail.com>
Rearranged so that the entire block of memory for the filter pair
is allocated first, and then filled in. Previous version allocated
and freed two temporary buffers for each filter and did an extra
memcpy.
v8: small refactor to remove the filter_width function
v10: Restored filter_width function but with arguments changed to
match later patches
v11: Removed unused arg and pointer from filter_width function
Whitespace fixes.
Signed-off-by: Bill Spitzak <spitzak@gmail.com>
Reviewed-by: Oded Gabbay <oded.gabbay@gmail.com>
Acked-by: Søren Sandmann <soren.sandmann@gmail.com>
If enable-gnuplot is configured, then you can pipe the output of a
pixman-using program to gnuplot and get a continuously-updated plot of
the horizontal filter. This works well with demos/scale to test the
filter generation.
The plot is all the different subposition filters shuffled
together. This is misleading in a few cases:
IMPULSE.BOX - goes up and down as the subfilters have different
numbers of non-zero samples
IMPULSE.TRIANGLE - somewhat crooked for the same reason
1-wide filters - looks triangular, but a 1-wide box would be more
accurate
Changes by Søren: Rewrote the pixman-filter.c part to
- make it generate correct coordinates
- add a comment on how coordinates are generated
- in rounding.txt, add a ceil() variant of the first-sample
formula
- make the gnuplot output slightly prettier
v7: First time this ability was included
v8: Use config option
Moved code to the filter generator
Modified scale demo to not call filter generator a second time.
v10: Only print if successful generation of plots
Use #ifdef, not #if
v11: small whitespace fixes
v12: output range from -width/2 to width/2 and include y==0, to avoid misleading plots
for subsample_bits==0 and for box filters which may have no small values.
Signed-off-by: Bill Spitzak <spitzak@gmail.com>
This is very useful for comparing the results of SEPARABLE_CONVOLUTION
with BILINEAR and NEAREST.
v14: Removed good/best items
v15: Skip filter generation so gnuplot output continues showing previous value
Signed-off-by: Bill Spitzak <spitzak@gmail.com>
Reviewed-by: Oded Gabbay <oded.gabbay@gmail.com>
It now shows the initial value of 4 when the demo is started
Signed-off-by: Bill Spitzak <spitzak@gmail.com>
Reviewed-by: Søren Sandmann <soren.sandmann@gmail.com>
Instead of using the boundary of xformed rectangle, use the boundary
of xformed ellipse. This is much more accurate and less blurry. In
particular the filtering does not change as the image is rotated.
Signed-off-by: Bill Spitzak <spitzak@gmail.com>
Reviewed-by: Oded Gabbay <oded.gabbay@gmail.com>
Reviewed-by: Soren Sandmann <soren.sandmann@gmail.com>
Generalize and simplify the code that reduces BILINEAR to NEAREST so
that the reduction happens for all affine transformations where
t00...t12 are integers and (t00 + t01) and (t10 + t11) are both
odd. This is a sufficient condition for the resulting transformed
coordinates to be exactly at the center of a pixel so that BILINEAR
becomes identical to NEAREST.
V2: Address some comments by Bill Spitzak
Signed-off-by: Søren Sandmann <soren.sandmann@gmail.com>
Reviewed-by: Bill Spitzak <spitzak@gmail.com>
This new test tests a bunch of bilinear downscalings, where many have
a transformation such that the BILINEAR filter can be reduced to
NEAREST (and many don't).
A CRC32 is computed for all the resulting images and compared to a
known-good value for both 4-bit and 7-bit interpolation.
V2: Remove leftover comment, some minor formatting fixes, use a
timestamp as the PRNG seed.
Signed-off-by: Søren Sandmann <soren.sandmann@gmail.com>
Reviewed-by: Bill Spitzak <spitzak@gmail.com>
When a BILINEAR filter is reduced to NEAREST, it is possible for both
types of fast paths to run; in this case, the NEAREST ones should be
preferred as that is the simpler filter.
Signed-off-by: Soren Sandmann <soren.sandmann@gmail.com>
Reviewed-by: Bill Spitzak <spitzak@gmail.com>
<float.h> is included unconditionally by pixman-private.h, which in
turn gets included by assembler files. Unfortunately, with certain C
libraries (like the musl C library), <float.h> cannot be included in
assembler files:
CCLD libpixman-arm-simd.la
/home/test/buildroot/output/host/usr/arm-buildroot-linux-musleabihf/sysroot/usr/include/float.h: Assembler messages:
/home/test/buildroot/output/host/usr/arm-buildroot-linux-musleabihf/sysroot/usr/include/float.h:8: Error: bad instruction `int __flt_rounds(void)'
/home/test/buildroot/output/host/usr/arm-buildroot-linux-musleabihf/sysroot/usr/include/float.h: Assembler messages:
/home/test/buildroot/output/host/usr/arm-buildroot-linux-musleabihf/sysroot/usr/include/float.h:8: Error: bad instruction `int __flt_rounds(void)'
It turns out however that <float.h> is not needed by assembly files,
so we move its inclusion within the #ifndef __ASSEMBLER__ condition,
which solves the problem.
Signed-off-by: Thomas Petazzoni <thomas.petazzoni@free-electrons.com>
Reviewed-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
The `check` target in test/Makefile.win32 assumed that any non-0 exit
code from the tests was an error, but the testsuite is currently using
77 as a SKIP exit code (based on the convention used in autotools).
Fixes fence-image-self-test and cover-test (now reported as SKIP).
Signed-off-by: Andrea Canciani <ranma42@gmail.com>
Acked-by: Oded Gabbay <oded.gabbay@gmail.com>
The `rm` command is not usually available when running on Win32 in a
`cmd.exe` shell. Instead the shell provides the `del` builtin, which
has somewhat more limited wildcars expansion and error handling.
This makes all of the Makefile targets work on Win32 both using
`cmd.exe` and using the MSYS environment.
Signed-off-by: Simon Richter <Simon.Richter@hogyros.de>
Signed-off-by: Andrea Canciani <ranma42@gmail.com>
Acked-by: Oded Gabbay <oded.gabbay@gmail.com>
When the build is performed using `cmd.exe` as shell, the `mkdir`
command does not support the `-p` flag. The ability to create multiple
netsted folder is not used, hence it can be easily replaced by only
creating the directory if it does not exist.
This makes the build work on the `cmd.exe` shell, except for the
`clean` targets.
Signed-off-by: Andrea Canciani <ranma42@gmail.com>
Acked-by: Oded Gabbay <oded.gabbay@gmail.com>
Instead of explicitly depending on "pixman" for the "all" and "check"
targets, rely on the dependency to the .lib file
Signed-off-by: Andrea Canciani <ranma42@gmail.com>
Reviewed-by: Oded Gabbay <oded.gabbay@gmail.com>
Since 3d81d89c29 BUILT_SOURCES is not
used anymore, but it was unintentionally left in Win32 Makefiles.
Signed-off-by: Andrea Canciani <ranma42@gmail.com>
Reviewed-by: Oded Gabbay <oded.gabbay@gmail.com>
This patch modifies the SSE2 & SSSE3 tests in configure.ac to use a
global variable to initialize vector variables. In addition, we now
return the value of the computation instead of 0.
This is done so gcc 4.9 (and lower) won't optimize the SSE assembly
instructions (when using -O1 and higher), because then the configure test
might incorrectly pass even though the assembler doesn't support the
SSE instructions (the test will pass because the compiler does support
the intrinsics).
v2: instead of using volatile, use a global variable as input
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Older versions of clang emitted an error on the "K" constraint, but at
least since version 3.7 it is supported. Just like gcc, this
constraint is only allowed for constants, but apparently clang
requires them to be known before inlining.
Using the macro definition _mm_shuffle_pi16(A, N) ensures that the "K"
constraint is always applied to a literal constant, independently from
the compiler optimizations and allows building pixman-mmx on modern
clang.
Reviewed-by: Matt Turner <mattst88@gmail.com>
Signed-off-by: Andrea Canciani <ranma42@gmail.com>
On MacOS X, according to the manpage of mprotect(), "When a program
violates the protections of a page, it gets a SIGBUS or SIGSEGV
signal.", but fence-image-self-test was only accepting a SIGSEGV as
notification of invalid access.
Fixes fence-image-self-test
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
We had lots of hacks to handle the inability to include xmmintrin.h
without compiling with -msse (lest SSE instructions be used in
pixman-mmx.c). Some recent version of gcc relaxed this restriction.
Change configure.ac to test that xmmintrin.h can be included and that we
can use some intrinsics from it, and remove the work-around code from
pixman-mmx.c.
Evidently allows gcc 4.9.3 to optimize better as well:
text data bss dec hex filename
657078 30848 680 688606 a81de libpixman-1.so.0.33.3 before
656710 30848 680 688238 a806e libpixman-1.so.0.33.3 after
Reviewed-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
Tested-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Signed-off-by: Matt Turner <mattst88@gmail.com>
Patch "Remove the 8e extra safety margin in COVER_CLIP analysis" reduced
the required image area for setting the COVER flags in
pixman.c:analyze_extent(). Do the same reduction in affine-bench.
Leaving the old calculations in place would be very confusing for anyone
reading the code.
Also add a comment that explains how affine-bench wants to hit the COVER
paths. This explains why the intricate extent calculations are copied
from pixman.c.
[Pekka: split patch, change comments, write commit message]
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
As discussed in
http://lists.freedesktop.org/archives/pixman/2015-August/003905.html
the 8 * pixman_fixed_e (8e) adjustment which was applied to the transformed
coordinates is a legacy of rounding errors which used to occur in old
versions of Pixman, but which no longer apply. For any affine transform,
you are now guaranteed to get the same result by transforming the upper
coordinate as though you transform the lower coordinate and add (size-1)
steps of the increment in source coordinate space. No projective
transform routines use the COVER_CLIP flags, so they cannot be affected.
Proof by Siarhei Siamashka:
Let's take a look at the following affine transformation matrix (with 16.16
fixed point values) and two vectors:
| a b c |
M = | d e f |
| 0 0 0x10000 |
| x_dst |
P = | y_dst |
| 0x10000 |
| 0x10000 |
ONE_X = | 0 |
| 0 |
The current matrix multiplication code does the following calculations:
| (a * x_dst + b * y_dst + 0x8000) / 0x10000 + c |
M * P = | (d * x_dst + e * y_dst + 0x8000) / 0x10000 + f |
| 0x10000 |
These calculations are not perfectly exact and we may get rounding
because the integer coordinates are adjusted by 0.5 (or 0x8000 in the
16.16 fixed point format) before doing matrix multiplication. For
example, if the 'a' coefficient is an odd number and 'b' is zero,
then we are losing some of the least significant bits when dividing by
0x10000.
So we need to strictly prove that the following expression is always
true even though we have to deal with rounding:
| a |
M * (P + ONE_X) - M * P = M * ONE_X = | d |
| 0 |
or
((a * (x_dst + 0x10000) + b * y_dst + 0x8000) / 0x10000 + c)
-
((a * x_dst + b * y_dst + 0x8000) / 0x10000 + c)
=
a
It's easy to see that this is equivalent to
a + ((a * x_dst + b * y_dst + 0x8000) / 0x10000 + c)
- ((a * x_dst + b * y_dst + 0x8000) / 0x10000 + c)
=
a
Which means that stepping exactly by one pixel horizontally in the
destination image space (advancing 'x_dst' by 0x10000) is the same as
changing the transformed 'x_src' coordinate in the source image space
exactly by 'a'. The same applies to the vertical direction too.
Repeating these steps, we can reach any pixel in the source image
space and get exactly the same fixed point coordinates as doing
matrix multiplications per each pixel.
By the way, the older matrix multiplication implementation, which was
relying on less accurate calculations with three intermediate roundings
"((a + 0x8000) >> 16) + ((b + 0x8000) >> 16) + ((c + 0x8000) >> 16)",
also has the same properties. However reverting
http://cgit.freedesktop.org/pixman/commit/?id=ed39992564beefe6b12f81e842caba11aff98a9c
and applying this "Remove the 8e extra safety margin in COVER_CLIP
analysis" patch makes the cover test fail. The real reason why it fails
is that the old pixman code was using "pixman_transform_point_3d()"
function
http://cgit.freedesktop.org/pixman/tree/pixman/pixman-matrix.c?id=pixman-0.28.2#n49
for getting the transformed coordinate of the top left corner pixel
in the image scaling code, but at the same time using a different
"pixman_transform_point()" function
http://cgit.freedesktop.org/pixman/tree/pixman/pixman-matrix.c?id=pixman-0.28.2#n82
in the extents calculation code for setting the cover flag. And these
functions did the intermediate rounding differently. That's why the 8e
safety margin was needed.
** proof ends
However, for COVER_CLIP_NEAREST, the actual margins added were not 8e.
Because the half-way cases round down, that is, coordinate 0 hits pixel
index -1 while coordinate e hits pixel index 0, the extra safety margins
were actually 7e to the left and up, and 9e to the right and down. This
patch removes the 7e and 9e margins and restores the -e adjustment
required for NEAREST sampling in Pixman. For reference, see
pixman/rounding.txt.
For COVER_CLIP_BILINEAR, the margins were exactly 8e as there are no
additional offsets to be restored, so simply removing the 8e additions
is enough.
Proof:
All implementations must give the same numerical results as
bits_image_fetch_pixel_nearest() / bits_image_fetch_pixel_bilinear().
The former does
int x0 = pixman_fixed_to_int (x - pixman_fixed_e);
which maps directly to the new test for the nearest flag, when you consider
that x0 must fall in the interval [0,width).
The latter does
x1 = x - pixman_fixed_1 / 2;
x1 = pixman_fixed_to_int (x1);
x2 = x1 + 1;
When you write a COVER path, you take advantage of the assumption that
both x1 and x2 fall in the interval [0, width).
As samplers are allowed to fetch the pixel at x2 unconditionally, we
require
x1 >= 0
x2 < width
so
x - pixman_fixed_1 / 2 >= 0
x - pixman_fixed_1 / 2 + pixman_fixed_1 < width * pixman_fixed_1
so
pixman_fixed_to_int (x - pixman_fixed_1 / 2) >= 0
pixman_fixed_to_int (x + pixman_fixed_1 / 2) < width
which matches the source code lines for the bilinear case, once you delete
the lines that add the 8e margin.
Signed-off-by: Ben Avison <bavison@riscosopen.org>
[Pekka: adjusted commit message, left affine-bench changes for another patch]
[Pekka: add commit message parts from Siarhei]
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Each of the aligns can only add a maximum of 15 bytes to the space
requirement. This permits some edge cases to use the stack buffer where
previously it would have deduced that a heap buffer was required.
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
As https://bugs.freedesktop.org/show_bug.cgi?id=92027#c6 explains,
the stack is allocated at the very top of the process address space
in some configurations (32-bit x86 systems with ASLR disabled).
And the careless computations done with the 'dest_buffer' pointer
may overflow, failing the buffer upper limit check.
The problem can be reproduced using the 'stress-test' program,
which segfaults when executed via setarch:
export CFLAGS="-O2 -m32" && ./autogen.sh
./configure --disable-libpng --disable-gtk && make
setarch i686 -R test/stress-test
This patch introduces the required corrections. The extra check
for negative 'width' may be redundant (the invalid 'width' value
is not supposed to reach here), but it's better to play safe
when dealing with the buffers allocated on stack.
Reported-by: Ludovic Courtès <ludo@gnu.org>
Signed-off-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
Reviewed-by: soren.sandmann@gmail.com
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Some architectures, such as Microblaze and Nios2, currently do not
implement FE_DIVBYZERO, even though they have <fenv.h> and
feenableexcept(). This commit adds a configure.ac check to verify
whether FE_DIVBYZERO is defined or not, and if not, disables the
problematic code in test/utils.c.
Signed-off-by: Thomas Petazzoni <thomas.petazzoni@free-electrons.com>
Signed-off-by: Marek Vasut <marex@denx.de>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Now that we replaced the expensive functions with better performing
alternatives, we should remove them so they will not be used again.
Running Cairo benchmark on trimmed traces gave the following results:
POWER8, 8 cores, 3.4GHz, RHEL 7.2 ppc64le.
Speedups
========
t-firefox-scrolling 1232.30 -> 1096.55 : 1.12x
t-gnome-terminal-vim 613.86 -> 553.10 : 1.11x
t-evolution 405.54 -> 371.02 : 1.09x
t-firefox-talos-gfx 919.31 -> 862.27 : 1.07x
t-gvim 653.02 -> 616.85 : 1.06x
t-firefox-canvas-alpha 941.29 -> 890.42 : 1.06x
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Acked-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
This patch optimizes vmx_composite_over_n_8888_8888_ca by removing use
of expand_alpha_1x128, unpack/pack and in_over_2x128 in favor of
splat_alpha, in_over and MUL/ADD macros from pixman_combine32.h.
Running "lowlevel-blt-bench -n over_8888_8888" on POWER8, 8 cores,
3.4GHz, RHEL 7.2 ppc64le gave the following results:
reference memcpy speed = 23475.4MB/s (5868.8MP/s for 32bpp fills)
Before After Change
--------------------------------------------
L1 244.97 474.05 +93.51%
L2 243.74 473.05 +94.08%
M 243.29 467.16 +92.02%
HT 144.03 252.79 +75.51%
VT 174.24 279.03 +60.14%
R 109.86 149.98 +36.52%
RT 47.96 53.18 +10.88%
Kops/s 524 576 +9.92%
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Acked-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
This patch optimizes scaled_nearest_scanline_vmx_8888_8888_OVER and all
the functions it calls (combine1, combine4 and
core_combine_over_u_pixel_vmx).
The optimization is done by removing use of expand_alpha_1x128 and
expand_alpha_2x128 in favor of splat_alpha and MUL/ADD macros from
pixman_combine32.h.
Running "lowlevel-blt-bench -n over_8888_8888" on POWER8, 8 cores,
3.4GHz, RHEL 7.2 ppc64le gave the following results:
reference memcpy speed = 24847.3MB/s (6211.8MP/s for 32bpp fills)
Before After Change
--------------------------------------------
L1 182.05 210.22 +15.47%
L2 180.6 208.92 +15.68%
M 180.52 208.22 +15.34%
HT 130.17 178.97 +37.49%
VT 145.82 184.22 +26.33%
R 104.51 129.38 +23.80%
RT 48.3 61.54 +27.41%
Kops/s 430 504 +17.21%
v2: Check *pm is not NULL before dereferencing it in combine1()
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Acked-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
Enable the fast path added in the previous patch by moving the lookup
table entries to their proper locations.
Lowlevel-blt-bench benchmark statistics with 30 iterations, showing the
effect of adding this one patch on top of
"armv6: Add over_n_8888 fast path (disabled)", which was applied on
fd59569294.
Before After
Mean StdDev Mean StdDev Confidence Change
L1 12.5 0.04 45.2 0.10 100.00% +263.1%
L2 11.1 0.02 43.2 0.03 100.00% +289.3%
M 9.4 0.00 42.4 0.02 100.00% +351.7%
HT 8.5 0.02 25.4 0.10 100.00% +198.8%
VT 8.4 0.02 22.3 0.07 100.00% +167.0%
R 8.2 0.02 23.1 0.09 100.00% +183.6%
RT 5.4 0.05 11.4 0.21 100.00% +110.3%
At most 3 outliers rejected per test per set.
Iterating here means that lowlevel-blt-bench was executed 30 times, and
the statistics above were computed from the output.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
This new fast path is initially disabled by putting the entries in the
lookup table after the sentinel. The compiler cannot tell the new code
is not used, so it cannot eliminate the code. Also the lookup table size
will include the new fast path. When the follow-up patch then enables
the new fast path, the binary layout (alignments, size, etc.) will stay
the same compared to the disabled case.
Keeping the binary layout identical is important for benchmarking on
Raspberry Pi 1. The addresses at which functions are loaded will have a
significant impact on benchmark results, causing unexpected performance
changes. Keeping all function addresses the same across the patch
enabling a new fast path improves the reliability of benchmarks.
Benchmark results are included in the patch enabling this fast path.
[Pekka: disabled the fast path, commit message]
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
This test aims to verify both numerical correctness and the honouring of
array bounds for scaled plots (both nearest-neighbour and bilinear) at or
close to the boundary conditions for applicability of "cover" type fast paths
and iter fetch routines.
It has a secondary purpose: by setting the env var EXACT (to any value) it
will only test plots that are exactly on the boundary condition. This makes
it possible to ensure that "cover" routines are being used to the maximum,
although this requires the use of a debugger or code instrumentation to
verify.
Changes in v4:
Check the fence page size and skip the test if it is too large. Since
we need to deal with pixman_fixed_t coordinates that go beyond the
real image width, make the page size limit 16 kB. A 32 kB or larger
page size would cause an a8 image width to be 32k or more, which is no
longer representable in pixman_fixed_t.
Use a shorthand variable 'filter' in test_cover().
Whitespace adjustments.
Changes in v5:
Skip if fenced memory is not supported. Do you know of any such
platform?
Signed-off-by: Ben Avison <bavison@riscosopen.org>
[Pekka: changes in v4 and v5]
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Acked-by: Oded Gabbay <oded.gabbay@gmail.com>
Add a new option to PIXMAN_DISABLE: "wholeops". This option disables all
whole-operation fast paths regardless of implementation level, except
the general path (general_composite_rect).
The purpose is to add a debug option that allows us to test optimized
iterator paths specifically. With this, it is possible to see if:
- fast paths mask bugs in iterators
- compare fast paths with iterator paths for performance
The effect was tested on x86_64 by running:
$ PIXMAN_DISABLE='' ./test/lowlevel-blt-bench over_8888_8888
$ PIXMAN_DISABLE='wholeops' ./test/lowlevel-blt-bench over_8888_8888
In the first case time is spent in sse2_composite_over_8888_8888(), and
in the latter in sse2_combine_over_u().
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Oded Gabbay <oded.gabbay@gmail.com>
Add a function to get the page size used for memory fence purposes, and
use it everywhere where getpagesize() was used.
This offers a single point in code to override the page size, in case
one wants to experiment how the tests work with a higher page size than
what the developer's machine has.
This also offers a clean API, without adding #ifdefs, to tests for
checking the page size.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Oded Gabbay <oded.gabbay@gmail.com>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Used a wrong variable name, causing:
/home/pq/git/pixman/demos/../test/utils.c: In function ‘fence_image_create_bits’:
/home/pq/git/pixman/demos/../test/utils.c:562:46: error: ‘width’ undeclared (first use in this function)
Use the correct variable.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Oded Gabbay <oded.gabbay@gmail.com>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Quoting Simon again: "It currently has the same effect as hardening=+bindnow,
but will automatically enable future hardening options and in case the package
will ever build binaries those are immediately protected with PIE as well."
Signed-off-by: Andreas Boll <andreas.boll.dev@gmail.com>
Quoting Simon Ruderich <simon@ruderich.org>:
"There's no need to use dpkg-buildflags manually in debian/rules.
Debhelper with compat=9 automatically enables the hardening flags when
dh_auto_configure is used. So just by calling dh_auto_configure [...]
the hardening flags get automatically passed to the build system.
DEB_BUILD_MAINT_OPTIONS is also respected."
Signed-off-by: Andreas Boll <andreas.boll.dev@gmail.com>
Tests that fence_malloc and fence_image_create_bits actually work: that
out-of-bounds and out-of-row (unused stride area) accesses trigger
SIGSEGV.
If fence_malloc is a dummy (FENCE_MALLOC_ACTIVE not defined), this test
is skipped.
Changes in v2:
- check FENCE_MALLOC_ACTIVE value, not whether it is defined
- test that reading bytes near the fence pages does not cause a
segmentation fault
Changes in v3:
- Do not print progress messages unless VERBOSE environment variable is
set. Avoid spamming the terminal output of 'make check' on some
versions of autotools.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Useful for detecting out-of-bounds accesses in composite operations.
This will be used by follow-up patches adding new tests.
Changes in v2:
- fix style on fence_image_create_bits args
- add page to stride only if stride_fence
- add comment on the fallback definition about freeing storage
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Define a new token to simplify checking whether fence_malloc() actually
can catch out-of-bounds access.
This will be used in the future to skip tests that rely on fence_malloc
checking functionality.
Changes in v2:
- #define FENCE_MALLOC_ACTIVE always, but change its value to help catch
use of it without including utils.h
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Add mask details to the output.
[Pekka: redo whitespace and print src,dst,mask x and y.]
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
If a user gives multiple patterns or extra arguments, only the last one
was used as the pattern while the former were just ignored. This is a
user error silently converted to something possibly unexpected.
In presence of extra arguments, complain and quit.
Cc: Ben Avison <bavison@riscosopen.org>
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
It was benchmarked against commid id 2be523b from pixman/master
POWER8, 8 cores, 3.4GHz, RHEL 7.1 ppc64le.
reference memcpy speed = 24764.8MB/s (6191.2MP/s for 32bpp fills)
Before After Change
---------------------------------------------
L1 61.92 244.91 +295.53%
L2 62.74 243.3 +287.79%
M 63.03 241.94 +283.85%
HT 59.91 144.22 +140.73%
VT 59.4 174.39 +193.59%
R 53.6 111.37 +107.78%
RT 37.99 46.38 +22.08%
Kops/s 436 506 +16.06%
cairo trimmed benchmarks :
Speedups
========
t-xfce4-terminal-a1 1540.37 -> 1226.14 : 1.26x
t-firefox-talos-gfx 1488.59 -> 1209.19 : 1.23x
Slowdowns
=========
t-evolution 553.88 -> 581.63 : 1.05x
t-poppler 364.99 -> 383.79 : 1.05x
t-firefox-scrolling 1223.65 -> 1304.34 : 1.07x
The slowdowns can be explained in cases where the images are small and
un-aligned to 16-byte boundary. In that case, the function will first
work on the un-aligned area, even in operations of 1 byte. In case of
small images, the overhead of such operations can be more than the
savings we get from using the vmx instructions that are done on the
aligned part of the image.
In the C fast-path implementation, there is no special treatment for the
un-aligned part, as it works in 4 byte quantities on the entire image.
Because llbb is a synthetic test, I would assume it has much less
alignment issues than "real-world" scenario, such as cairo benchmarks,
which are basically recorded traces of real application activity.
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
This patch adds the following helper functions for reuse of code,
hiding BE/LE differences and maintainability.
All of the functions were defined as static force_inline.
Names were copied from pixman-sse2.c so conversion of fast-paths between
sse2 and vmx would be easier from now on. Therefore, I tried to keep the
input/output of the functions to be as close as possible to the sse2
definitions.
The functions are:
- load_128_aligned : load 128-bit from a 16-byte aligned memory
address into a vector
- load_128_unaligned : load 128-bit from memory into a vector,
without guarantee of alignment for the
source pointer
- save_128_aligned : save 128-bit vector into a 16-byte aligned
memory address
- create_mask_16_128 : take a 16-bit value and fill with it
a new vector
- create_mask_1x32_128 : take a 32-bit pointer and fill a new
vector with the 32-bit value from that pointer
- create_mask_32_128 : take a 32-bit value and fill with it
a new vector
- unpack_32_1x128 : unpack 32-bit value into a vector
- unpacklo_128_16x8 : unpack the eight low 8-bit values of a vector
- unpackhi_128_16x8 : unpack the eight high 8-bit values of a vector
- unpacklo_128_8x16 : unpack the four low 16-bit values of a vector
- unpackhi_128_8x16 : unpack the four high 16-bit values of a vector
- unpack_128_2x128 : unpack the eight low 8-bit values of a vector
into one vector and the eight high 8-bit
values into another vector
- unpack_128_2x128_16 : unpack the four low 16-bit values of a vector
into one vector and the four high 16-bit
values into another vector
- unpack_565_to_8888 : unpack an RGB_565 vector to 8888 vector
- pack_1x128_32 : pack a vector and return the LSB 32-bit of it
- pack_2x128_128 : pack two vectors into one and return it
- negate_2x128 : xor two vectors with mask_00ff (separately)
- is_opaque : returns whether all the pixels contained in
the vector are opaque
- is_zero : returns whether the vector equals 0
- is_transparent : returns whether all the pixels
contained in the vector are transparent
- expand_pixel_8_1x128 : expand an 8-bit pixel into lower 8 bytes of a
vector
- expand_alpha_1x128 : expand alpha from vector and return the new
vector
- expand_alpha_2x128 : expand alpha from one vector and another alpha
from a second vector
- expand_alpha_rev_2x128 : expand a reversed alpha from one vector and
another reversed alpha from a second vector
- pix_multiply_2x128 : do pix_multiply for two vectors (separately)
- over_2x128 : perform over op. on two vectors
- in_over_2x128 : perform in-over op. on two vectors
v2: removed expand_pixel_32_1x128 as it was not used by any function and
its implementation was erroneous
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
This patch adds a macro for loading a single vector.
It also make the other LOAD_VECTORx macros use this macro as a base so
code would be re-used.
In addition, I fixed minor coding style issues.
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
The memcpy speed measurement takes several seconds. When you are running
single tests in a harness that iterates dozens or hundreds of times, the
repeated measurements are redundant and take a lot of time. It is also
an open question whether the measured speed changes over long test runs
due to unidentified platform reasons (Raspberry Pi).
Add a command line option to set the reference memcpy speed, skipping
the measuring.
The speed is mainly used to compute how many iterations do run inside
the bench_*() functions, so for repeated testing on the same hardware,
it makes sense to lock that number to a constant.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Add a command line option for choosing CSV output mode.
In CSV mode, only the results in Mpixels/s are printed in an easily
machine-parseable format. All user-friendly printing is suppressed.
This is intended for cases where you benchmark one particular operation
at a time. Running the "all" set of benchmarks will print just fine, but
you may have trouble matching rows to operations as you have to look at
the tests_tbl[] to see what row is which.
Reviewed-by: Ben Avison <bavison@riscosopen.org>
v2: don't add a space after comma in CSV.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Refactor the Mpixels/s computations into a function. Easier to read and
better documents what is being computed.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
The bench_* functions, that did not already do it, are modified to
return the number of pixels processed during the benchmark. This moves
the computation to the site that actually determines the number, and
simplifies bench_composite() a bit.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Move the printing of the memory speed and scaling mode into a new
function. This will help with implementing a machine-readable output
option.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
When given just a single test pattern instead of "all", print the test
details. This can be used to verify the pattern parser agrees with the
user, just like scaling settings are printed.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
We assign string literals to it, so it better be const.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Move explanation printing to a new function. This will help with
implementing a machine-readable output option.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Move printing of usage into a new function and use argv[0] as the
program name. This will help printing usage from multiple places.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
vec_mergeh/l operates differently for BE and LE, because of the order of
the vector elements (l->r in BE and r->l in LE).
To fix that, we simply need to swap between the input parameters, in case
we are working in LE.
v2:
- replace _LITTLE_ENDIAN with WORDS_BIGENDIAN for consistency
- fixed whitespaces and indentation issues
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Reviewed-by: Adam Jackson <ajax@redhat.com>
Acked-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
v2: don't put ';' at the end of macro definition. Instead, move it to
each line the macro is used.
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Reviewed-by: Adam Jackson <ajax@redhat.com>
Acked-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
v2: fixed whitespaces and indentation issues
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Reviewed-by: Adam Jackson <ajax@redhat.com>
Acked-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Replaced usage of vec_lvsl to direct unaligned assignment
operation (=). That is because, according to Power ABI Specification,
the usage of lvsl is deprecated on ppc64le.
Changed COMPUTE_SHIFT_{MASK,MASKS,MASKC} macro usage to no-op for powerpc
little endian since unaligned access is supported on ppc64le.
v2:
- replace _LITTLE_ENDIAN with WORDS_BIGENDIAN for consistency
- fixed whitespaces and indentation issues
Signed-off-by: Fernando Seiti Furusato <ferseiti@linux.vnet.ibm.com>
Reviewed-by: Adam Jackson <ajax@redhat.com>
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Acked-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
The permutation vector isn't correct for LE, so correct its values
in case we are in LE mode.
v2:
- replace _LITTLE_ENDIAN with WORDS_BIGENDIAN for consistency
- change #ifndef to #ifdef for readability
Signed-off-by: Oded Gabbay <oded.gabbay@gmail.com>
Reviewed-by: Adam Jackson <ajax@redhat.com>
Acked-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
These two architectures were the only place where
SIMPLE_NEAREST_SOLID_MASK_FAST_PATH was used, and in both cases the
equivalent SIMPLE_NEAREST_SOLID_MASK_FAST_PATH_NORMAL macro was used
immediately afterwards, so including the NORMAL case in the main macro
simplifies the fast path table.
[Pekka: removed extra comma from the end of
SIMPLE_NEAREST_SOLID_MASK_FAST_PATH]
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
There is some reordering, but the only significant thing to ensure that
the same routine is chosen is that a COVER fast path for a given
combination of operator and source/destination pixel formats must
precede all the variants of repeated fast paths for the same
combination. This patch (and the other mmx/sse2 one) still follows that
rule.
I believe that in every other case, the set of operations that match any
pair of fast paths that are reordered in these patches are mutually
exclusive. While there will be a very subtle timing difference due to
the distance through the table we have to search to find a match
(sometimes faster, sometime slower) there is no evidence that the tables
have been carefully ordered by frequency of occurrence - just for ease
of copy-and-pasting.
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
This macro does exactly the same thing as the platform-neutral macro
SIMPLE_NEAREST_A8_MASK_FAST_PATH.
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
This macro is a superset of the platform-neutral macro
SIMPLE_NEAREST_A8_MASK_FAST_PATH. In other words, in addition to the
_COVER, _NONE and _PAD suffixes, its expansion includes the _NORMAL suffix.
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
This macro does exactly the same thing as the platform-neutral macro
SIMPLE_NEAREST_FAST_PATH.
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
When generating test data, we need to make sure the interpretation of
the data is the same regardless of endianess. That is, the pixel value
for each channel is the same on both little and big-endians.
This fixes a test failure on ppc64 (big-endian).
Tested-by: Fernando Seiti Furusato <ferseiti@linux.vnet.ibm.com> (ppc64le, ppc64, powerpc)
Tested-by: Ben Avison <bavison@riscosopen.org> (armv6l, armv7l, i686)
[Pekka: added commit message]
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Tested-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk> (x86_64)
This places a heavier emphasis on solid images than the other fuzz testers,
and tests both single-pixel repeating bitmap images as well as those created
using pixman_image_create_solid_fill(). In the former case, it also
exercises the case where the bitmap contents are written to after the
image's first use, which is not a use-case that any other test has
previously covered.
[Pekka: added the default case to the switch in test_solid ().]
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Commit 6d2cf40166 ("MIPS: Fix exported symbols in public API") attempted to
add a .hidden assembly directive, conditional on the code being compiled for an
ELF target. Unfortunately the #ifdef added was already inside a macro and
wasn't expanded properly by the preprocessor.
Fix by removing the check. It's unlikely there are many non-ELF MIPS systems
around anyway.
Fixes: Bug 83358 (https://bugs.freedesktop.org/83358)
Fixes: 6d2cf40166 ("MIPS: Fix exported symbols in public API")
Signed-off-by: James Cowgill <james410@cowgill.org.uk>
Cc: Vicente Olivert Riera <Vincent.Riera@imgtec.com>
Cc: Nemanja Lukic <nemanja.lukic@rt-rk.com>
Acked-by: Siarhei Siamashka <siarhei.siamashka@gmail.com>
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Affine-bench is written by following the example of lowlevel-blt-bench.
Affine-bench differs from lowlevel-blt-bench in the following:
- does not test different sized operations fitting to specific caches,
destination is always 1920x1080
- allows defining the affine transformation parameters
- carefully computes operation extents to hit the COVER_CLIP fast paths
Original version by Ben Avison. Changes by Pekka in v3:
- commit message
- style fixes
- more comments
- refactoring (e.g. bench_info_t)
- help output tweak
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
When doing component alpha with a solid mask, use a mask format that has
all the color channels instead of just a8. As Ben Avison explains it:
"Lowlevel-blt-bench initialises all its images using memset(0xCC) so an
a8 solid image would be converted by _pixman_image_get_solid() to
0xCC000000 whereas an a8r8g8b8 would be 0xCCCCCCCC. When you're not in
component alpha mode, only the alpha byte matters for the mask image,
but in the case of component alpha operations, a fast path might decide
that it can save itself a lot of multiplications if it spots that 3
constant mask components are already 0."
No (default) test so far has a solid mask with CA. This is just
future-proofing lowlevel-blt-bench to do what one would expect.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Let lowlevel-blt-bench parse the test name string from the command line,
allowing to run almost infinitely more tests. One is no longer limited
to the tests listed in the big table.
While you can use the old short-hand names like src_8888_8888, you can
also use all possible operators now, and specify pixel formats exactly
rather than just x888, for instance.
This even allows to run crazy patterns like
conjoint_over_reverse_a8b8g8r8_n_r8g8b8x8.
All individual patterns are now interpreted through the parser. The
pattern "all" runs the same old default test set as before but through
the parser instead of the hard-coded parameters.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
This patch is inspired by "lowlevel-blt-bench: Parse test name strings in
general case" by Ben Avison. From Ben's commit message:
"There are many types of composite operation that are useful to benchmark
but which are omitted from the table. Continually having to add extra
entries to the table is a nuisance and is prone to human error, so this
patch adds the ability to break down unknow strings of the format
<operation>_<src>[_<mask]_<dst>[_ca]
where bitmap formats are specified by number of bits of each component
(assumed in ARGB order) or 'n' to indicate a solid source or mask."
Add the parser to lowlevel-blt-bench.c, but do not hook it up to the
command line just yet. Instead, make it run a self-test.
As we now dynamically parse strings similar to the test names in the
huge table 'tests_tbl', we should make sure we can parse the old
well-known test names and produce exactly the same test parameters. The
self-test goes through this old table and verifies the parsing results.
Unfortunately the old table is not exactly consistent, it contains some
special cases that cannot be produced by the parsing rules. Whether
these special cases are intentional or just an oversight is not always
clear. Anyway, add a small table to reproduce the special cases
verbatim.
If we wanted, we could remove the big old table in a follow-up commit,
but then we would also lose the parser self-test.
The point of this whole excercise to let lowlevel-blt-bench recognize
novel test patterns in the future, following exactly the conventions
used in the old table.
Ben, from what I see, this parser has one major difference to what you
wrote. For a solid mask, your parser uses a8r8g8b8 format, while mine
uses a8 which comes from the old table.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Lowlevel-blt-bench uses several pixel format shorthands. Pick them from
the great table in lowlevel-blt-bench.c and add them here so that
format_from_string() can recognize them.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Lowlevel-blt-bench uses the operator alias "outrev". Add an alias for it
in the operator-name table.
Also add aliases for overrev, inrev and atoprev, so that
lowlevel-blt-bench can later recognize them for new test cases.
The aliases are added such, that an operator to name lookup will never
return them; it returns the proper names instead.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Previously there was a flat list of formats, used to iterate over all
formats when looking up a format from name or listing them. This cannot
support name aliases.
To support name aliases (multiple name strings mapping to the same
format), create a format-name mapping table. Functions format_name(),
format_from_string(), and list_formats() should keep on working exactly
like before, except format_from_string() now recognizes the additional
formats that format_name() already supported.
The only the formats from the old format list are added with ENTRY, so
that list_formats() works as before. The whole list is verified against
the authoritative list in pixman.h, entries missing from the old list
are commented out.
The extra formats supported by the old format_name() are added as
ALIASes. A side-effect of that is that now also format_from_string()
recognizes the following new names: x4c4 / c8, x4g4 / g8, c4, g4, g1,
yuy2, yv12, null, solid, pixbuf, rpixbuf, unknown.
Name aliases will be useful in follow-up patches, where
lowlevel-blt-bench.c is converted to parse short-hand format names from
strings.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
Previously there was a flat list of operators (pixman_op_t), used to
iterate over all operators when looking up an operator from name or
listing them. This cannot support name aliases.
To support name aliases (multiple name strings mapping to the same
operator), create an operator-name mapping table. Functions
operator_name, operator_from_string, and list_operators should keep on
working exactly like before, except operator_from_string now recognizes
a few aliases too.
Name aliases will be useful in follow-up patches, where
lowlevel-blt-bench.c is converted to parse operator names from strings.
Lowlevel-blt-bench uses shorthand names instead of the usual names. This
change allows lowlevel-blt-bench.s to use operator_from_string in the
future.
Signed-off-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Reviewed-by: Ben Avison <bavison@riscosopen.org>
This permits format_from_string(), list_formats(), list_operators() and
operator_from_string() to be used from tests other than check-formats.
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
A few violations of coding style were identified in code copied from here
into affine-bench.
Reviewed-by: Pekka Paalanen <pekka.paalanen@collabora.co.uk>
Using "--disable-sse2 --disable-ssse3" configure options and
CFLAGS="-m32 -O2 -g" on an x86 system results in pixman "make check"
failures:
../test-driver: line 95: 29874 Aborted
FAIL: affine-test
../test-driver: line 95: 29887 Aborted
FAIL: scaling-test
One _mm_empty () was missing and another one is needed to workaround
an old GCC bug https://gcc.gnu.org/PR47759 (GCC may move MMX instructions
around and cause test suite failures).
Reviewed-by: Matt Turner <mattst88@gmail.com>
Since a4c79d695d the constant
BILINEAR_INTERPOLATION_BITS must be strictly less than 8, so fix the
comment to say this, and also add a COMPILE_TIME_ASSERT in the
bilinear fetcher in pixman-fast-path.c
The Intel Compiler 14.0.0 claims version GCC 4.7.3 compatibility
via __GNUC__/__GNUC__MINOR__ macros, but does not provide the same
level of GCC vector extensions support as the original GCC compiler:
http://gcc.gnu.org/onlinedocs/gcc/Vector-Extensions.html
Which results in the following compilation failure:
In file included from ../test/utils.h(7),
from ../test/utils.c(3):
../test/utils-prng.h(138): error: expression must have integral type
uint32x4 e = x->a - ((x->b << 27) + (x->b >> (32 - 27)));
^
The problem is fixed by doing a special check in configure for
this feature.
In create_bits() both height and stride are ints, so the result is
also an int, which will overflow if height or stride are big enough
and size_t is bigger than int.
This patch simply casts height to size_t to prevent these overflows,
which prevents the crash in:
https://bugzilla.redhat.com/show_bug.cgi?id=972647
It's not even close to fixing the full problem of supporting big
images in pixman.
See also
https://bugs.freedesktop.org/show_bug.cgi?id=69014
The variables left_x, and right_x in gradient_walker_reset() are
computed from pos, which is a 64 bit quantity, so to avoid overflows,
these variables must be 64 bit as well.
Similarly, the left_x and right_x that are stored in
pixman_gradient_walker_t need to be 64 bit as well; otherwise,
pixman_gradient_walker_pixel() will call reset too often.
This fixes the radial-invalid test, which was generating 'invalid'
floating point exceptions when the overflows caused color values to be
outside of [0, 255].
This program demonstrates a bug in gradient walker, where some integer
overflows cause colors outside the range [0, 255] to be generated,
which in turns cause 'invalid' floating point exceptions when those
colors are converted to uint8_t.
The bug was first reported by Owen Taylor on the #cairo IRC channel.
Benchmark results, "before" is upstream/master
5f661ee719, and "after" contains this
patch on top.
lowlevel-blt-bench, src_8888_0565, 100 iterations:
Before After
Mean StdDev Mean StdDev Confidence Change
L1 25.9 0.20 115.6 0.70 100.00% +347.1%
L2 14.4 0.23 52.7 3.48 100.00% +265.0%
M 14.1 0.01 79.8 0.17 100.00% +465.9%
HT 10.2 0.03 32.9 0.31 100.00% +221.2%
VT 9.8 0.03 29.8 0.25 100.00% +203.4%
R 9.4 0.03 27.8 0.18 100.00% +194.7%
RT 4.6 0.04 10.9 0.29 100.00% +135.9%
At most 19 outliers rejected per test per set.
cairo-perf-trace with trimmed traces results were indifferent.
A system-wide perf_3.10 profile on Raspbian shows significant
differences in the X server CPU usage. The following were measured from
a 130x62 char lxterminal running 'dmesg' every 0.5 seconds for roughly
30 seconds. These profiles are libpixman.so symbols only.
Before:
Samples: 63K of event 'cpu-clock', Event count (approx.): 2941348112, DSO: libpixman-1.so.0.33.1
37.77% Xorg [.] fast_fetch_r5g6b5
14.39% Xorg [.] pixman_composite_over_n_8_8888_asm_armv6
8.51% Xorg [.] fast_write_back_r5g6b5
7.38% Xorg [.] pixman_composite_src_8888_8888_asm_armv6
4.39% Xorg [.] pixman_composite_add_8_8_asm_armv6
3.69% Xorg [.] pixman_composite_src_n_8888_asm_armv6
2.53% Xorg [.] _pixman_image_validate
2.35% Xorg [.] pixman_image_composite32
After:
Samples: 31K of event 'cpu-clock', Event count (approx.): 3619782704, DSO: libpixman-1.so.0.33.1
22.36% Xorg [.] pixman_composite_over_n_8_8888_asm_armv6
13.59% Xorg [.] pixman_composite_src_x888_0565_asm_armv6
12.75% Xorg [.] pixman_composite_src_8888_8888_asm_armv6
6.79% Xorg [.] pixman_composite_add_8_8_asm_armv6
5.95% Xorg [.] pixman_composite_src_n_8888_asm_armv6
4.12% Xorg [.] pixman_image_composite32
3.69% Xorg [.] _pixman_image_validate
3.65% Xorg [.] _pixman_bits_image_setup_accessors
Before, fast_fetch_r5g6b5 + fast_write_back_r5g6b5 took 46% of the
samples in libpixman, and probably incurred some memcpy() load, too.
After, pixman_composite_src_x888_0565_asm_armv6 takes 14%. Note, that
the sample counts are very different before/after, as less time is spent
in Pixman and running time is not exactly the same.
Furthermore, in the above test, the CPU idle function was sampled 9%
before, and 15% after.
v4, Pekka Paalanen <pekka.paalanen@collabora.co.uk> :
Re-benchmarked on Raspberry Pi, commit message.
The two ARM headers contained open-coded copies of pixman_asm_function,
replace these.
Since it seems customary that ARM headers do not use CPP include guards,
rely on the .S files to #include "pixman-arm-asm.h" first. They all
do now.
v2: Fix a build failure on rpi by adding one #include.
Benchmark results, "before" is the patch
* upstream/master 4b76bbfda6
+ ARMv6: Support for very variable-hungry composite operations
+ ARMv6: Add fast path for over_n_8888_8888_ca
and "after" contains the additional patches on top:
+ ARMv6: Add fast path flag to force no preload of destination buffer
+ ARMv6: Add fast path for in_reverse_8888_8888 (this patch)
lowlevel-blt-bench, in_reverse_8888_8888, 100 iterations:
Before After
Mean StdDev Mean StdDev Confidence Change
L1 21.1 0.07 32.3 0.08 100.00% +52.9%
L2 11.6 0.29 18.0 0.52 100.00% +54.4%
M 10.5 0.01 16.1 0.03 100.00% +54.1%
HT 8.2 0.02 12.0 0.04 100.00% +45.9%
VT 8.1 0.02 11.7 0.04 100.00% +44.5%
R 8.1 0.02 11.3 0.04 100.00% +39.7%
RT 4.8 0.04 6.1 0.09 100.00% +27.3%
At most 12 outliers rejected per test per set.
cairo-perf-trace with trimmed traces, 30 iterations:
Before After
Mean StdDev Mean StdDev Confidence Change
t-firefox-paintball.trace 18.0 0.01 14.1 0.01 100.00% +27.4%
t-firefox-chalkboard.trace 36.7 0.03 36.0 0.02 100.00% +1.9%
t-firefox-canvas-alpha.trace 20.7 0.22 20.3 0.22 100.00% +1.9%
t-swfdec-youtube.trace 7.8 0.03 7.8 0.03 100.00% +0.9%
t-firefox-talos-gfx.trace 25.8 0.44 25.6 0.29 93.87% +0.7% (insignificant)
t-firefox-talos-svg.trace 20.6 0.04 20.6 0.03 100.00% +0.2%
t-firefox-fishbowl.trace 21.2 0.04 21.1 0.02 100.00% +0.2%
t-xfce4-terminal-a1.trace 4.8 0.01 4.8 0.01 98.85% +0.2% (insignificant)
t-swfdec-giant-steps.trace 14.9 0.03 14.9 0.02 99.99% +0.2%
t-poppler-reseau.trace 22.4 0.11 22.4 0.08 86.52% +0.2% (insignificant)
t-gnome-system-monitor.trace 17.3 0.03 17.2 0.03 99.74% +0.2%
t-firefox-scrolling.trace 24.8 0.12 24.8 0.11 70.15% +0.1% (insignificant)
t-firefox-particles.trace 27.5 0.18 27.5 0.21 48.33% +0.1% (insignificant)
t-grads-heat-map.trace 4.4 0.04 4.4 0.04 16.61% +0.0% (insignificant)
t-firefox-fishtank.trace 13.2 0.01 13.2 0.01 7.64% +0.0% (insignificant)
t-firefox-canvas.trace 18.0 0.05 18.0 0.05 1.31% -0.0% (insignificant)
t-midori-zoomed.trace 8.0 0.01 8.0 0.01 78.22% -0.0% (insignificant)
t-firefox-planet-gnome.trace 10.9 0.02 10.9 0.02 64.81% -0.0% (insignificant)
t-gvim.trace 33.2 0.21 33.2 0.18 38.61% -0.1% (insignificant)
t-firefox-canvas-swscroll.trace 32.2 0.09 32.2 0.11 73.17% -0.1% (insignificant)
t-firefox-asteroids.trace 11.1 0.01 11.1 0.01 100.00% -0.2%
t-evolution.trace 13.0 0.05 13.0 0.05 91.99% -0.2% (insignificant)
t-gnome-terminal-vim.trace 19.9 0.14 20.0 0.14 97.38% -0.4% (insignificant)
t-poppler.trace 9.8 0.06 9.8 0.04 99.91% -0.5%
t-chromium-tabs.trace 4.9 0.02 4.9 0.02 100.00% -0.6%
At most 6 outliers rejected per test per set.
Cairo perf reports the running time, but the change is computed for
operations per second instead (inverse of running time).
Confidence is based on Welch's t-test. Absolute changes less than 1%
can be accounted as measurement errors, even if statistically
significant.
There was a question of why FLAG_NO_PRELOAD_DST is used. It makes
lowlevel-blt-bench results worse except for L1, but improves some
Cairo trace benchmarks.
"Ben Avison" <bavison@riscosopen.org> wrote:
> The thing with the lowlevel-blt-bench benchmarks for the more
> sophisticated composite types (as a general rule, anything that involves
> branches at the per-pixel level) is that they are only profiling the case
> where you have mid-level alpha values in the source/mask/destination.
> Real-world images typically have a disproportionate number of fully
> opaque and fully transparent pixels, which is why when there's a
> discrepancy between which implementation performs best with cairo-perf
> trace versus lowlevel-blt-bench, I usually favour the Cairo winner.
>
> The results of removing FLAG_NO_PRELOAD_DST (in other words, adding
> preload of the destination buffer) are easy to explain in the
> lowlevel-blt-bench results. In the L1 case, the destination buffer is
> already in the L1 cache, so adding the preloads is simply adding extra
> instruction cycles that have no effect on memory operations. The "in"
> compositing operator depends upon the alpha of both source and
> destination, so if you use uniform mid-alpha, then you actually do need
> to read your destination pixels, so you benefit from preloading them. But
> for fully opaque or fully transparent source pixels, you don't need to
> read the corresponding destination pixel - it'll either be left alone or
> overwritten. Since the ARM11 doesn't use write-allocate cacheing, both of
> these cases avoid both the time taken to load the extra cachelines, as
> well as increasing the efficiency of the cache for other data. If you
> examine the source images being used by the Cairo test, you'll probably
> find they mostly use transparent or opaque pixels.
v4, Pekka Paalanen <pekka.paalanen@collabora.co.uk> :
Rebased, re-benchmarked on Raspberry Pi, commit message.
v5, Pekka Paalanen <pekka.paalanen@collabora.co.uk> :
Rebased, re-benchmarked on Raspberry Pi due to a fix to
"ARMv6: Add fast path for over_n_8888_8888_ca" patch.
Previously, the variable ARGS_STACK_OFFSET was available to extract values
from function arguments during the init macro. Now this changes dynamically
around stack operations in the function as a whole so that arguments can be
accessed at any point. It is also joined by LOCALS_STACK_OFFSET, which
allows access to space reserved on the stack during the init macro.
On top of this, composite macros now have the option of using all of WK0-WK3
registers rather than just the subset it was told to use; this requires the
pixel count to be spilled to the stack over the leading pixels at the start
of each line. Thus, at best, each composite operation can use 11 registers,
plus any pointer registers not required for the composite type, plus as much
stack space as it needs, divided up into constants and variables as necessary.
In create_bits() both height and stride are ints, so the result is
also an int, which will overflow if height or stride are big enough
and size_t is bigger than int.
This patch simply casts height to size_t to prevent these overflows,
which prevents the crash in:
https://bugzilla.redhat.com/show_bug.cgi?id=972647
It's not even close to fixing the full problem of supporting big
images in pixman.
See also
https://bugs.freedesktop.org/show_bug.cgi?id=69014
Several files define identically the asm macro pixman_asm_function.
Merge all these definitions into a new asm header.
The original definition is taken from pixman-arm-simd-asm-scaled.S with
the copyright/licence/author blurb verbatim.
Compiling with the Intel Compiler reveals a problem:
tolerance-test.c(350): error: index variable "i" of for statement following an OpenMP for pragma must be private
# pragma omp parallel for default(none) shared(i) private (result)
^
In addition to this, the 'result' variable also should not be private
(otherwise its value does not survive after the end of the loop). It
needs to be either shared or use the reduction clause to describe how
the results from multiple threads are combined together. Reduction
seems to be more appropriate here.
The Intel Compiler 14.0.0 claims version GCC 4.7.3 compatibility
via __GNUC__/__GNUC__MINOR__ macros, but does not provide the same
level of GCC vector extensions support as the original GCC compiler:
http://gcc.gnu.org/onlinedocs/gcc/Vector-Extensions.html
Which results in the following compilation failure:
In file included from ../test/utils.h(7),
from ../test/utils.c(3):
../test/utils-prng.h(138): error: expression must have integral type
uint32x4 e = x->a - ((x->b << 27) + (x->b >> (32 - 27)));
^
The problem is fixed by doing a special check in configure for
this feature.
in_reverse_8888_8888 is one of the more commonly used operations in the
cairo-perf-trace suite that hasn't been in lowlevel-blt-bench until now.
v4, Pekka Paalanen <pekka.paalanen@collabora.co.uk> :
Split from "Add extra test to lowlevel-blt-bench and fix an
existing one", new summary.
This knocks off one instruction per row. The effect is probably too small to
be measurable, but might as well be included. The second occurrence of this
sequence doesn't actually benefit at all, but is changed for consistency.
The saved instruction comes from combining the "and" inside the .if
statement with an earlier "tst". The "and" was normally needed, except
for in one special case, where bits 4-31 were all shifted off the top of
the register later on in preload_leading_step2, so we didn't care about
their values.
v4, Pekka Paalanen <pekka.paalanen@collabora.co.uk> :
Remove "bits 0-3" from the comments, update patch summary, and
augment message with Ben's suggestion.
An upcoming commit will delete many of the operators from
pixman-combine32.c and rely on the ones in pixman-combine-float.c. The
comments about how the operators were derived are still useful though,
so copy them into pixman-combine-float.c before the deletion.
Consider a HARD_LIGHT operation with the following pixels:
- source: 15 (6 bits)
- source alpha: 255 (8 bits)
- mask alpha: 223 (8 bits)
- dest 255 (8 bits)
- dest alpha: 0 (8 bits)
Since 2 times the source is less than source alpha, the first branch
of the hard light blend mode is taken:
(1 - sa) * d + (1 - da) * s + 2 * s * d
Since da is 0 and d is 1, this degenerates to:
(1 - sa) + 3 * s
Taking (src IN mask) into account along with the fact that sa is 1,
this becomes:
(1 - ma) + 3 * s * ma
= (1 - 223/255.0) + 3 * (15/63.0) * (223/255.0)
= 0.7501400560224089
When computed with the source converted by bit replication to eight
bits, and additionally with the (src IN mask) part rounded to eight
bits, we get:
ma = 223/255.0
s * ma = (60 / 255.0) * (223/255.0) which rounds to 52 / 255
and the result is
(1 - ma) + 3 * s * ma
= (1 - 223/255.0) + 3 * 52/255.0
= 0.7372549019607844
so now we have an error of 0.012885.
Without making changes to the way pixman does integer
rounding/arithmetic, this error must then be considered
acceptable. Due to conservative computations in the test suite we can
however get away with 0.0128 as the acceptable deviation.
This fixes the remaining failures in pixel-test.
Consider a DISJOINT_ATOP operation with the following pixels:
- source: 0xff (8 bits)
- source alpha: 0x01 (8 bits)
- mask alpha: 0x7b (8 bits)
- dest: 0x00 (8 bits)
- dest alpha: 0xff (8 bits)
When (src IN mask) is computed in 8 bits, the resulting alpha channel
is 0 due to rounding:
floor ((0x01 * 0x7b) / 255.0 + 0.5) = floor (0.9823) = 0
which means that since Render defines any division by zero as
infinity, the Fa and Fb for this operator end up as follows:
Fa = max (1 - (1 - 1) / 0, 0) = 0
Fb = min (1, (1 - 0) / 1) = 1
and so since dest is 0x00, the overall result is 0.
However, when computed in full precision, the alpha value no longer
rounds to 0, and so Fa ends up being
Fa = max (1 - (1 - 1) / 0.0001, 0) = 1
and so the result is now
s * ma * Fa + d * Fb
= (1.0 * (0x7b / 255.0) * 1) + d * 0
= 0x7b / 255.0
= 0.4823
so the error in this case ends up being 0.48235294, which is clearly
not something that can be considered acceptable.
In order to avoid this problem, we need to do all arithmetic in such a
way that a multiplication of two tiny numbers can never end up being
zero unless one of the input numbers is itself zero.
This patch makes all computations that involve divisions take place in
floating point, which is sufficient to fix the test cases
This brings the number of failures in pixel-test down to 14.
The Soft Light operator has several branches. One them is decided
based on whether 2 * s is less than or equal to 2 * sa. In floating
point implementations, when those two values are very close to each
other, it may not be completely predictable which branch we hit.
This is a problem because in one branch, when destination alpha is
zero, we get the result
r = d * as
and in the other we get
r = 0
So when d and as are not 0, this causes two different results to be
returned from essentially identical input values. In other words,
there is a discontinuity in the current implementation.
This patch randomly changes the second branch such that it now returns
d * sa instead. There is no deep meaning behind this, because
essentially this is an attempt to assign meaning to division by zero,
and all that is requires is that that meaning doesn't depend on minute
differences in input values.
This makes the number of failed pixels in pixel-test go down to 347.
In the component alpha part of the PDF_SEPARABLE_BLEND_MODE macro, the
expression ~RED_8 (m) is used. Because RED_8(m) gets promoted to int
before ~ is applied, the whole expression typically becomes some
negative value rather than (255 - RED_8(m)) as desired.
Fix this by using unsigned temporary variables.
This reduces the number of failures in pixel-test to 363.
This commit fixes four separate bugs:
1. In the computation
(1 - sa) * d + (1 - da) * s + sa * da * B(s, d)
we were using regular addition for all four channels, but for
superluminescent pixels, the addition could overflow causing
nonsensical results.
2. The variables and return types used for the results of the blend
mode calculations were unsigned, but for various blend modes (and
especially with superluminescent pixels), the blend mode
calculations could be negative, resulting in underflows.
3. The blend mode computations were returned as 8-bit values, which is
not sufficient precision (especially considering that we need
signed results).
4. The value before the final division by 255 was not properly clamped
to [0, 255].
This patch fixes all those bugs. The blend mode computations are now
returned as signed 16 bit values with 1 represented as 255 * 255.
With these fixes, the number of failing pixels in pixel-test goes down
from 431 to 384.
This commit adds a large number of pixel regressions to
pixel-test. All of these have at some point been failing in
blend-mode-test, and most of them do fail currently.
To be specific, with this commit, pixel-test reports 431 failed tests.
This new test program is similar to test/composite in that it relies
on the pixel_checker_t API to do tolerance based verification. But
unlike the composite test, which verifies combinations of a fixed set
of pixels, this one generates random images and verifies that those
composite correctly.
Also unlike composite, tolerance-test supports all the separable blend
mode operators in addition to the original Render operators.
When tests fail, a C struct is printed that can be pasted into
pixel-test for regression purposes.
There is an option "--forever" which causes the random seed to be set
to the current time, and then the test runs until interrupted. This is
useful for overnight runs.
This test currently fails badly due to various bugs in the blend mode
operators. Later commits will fix those.
Support is added to pixel-test for verifying operations involving
masks. If a regression includes a mask, it is verified with the
pixel_checker API in in both unified and component alpha modes.
With GCC 4.8.2 the COMPILE_TIME_ASSERT macro produces a spurious
warning about an unused local typedef:
In file included from pixman.c:29:0:
pixman.c: In function 'optimize_operator':
pixman-private.h:1019:22: warning: typedef 'compile_time_assertion' locally defined but not used [-Wunused-local-typedefs]
The flag -Wno-unused-local-typedefs suppresses that warning.
Currently, if you attempt to use component alpha on source images or
images without RGB channels, Pixman will silently just use unified
alpha instead. This patch makes such images supported for component
alpha.
There is no particularly compelling usecase at the moment, but this
patch does get rid of a bit of special-case code both in
pixman-general.c and in test/composite.c.
If t->bottom is close to MIN_INT (probably invalid value), subtracting
top can lead to underflow which causes crashes. Attached patch will
fix the issue.
This fixes bug 67484.
(cherry picked from commit 5e14da97f1)
This trapezoid causes a crash due to an underflow in the
pixman_trapezoid_valid().
Test case from Ritesh Khadgaray.
(cherry picked from commit 2f876cf867)
The call_test_function() contains some assembly that deliberately
causes the stack to be aligned to 32 bits rather than 128 bits on
x86-32. The intention is to catch bugs that surface when pixman is
called from code that only uses a 32 bit alignment.
However, recent versions of GCC apparently make the assumption (either
accidentally or deliberately) that that the incoming stack is aligned
to 128 bits, where older versions only seemed to make this assumption
when compiling with -msse2. This causes the vector code in the PRNG to
now segfault when called from call_test_function() on x86-32.
This patch fixes that by only making the stack unaligned on 32 bit
Windows, where it would definitely be incorrect for GCC to assume that
the incoming stack is aligned to 128 bits.
V2: Put "defined(...)" around __GNUC__
Reviewed-and-Tested-by: Matt Turner <mattst88@gmail.com>
Bugzilla: https://bugs.gentoo.org/show_bug.cgi?id=491110
(cherry picked from commit f473fd1e75)
SSSE3 is detected by bit 9 of ECX, but we were checking bit 9 of EDX
which is APIC leading to SSSE3 routines being called on CPUs without
SSSE3.
Reviewed-by: Matt Turner <mattst88@gmail.com>
(cherry picked from commit 8487dfbcd0)
The call_test_function() contains some assembly that deliberately
causes the stack to be aligned to 32 bits rather than 128 bits on
x86-32. The intention is to catch bugs that surface when pixman is
called from code that only uses a 32 bit alignment.
However, recent versions of GCC apparently make the assumption (either
accidentally or deliberately) that that the incoming stack is aligned
to 128 bits, where older versions only seemed to make this assumption
when compiling with -msse2. This causes the vector code in the PRNG to
now segfault when called from call_test_function() on x86-32.
This patch fixes that by only making the stack unaligned on 32 bit
Windows, where it would definitely be incorrect for GCC to assume that
the incoming stack is aligned to 128 bits.
V2: Put "defined(...)" around __GNUC__
Reviewed-and-Tested-by: Matt Turner <mattst88@gmail.com>
Bugzilla: https://bugs.gentoo.org/show_bug.cgi?id=491110
SSSE3 is detected by bit 9 of ECX, but we were checking bit 9 of EDX
which is APIC leading to SSSE3 routines being called on CPUs without
SSSE3.
Reviewed-by: Matt Turner <mattst88@gmail.com>
Without this, if tarballs are generated on a system that doesn't have
GTK+ 2 development headers available, the files in EXTRA_DIST will not
be included, which then causes builds from the tarball to fail on
systems that do have GTK+ 2 headers available.
Fixes https://bugs.freedesktop.org/show_bug.cgi?id=71465
Without this, if tarballs are generated on a system that doesn't have
GTK+ 2 development headers available, the files in EXTRA_DIST will not
be included, which then causes builds from the tarball to fail on
systems that do have GTK+ 2 headers available.
Fixes https://bugs.freedesktop.org/show_bug.cgi?id=71465
If t->bottom is close to MIN_INT (probably invalid value), subtracting
top can lead to underflow which causes crashes. Attached patch will
fix the issue.
This fixes bug 67484.
The following patch fixes building pixman with older GCC releases
such as GCC 3.3 and older (OpenBSD; some older archs use GCC 3.3.6)
by changing the method of detecting the presence of __builtin_clz
to utilizing an autoconf check to determine its presence. Compilers
that pretend to be GCC, implement __builtin_clz and are already
utilizing the intrinsic include LLVM/Clang, Open64, EKOPath and
PCC.
The functions pixman_composite_glyphs_no_mask() and
pixman_composite_glyphs() can call into code compiled with -msse2,
which requires the stack to be aligned to 16 bytes. Since the ABIs on
Windows and Linux for x86-32 don't provide this guarantee, we need to
use this attribute to make GCC generate a prologue that realigns the
stack.
This fixes the crash introduced in the previous commit and also
https://bugs.freedesktop.org/show_bug.cgi?id=70348
and
https://bugs.freedesktop.org/show_bug.cgi?id=68300
GCC when compiling with -msse2 and -mssse3 will assume that the stack
is aligned to 16 bytes even on x86-32 and accordingly issue movdqa
instructions for stack allocated variables.
But despite what GCC thinks, the standard ABI on x86-32 only requires
a 4-byte aligned stack. This is true at least on Windows, but there
also was (and maybe still is) Linux code in the wild that assumed
this. When such code calls into pixman and hits something compiled
with -msse2, we get a segfault from the unaligned movdqas.
Pixman has worked around this issue in the past with the gcc attribute
"force_align_arg_pointer" but the problem has resurfaced now in
https://bugs.freedesktop.org/show_bug.cgi?id=68300
because pixman_composite_glyphs() is missing this attribute.
This patch makes fuzzer_test_main() call the test_function through a
trampoline, which, on x86-32, has a bit of assembly that deliberately
avoids aligning the stack to 16 bytes as GCC normally expects. The
result is that glyph-test now crashes.
V2: Mark caller-save registers as clobbered, rather than using
noinline on the trampoline.
The accidental use of declaration after statement breaks compilation
with C89 compilers such as MSVC. Assuming that MSVC is one of the
supported compilers, it makes sense to ask GCC to at least report
warnings for such problematic code.
Clang 3.0 chokes on the following bit of assembly
asm ("pmulhuw %1, %0\n\t"
: "+y" (__A)
: "y" (__B)
);
from pixman-mmx.c with this error message:
fatal error: error in backend: Unsupported asm: input constraint
with a matching output constraint of incompatible type!
So add a check in configure to only enable MMX when the compiler can
deal with it.
The 'value' field in the 'named_int_t' struct is used for both
pixman_repeat_t and pixman_kernel_t values, so the type should be int,
not pixman_kernel_t.
Fixes some warnings like this
scale.c:124:33: warning: implicit conversion from enumeration
type 'pixman_repeat_t' to different enumeration type
'pixman_kernel_t' [-Wconversion]
{ "None", PIXMAN_REPEAT_NONE },
~ ^~~~~~~~~~~~~~~~~~
when compiled with clang.
For superluminescent destinations, the old code could underflow in
uint32_t r = (ad - d) * as / s;
when (ad - d) was negative. The new code avoids this problem (and
therefore causes changes in the checksums of thread-test and
blitters-test), but it is likely still buggy due to the use of
unsigned variables and other issues in the blend mode code.
Change blend_color_dodge() to follow the math in the comment more
closely.
Note, the new code here is in some sense worse than the old code
because it can now underflow the unsigned variables when the source is
superluminescent and (as - s) is therefore negative. The old code was
careful to clamp to 0.
But for superluminescent variables we really need the ability for the
blend function to become negative, and so the solution the underflow
problem is to just use signed variables. The use of unsigned variables
is a general problem in all of the blend mode code that will have to
be solved later.
The CRC32 values in thread-test and blitters-test are updated to
account for the changes in output.
There are no semantic changes, just variables renames. The motivation
for these renames is so that the names are shorter and better match
the one used in the comments.
This commit overhauls the comments in pixman-comine32.c regarding
blend modes:
- Add a link to the PDF supplement that clarifies the specification of
ColorBurn and ColorDodge
- Clarify how the formulas for premultiplied colors are derived form
the ones in the PDF specifications
- Write out the derivation of the formulas in each blend routine
The non-reentrant versions of prng_* functions are thread-safe only in
OpenMP-enabled builds.
Fixes thread-test failing when compiled with Clang (both on Linux and
on MacOS).
Fixes
check-formats.obj : error LNK2019: unresolved external symbol
_strcasecmp referenced in function _format_from_string
check-formats.obj : error LNK2019: unresolved external symbol
_snprintf referenced in function _list_operators
In d1434d112c the benchmarks have been
extended to include other programs as well and the variable names have
been updated accordingly in the autotools-based build system, but not
in the MSVC one.
After a4c79d695d the MMX and SSE2 code
has some declarations after the beginning of a block, which is not
allowed by MSVC.
Fixes multiple errors like:
pixman-mmx.c(3625) : error C2275: '__m64' : illegal use of this type
as an expression
pixman-sse2.c(5708) : error C2275: '__m128i' : illegal use of this
type as an expression
The generated fast paths that were moved into the 'fast'
implementation in ec0e38cbb7 had their
image and iter flag arguments swapped; as a result, none of the fast
paths were ever called.
The SIMD optimized inner loops in the VMX/Altivec code are trying
to emulate unaligned accesses to the destination buffer. For each
4 pixels (which fit into a 128-bit register) the current
implementation:
1. first performs two aligned reads, which cover the needed data
2. reshuffles bytes to get the needed data in a single vector register
3. does all the necessary calculations
4. reshuffles bytes back to their original location in two registers
5. performs two aligned writes back to the destination buffer
Unfortunately in the case if the destination buffer is unaligned and
the width is a perfect multiple of 4 pixels, we may have some writes
crossing the boundaries of the destination buffer. In a multithreaded
environment this may potentially corrupt the data outside of the
destination buffer if it is concurrently read and written by some
other thread.
The valgrind report for blitters-test is full of:
==23085== Invalid write of size 8
==23085== at 0x1004B0B4: vmx_combine_add_u (pixman-vmx.c:1089)
==23085== by 0x100446EF: general_composite_rect (pixman-general.c:214)
==23085== by 0x10002537: test_composite (blitters-test.c:363)
==23085== by 0x1000369B: fuzzer_test_main._omp_fn.0 (utils.c:733)
==23085== by 0x10004943: fuzzer_test_main (utils.c:728)
==23085== by 0x10002C17: main (blitters-test.c:397)
==23085== Address 0x5188218 is 0 bytes after a block of size 88 alloc'd
==23085== at 0x4051DA0: memalign (vg_replace_malloc.c:581)
==23085== by 0x4051E7B: posix_memalign (vg_replace_malloc.c:709)
==23085== by 0x10004CFF: aligned_malloc (utils.c:833)
==23085== by 0x10001DCB: create_random_image (blitters-test.c:47)
==23085== by 0x10002263: test_composite (blitters-test.c:283)
==23085== by 0x1000369B: fuzzer_test_main._omp_fn.0 (utils.c:733)
==23085== by 0x10004943: fuzzer_test_main (utils.c:728)
==23085== by 0x10002C17: main (blitters-test.c:397)
This patch addresses the problem by first aligning the destination
buffer at a 16 byte boundary in each combiner function. This trick
is borrowed from the pixman SSE2 code.
It allows to pass the new thread-test on PowerPC VMX/Altivec systems and
also resolves the "make check" failure reported for POWER7 hardware:
http://lists.freedesktop.org/archives/pixman/2013-August/002871.html
This test program allocates an array of 16 * 7 uint32_ts and spawns 16
threads that each use 7 of the allocated uint32_ts as a destination
image for a large number of composite operations. Each thread then
computes and returns a checksum for the image. Finally, the main
thread computes a checksum of the checksums and verifies that it
matches expectations.
The purpose of this test is catch errors where memory outside images
is read and then written back. Such out-of-bounds accesses are broken
when multiple threads are involved, because the threads will race to
read and write the shared memory.
V2:
- Incorporate fixes from Siarhei for endianness and undefined behavior
regarding argument evaluation
- Make the images 7 pixels wide since the bug only happens when the
composite width is greater than 4.
- Compute a checksum of the checksums so that you don't have to
update 16 values if something changes.
V3: Remove stray dollar sign
The test for pthread_setspecific() can be used as a general test for
whether pthreads are available, so rename the variable from
HAVE_PTHREAD_SETSPECIFIC to HAVE_PTHREADS and run the test even when
better support for thread local variables are available.
However, the pthread arguments are still only added to CFLAGS and
LDFLAGS when pthread_setspecific() is used for thread local variables.
V2: AC_SUBST(PTHREAD_CFLAGS)
Use a temporary variable s containing the absolute value of the stride
as the upper bound in the inner loops.
V2: Do this for the bpp == 16 case as well
Commit 4312f07736 claimed to have made
print_image() work with negative strides, but it didn't actually
work. When the stride was negative, the image buffer would be accessed
as if the stride were positive.
Fix the bug by not changing the stride variable and instead using a
temporary, s, that contains the absolute value of stride.
Instead of having logic to swap the lines around when one of them
doesn't match, store the two lines in an array and use the least
significant bit of the y coordinate as the index into that
array. Since the two lines always have different least significant
bits, they will never collide.
The effect is that lines corresponding to even y coordinates are
stored in info->lines[0] and lines corresponding to odd y coordinates
are stored in info->lines[1].
Pixman supports negative strides, but up until now they haven't been
tested outside of stress-test. This commit adds testing of negative
strides to blitters-test, scaling-test, affine-test, rotate-test, and
composite-traps-test.
The affine-test, blitters-test, and scaling-test all have the ability
to print out the bytes of the destination image. Share this code by
moving it to utils.c.
At the same time make the code work correctly with negative strides.
Converting a double precision number to 16.16 fixed point should be
done by multiplying with 65536.0, not 65535.0.
The bug could potentially cause certain filters that would otherwise
leave the image bit-for-bit unchanged under an identity
transformation, to not do so, but the numbers are close enough that
there weren't any visual differences.
The separable convolution filter supports a subsample_bits of 0 which
corresponds to no subsampling at all, so allow this value to be used
in the scale demo.
This new iterator uses the SSSE3 instructions pmaddubsw and pabsw to
implement a fast iterator for bilinear scaling.
There is a graph here recording the per-pixel time for various
bilinear scaling algorithms as reported by scaling-bench:
http://people.freedesktop.org/~sandmann/ssse3.v2/ssse3.v2.png
As the graph shows, this new iterator is clearly faster than the
existing C iterator, and when used with an SSE2 combiner, it is also
faster than the existing SSE2 fast paths for upscaling, though not for
downscaling.
Another graph:
http://people.freedesktop.org/~sandmann/ssse3.v2/movdqu.png
shows the difference between writing to iter->buffer with movdqa,
movdqu on an aligned buffer, and movdqu on a deliberately unaligned
buffer. Since the differences are very small, the patch here avoids
using movdqa because imposing alignment restrictions on iter->buffer
may interfere with other optimizations, such as writing directly to
the destination image.
The data was measured with scaling-bench on a Sandy Bridge Core
i3-2350M @ 2.3GHz and is available in this directory:
http://people.freedesktop.org/~sandmann/ssse3.v2/
where there is also a Gnumeric spreadsheet ssse3.v2.gnumeric
containing the per-pixel values and the graph.
V2:
- Use uintptr_t instead of unsigned long in the ALIGN macro
- Use _mm_storel_epi64 instead of _mm_cvtsi128_si64 as the latter form
is not available on x86-32.
- Use _mm_storeu_si128() instead of _mm_store_si128() to avoid
imposing alignment requirements on iter->buffer
This commit adds a new, empty SSSE3 implementation and the associated
build system support.
configure.ac: detect whether the compiler understands SSSE3
intrinsics and set up the required CFLAGS
Makefile.am: Add libpixman-ssse3.la
pixman-x86.c: Add X86_SSSE3 feature flag and detect it in
detect_cpu_features().
pixman-ssse3.c: New file with an empty SSSE3 implementation
V2: Remove SSSE3_LDFLAGS since it isn't necessary unless Solaris
support is added.
At the moment iter buffers are only guaranteed to be aligned to a 4
byte boundary. SIMD implementations benefit from the buffers being
aligned to 16 bytes, so ensure this is the case.
V2:
- Use uintptr_t instead of unsigned long
- allocate 3 * SCANLINE_BUFFER_LENGTH byte on stack rather than just
SCANLINE_BUFFER_LENGTH
- use sizeof (stack_scanline_buffer) instead of SCANLINE_BUFFER_LENGTH
to determine overflow
The loops are already unrolled, so it was just a matter of packing
4 pixels into a single XMM register and doing aligned 128-bit
writes to memory via MOVDQA instructions for the SRC compositing
operator fast path. For the other fast paths, this XMM register
is also directly routed to further processing instead of doing
extra reshuffling. This replaces "8 PACKSSDW/PACKUSWB + 4 MOVD"
instructions with "3 PACKSSDW/PACKUSWB + 1 MOVDQA" per 4 pixels,
which results in a clear performance improvement.
There are also some other (less important) tweaks:
1. Convert 'pixman_fixed_t' to 'intptr_t' before using it as an
index for addressing memory. The problem is that 'pixman_fixed_t'
is a 32-bit data type and it has to be extended to 64-bit
offsets, which needs extra instructions on 64-bit systems.
2. Allow to recalculate the horizontal interpolation weights only
once per 4 pixels by treating the XMM register as four pairs
of 16-bit values. Each of these 16-bit/16-bit pairs can be
replicated to fill the whole 128-bit register by using PSHUFD
instructions. So we get "3 PADDW/PSRLW + 4 PSHUFD" instructions
per 4 pixels instead of "12 PADDW/PSRLW" per 4 pixels
(or "3 PADDW/PSRLW" per each pixel).
Now a good question is whether replacing "9 PADDW/PSRLW" with
"4 PSHUFD" is a favourable exchange. As it turns out, PSHUFD
instructions are very fast on new Intel processors (including
Atoms), but are rather slow on the first generation of Core2
(Merom) and on the other processors from that time or older.
A good instructions latency/throughput table, covering all the
relevant processors, can be found at:
http://www.agner.org/optimize/instruction_tables.pdf
Enabling this optimization is controlled by the PSHUFD_IS_FAST
define in "pixman-sse2.c".
3. One use of PSHUFD instruction (_mm_shuffle_epi32 intrinsic) in
the older code has been also replaced by PUNPCKLQDQ equivalent
(_mm_unpacklo_epi64 intrinsic) in PSHUFD_IS_FAST=0 configuration.
The PUNPCKLQDQ instruction is usually faster on older processors,
but has some side effects (instead of fully overwriting the
destination register like PSHUFD does, it retains half of the
original value, which may inhibit some compiler optimizations).
Benchmarks with "lowlevel-blt-bench -b src_8888_8888" using GCC 4.8.1 on
x86-64 system and default optimizations. The results are in MPix/s:
====== Intel Core2 T7300 (2GHz) ======
old: src_8888_8888 = L1: 128.69 L2: 125.07 M:124.86
over_8888_8888 = L1: 83.19 L2: 81.73 M: 80.63
over_8888_n_8888 = L1: 79.56 L2: 78.61 M: 77.85
over_8888_8_8888 = L1: 77.15 L2: 75.79 M: 74.63
new (PSHUFD_IS_FAST=0): src_8888_8888 = L1: 168.67 L2: 163.26 M:162.44
over_8888_8888 = L1: 102.91 L2: 100.43 M: 99.01
over_8888_n_8888 = L1: 97.40 L2: 95.64 M: 94.24
over_8888_8_8888 = L1: 98.04 L2: 95.83 M: 94.33
new (PSHUFD_IS_FAST=1): src_8888_8888 = L1: 154.67 L2: 149.16 M:148.48
over_8888_8888 = L1: 95.97 L2: 93.90 M: 91.85
over_8888_n_8888 = L1: 93.18 L2: 91.47 M: 90.15
over_8888_8_8888 = L1: 95.33 L2: 93.32 M: 91.42
====== Intel Core i7 860 (2.8GHz) ======
old: src_8888_8888 = L1: 323.48 L2: 318.86 M:314.81
over_8888_8888 = L1: 187.38 L2: 186.74 M:182.46
new (PSHUFD_IS_FAST=0): src_8888_8888 = L1: 373.06 L2: 370.94 M:368.32
over_8888_8888 = L1: 217.28 L2: 215.57 M:211.32
new (PSHUFD_IS_FAST=1): src_8888_8888 = L1: 401.98 L2: 397.65 M:395.61
over_8888_8888 = L1: 218.89 L2: 217.56 M:213.48
The most interesting benchmark is "src_8888_8888" (because this code can
be reused for a generic non-separable SSE2 bilinear fetch iterator).
The results shows that PSHUFD instructions are bad for Intel Core2 T7300
(Merom core) and good for Intel Core i7 860 (Nehalem core). Both of these
processors support SSSE3 instructions though, so they are not the primary
targets for SSE2 code. But without having any other more relevant hardware
to test, PSHUFD_IS_FAST=0 seems to be a reasonable default for SSE2 code
and old processors (until the runtime CPU features detection becomes
clever enough to recognize different microarchitectures).
(Rebased on top of patch that removes support for 8-bit bilinear
filtering -ssp)
The calloc call from pixman_image_create_bits may still
rely on http://en.wikipedia.org/wiki/Copy-on-write
Explicitly initializing the destination image results in
a more predictable behaviour.
V2:
- allocate 16 bytes aligned buffer with aligned stride instead
of delegating this to pixman_image_create_bits
- use memset for the allocated buffer instead of pixman solid fill
- repeat tests 3 times and select best results in order to filter
out even more measurement noise
The default has been 7-bit for a while now, and the quality
improvement with 8-bit precision is not enough to justify keeping the
code around as a compile-time option.
Scanline fetchers haven't been used for images other than bits for a
long time, so by making the type reflect this fact, a bit of casting
can be saved in various places.
Later versions of gcc-4.7.x are capable of generating iwMMXt
instructions properly, but gcc-4.8 contains better support and other
fixes, including iwMMXt in conjunction with hardfp. The existing 4.5
requirement was based on attempts to have OLPC use a patched gcc to
build pixman. Let's just require gcc-4.8.
This new iterator works in a separable way; that is, for a destination
scaline, it scales the two involved source scanlines and then caches
them so that they can be reused for the next destination scanlines.
There are two versions of the code, one that uses 64 bit arithmetic,
and one that uses 32 bit arithmetic only. The latter version is
used on 32 bit systems, where it is expected to be faster.
This scheme saves a substantial amount of arithmetic for larger
scalings; the per-pixel times for various configurations as reported
by scaling-bench are graphed here:
http://people.freedesktop.org/~sandmann/separable.v2/v2.png
The "sse2" graph is current default on x86, "mmx" is with sse2
disabled, "old c" is with sse2 and mmx disabled. The "new 32" and "new
64" graphs show times for the new code. As the graphs show, the 64 bit
version of the new code beats the "old c" for all scaling ratios.
The data was taken on a Sandy Bridge Core i3-2350M CPU @ 2.0 GHz
running in 64 bit mode.
The data used to generate the graph is available in this directory:
http://people.freedesktop.org/~sandmann/separable.v2/
There is also a Gnumeric spreadsheet v2.gnumeric containing the
per-pixel values and the graph.
V2:
- Add error message in the OOM/bad matrix case
- Save some shifts by storing the cached scanlines in AGBR order
- Special cased version that uses 32 bit arithmetic when sizeof(long) <= 4
This new benchmark scales a 320 x 240 test a8r8g8b8 image by all
ratios from 0.1, 0.2, ... up to 10.0 and reports the time it to took
to do each of the scaling operations, and the time spent per
destination pixel.
The times reported for the scaling operations are given in
milliseconds, the times-per-pixel are in nanoseconds.
V2: Format output better
The MSVC compiler is very strict about variable declarations after
statements.
Move all the declarations of each block before any statement in the
same block to fix multiple instances of:
alpha-loop.c(XX) : error C2275: 'pixman_image_t' : illegal use of this
type as an expression
I'm got bug in my system:
lcc: "scale.c", line 374: warning: function "gtk_scale_add_mark" declared
implicitly [-Wimplicit-function-declaration]
gtk_scale_add_mark (GTK_SCALE (widget), 0.0, GTK_POS_LEFT, NULL);
^
CCLD scale
scale.o: In function `app_new':
(.text+0x23e4): undefined reference to `gtk_scale_add_mark'
scale.o: In function `app_new':
(.text+0x250c): undefined reference to `gtk_scale_add_mark'
scale.o: In function `app_new':
(.text+0x2634): undefined reference to `gtk_scale_add_mark'
make[2]: *** [scale] Error 1
make[2]: Target `all' not remade because of errors.
$ pkg-config --modversion gtk+-2.0
2.12.1
The demos/scale.c use call to gtk_scale_add_mark() function from 2.16+
version of GTK+. Need do support old GTK+ (rewrite scale.c) or simple
demand of high version of GTK+, like this:
The Loongson code is compiled with -march=loongson2f to enable the MMI
instructions, but binutils refuses to link object code compiled with
different -march settings, leading to link failures later in the
compile. This avoids that problem by checking if we can link code
compiled for Loongson.
Reviewed-by: Matt Turner <mattst88@gmail.com>
Signed-off-by: Markos Chandras <markos.chandras@imgtec.com>
The MSVC compiler is very strict about variable declarations after
statements.
Move all the declarations of each block before any statement in the
same block to fix multiple instances of:
alpha-loop.c(XX) : error C2275: 'pixman_image_t' : illegal use of this
type as an expression
I'm got bug in my system:
lcc: "scale.c", line 374: warning: function "gtk_scale_add_mark" declared
implicitly [-Wimplicit-function-declaration]
gtk_scale_add_mark (GTK_SCALE (widget), 0.0, GTK_POS_LEFT, NULL);
^
CCLD scale
scale.o: In function `app_new':
(.text+0x23e4): undefined reference to `gtk_scale_add_mark'
scale.o: In function `app_new':
(.text+0x250c): undefined reference to `gtk_scale_add_mark'
scale.o: In function `app_new':
(.text+0x2634): undefined reference to `gtk_scale_add_mark'
make[2]: *** [scale] Error 1
make[2]: Target `all' not remade because of errors.
$ pkg-config --modversion gtk+-2.0
2.12.1
The demos/scale.c use call to gtk_scale_add_mark() function from 2.16+
version of GTK+. Need do support old GTK+ (rewrite scale.c) or simple
demand of high version of GTK+, like this:
The SSE2, MMX, and fast implementations all have a copy of the
function iter_init_bits_stride that computes an image buffer and
stride.
Move that function to pixman-utils.c and share it among all the
implementations.
Now that we are using the new _pixman_implementation_iter_init(), the
old _src/_dest_iter_init() functions are no longer needed, so they can
be deleted, and the corresponding fields in pixman_implementation_t
can be removed.
A new field, 'iter_info', is added to the implementation struct, and
all the implementations store a pointer to their iterator tables in
it. A new function, _pixman_implementation_iter_init(), is then added
that searches those tables, and the new function is called in
pixman-general.c and pixman-image.c instead of the old
_pixman_implementation_src_init() and _pixman_implementation_dest_init().
In preparation for sharing all iterator initialization code from all
the implementations, move the general implementation to use a table of
pixman_iter_info_t.
The existing src_iter_init and dest_iter_init functions are
consolidated into one general_iter_init() function that checks the
iter_flags for whether it is dealing with a source or destination
iterator.
Unlike in the other implementations, the general_iter_init() function
stores its own get_scanline() and write_back() functions in the
iterator, so it relies on the initializer being called after
get_scanline and write_back being copied from the struct to the
iterator.
Similar to the SSE2 and MMX patches, this commit replaces a table of
fetcher_info_t with a table of pixman_iter_info_t, and similar to the
noop patch, both fast_src_iter_init() and fast_dest_iter_init() are
now doing exactly the same thing, so their code can be shared in a new
function called fast_iter_init_common().
Similar to the changes to noop, put all the iterators into a table of
pixman_iter_info_t and then do a generic search of that table during
iterator initialization.
Instead of having a nest of if statements, store the information about
iterators in a table of a new struct type, pixman_iter_info_t, and
then walk that table when initializing iterators.
The new struct contains a format, a set of image flags, and a set of
iter flags, plus a pixman_iter_get_scanline_t, a
pixman_iter_write_back_t, and a new function type
pixman_iter_initializer_t.
If the iterator matches an entry, it is first initialized with the
given get_scanline and write_back functions, and then the provided
iter_initializer (if present) is run. Running the iter_initializer
after setting get_scanline and write_back allows the initializer to
override those fields if it wishes.
The table contains both source and destination iterators,
distinguished based on the recently-added ITER_SRC and ITER_DEST;
similarly, wide iterators are recognized with the ITER_WIDE
flag. Having both source and destination iterators in the table means
the noop_src_iter_init() and noop_dest_iter_init() functions become
identical, so this patch factors out their code in a new function
noop_iter_init_common() that both calls.
The following patches in this series will change all the
implementations to use an iterator table, and then move the table
search code to pixman-implementation.c.
We only support alpha maps for BITS images, so it's always to ignore
the alpha map for non-BITS image. This makes it possible get rid of
the check for SOLID images since it will now be subsumed by the check
for FAST_PATH_NO_ALPHA_MAP.
Opaque masks are reduced to NULL images in pixman.c, and those can
also safely be treated as not having an alpha map, so set the
FAST_PATH_NO_ALPHA_MAP bit for those as well.
This will be useful for putting iterators into tables where they can
be looked up by iterator flags. Without this flag, wide iterators can
only be recognized by the absence of ITER_NARROW, which makes testing
for a match difficult.
These indicate whether the iterator is for a source or a destination
image. Note iterator initializers are allowed to rely on one of these
being set, so they can't be left out the way it's generally harmless
(aside from potentil performance degradation) to leave out a
particular fast path flag.
The Loongson code is compiled with -march=loongson2f to enable the MMI
instructions, but binutils refuses to link object code compiled with
different -march settings, leading to link failures later in the
compile. This avoids that problem by checking if we can link code
compiled for Loongson.
Reviewed-by: Matt Turner <mattst88@gmail.com>
Signed-off-by: Markos Chandras <markos.chandras@imgtec.com>
Add necessary support to lowlevel-blt benchmark for benchmarking pixbuf and
rpixbuf fast paths. bench_composite function now checks for pixbuf string in
testname, and if that is detected, use same bits for src and mask images.
Rounding logic was not implemented right.
Instead of using rounding version of the 8-bit shift, logical shifts were used.
Also, code used unnecessary multiplications, which could be avoided by packing
4 destination (a8) pixel into one 32bit register. There were also, unnecessary
spills on stack. Code is rewritten to address mentioned issues.
The bug was revealed by increasing number of the iterations in blitters-test.
Performance numbers on MIPS-74kc @ 1GHz:
lowlevel-blt-bench results
Referent (before):
in_n_8 = L1: 21.20 L2: 22.86 M: 21.42 ( 14.21%) HT: 15.97 VT: 15.69 R: 15.47 RT: 8.00 ( 48Kops/s)
Optimized (first implementation, with bug):
in_n_8 = L1: 89.38 L2: 86.07 M: 65.48 ( 43.44%) HT: 44.64 VT: 41.50 R: 40.77 RT: 16.94 ( 66Kops/s)
Optimized (with bug fix, and code revisited):
in_n_8 = L1: 102.33 L2: 95.65 M: 70.54 ( 46.84%) HT: 48.35 VT: 45.06 R: 43.20 RT: 17.60 ( 66Kops/s)
After introducing new PRNG (pseudorandom number generator) a bug in two DSPr2
routines was revealed. Bug manifested by wrong calculation in composite and
glyph tests, which caused make check to fail for MIPS DSPr2 optimizations.
Bug was in the calculation of the:
*dst = over (src, *dst) when ma == 0xffffffff
In this case src was not negated and shifted right by 24 bits, it was only
negated. When implementing this routine in the first place, I missplaced those
shifts, which alowed me to combine code for over operation and:
UN8x4_MUL_UN8x4 (s, ma);
UN8x4_MUL_UN8 (ma, srca);
ma = ~ma;
UN8x4_MUL_UN8x4_ADD_UN8x4 (d, ma, s);
So I decided to rewrite that piece of code from scratch. I changed logic, so
now assembly code mimics code from pixman-fast-path.c but processes two pixels
at a time. This code should be easier to debug and maintain.
The bug was revealed in commit b31a6962. Errors were detected by composite
and glyph tests.
The old code was calculating horizontal weights for right pixels
in the following way (for simplicity assume 8-bit interpolation
precision):
Start with "x = vx" and do increment "x += ux" after each pixel.
In this case right pixel weight for interpolation can be calculated
as "((x >> 8) ^ 0xFF) + 1", which is the same as "256 - (x >> 8)".
The new code instead:
Starts with "x = -(vx + 1)", performs increment "x += -ux" after
each pixel and calculates right weights as just "(x >> 8) + 1",
eliminating the need for XOR operation in the inner loop.
So we have one instruction less on the critical path. Benchmarks
with "lowlevel-blt-bench -b src_8888_8888" using GCC 4.7.2 on
x86-64 system and default optimizations:
Intel Core i7 860 (2.8GHz):
before: src_8888_8888 = L1: 291.37 L2: 288.58 M:285.38
after: src_8888_8888 = L1: 319.66 L2: 316.47 M:312.06
Intel Core2 T7300 (2GHz):
before: src_8888_8888 = L1: 121.95 L2: 118.38 M:118.52
after: src_8888_8888 = L1: 128.82 L2: 125.12 M:124.88
Intel Atom N450 (1.67GHz):
before: src_8888_8888 = L1: 64.25 L2: 62.37 M: 61.80
after: src_8888_8888 = L1: 64.23 L2: 62.37 M: 61.82
Inspired by the "sse2_bilinear_interpolation" function (single
pixel interpolation) from:
http://lists.freedesktop.org/archives/pixman/2013-January/002575.html
Current blitters-test program had difficulties detecting a bug in
over_n_8888_8888_ca implementation for MIPS DSPr2:
http://lists.freedesktop.org/archives/pixman/2013-March/002645.html
In order to hit the buggy code path, two consecutive mask values had
to be equal to 0xFFFFFFFF because of loop unrolling. The current
blitters-test generates random images in such a way that each byte
has 25% probability for having 0xFF value. Hence each 32-bit mask
value has ~0.4% probability for 0xFFFFFFFF. Because we are testing
many compositing operations with many pixels, encountering at least
one 0xFFFFFFFF mask value reasonably fast is not a problem. If a
bug related to 0xFFFFFFFF mask value is artificialy introduced into
over_n_8888_8888_ca generic C function, it gets detected on 675591
iteration in blitters-test (out of 2000000).
However two consecutive 0xFFFFFFFF mask values are much less likely
to be generated, so the bug was missed by blitters-test.
This patch addresses the problem by also randomly setting the 32-bit
values in images to either 0xFFFFFFFF or 0x00000000 (also with 25%
probability). It allows to have larger clusters of consecutive 0x00
or 0xFF bytes in images which may have special shortcuts for handling
them in unrolled or SIMD optimized code.
The computations in pixman-gradient-walker.c currently take place at
very limited 8 bit precision which results in quite visible artefacts
in gradients. An example is the one produced by demos/linear-gradient
which currently looks like this:
http://i.imgur.com/kQbX8nd.png
With the changes in this commit, the gradient looks like this:
http://i.imgur.com/nUlyuKI.png
The images are also available here:
http://people.freedesktop.org/~sandmann/gradients/before.pnghttp://people.freedesktop.org/~sandmann/gradients/after.png
This patch computes pixels using floating point, but uses a faster
algorithm, which makes up for the loss of performance.
== Theory:
In both the new and the old algorithm, the various gradient
implementations compute a parameter x that indicates how far along the
gradient the current scanline is. The current algorithm has a cache of
the two color stops surrounding the last parameter; those are used in
a SIMD-within-register fashion in this way:
t1 = walker->left_rb * idist + walker->right_rb * dist;
where dist and idist are the distances to the left and right color
stops respectively normalized to the distance between the left and
right stops. The normalization (which involves a division) is captured
in another cached variable "stepper". The cached values are recomputed
whenever the parameter moves in between two different stops (called
"reset" in the implementation).
Because idist and dist are computed in 8 bits only, a lot of
information is lost, which is quite visible as the image linked above
shows.
The new algorithm caches more information in the following way. When
interpolating between stops, the formula to be used is this:
t = ((x - left) / (right - left));
result = lc * (1 - t) + rc * t;
where
- x is the parameter as computed by the main gradient code,
- left is the position of the left color stop,
- right is the position of the right color stop
- lc is the color of the left color stop
- rc is the color of the right color stop
That formula can also be written like this:
result
= lc * (1 - t) + rc * t;
= lc + (rc - lc) * t
= lc + (rc - lc) * ((x - left) / (right - left))
= (rc - lc) / (right - left) * x +
lc - (left * (rc - lc)) / (right - left)
= s * x + b
where
s = (rc - lc) / (right - left)
and
b = lc - left * (rc - lc) / (right - left)
= (lc * (right - left) - left * (rc - lc)) / (right - left)
= (lc * right - rc * left) / (right - left)
To summarize, setting w = (right - left):
s = (rc - lc) / w
b = (lc * right - rc * left) / w
r = s * x + b
Since s and b only depend on the two active stops, both can be cached
so that the computation only needs to do one multiplication and one
addition per pixel (followed by premultiplication of the alpha
channel). That is, seven multiplications in total, which is the same
number as the old SIMD-within-register implementation had.
== Implementation notes:
The new formula described above is implemented in single precision
floating point, and the eight divisions necessary to compute the
cached values are done by multiplication with the reciprocal of the
distance between the color stops.
The alpha values used in the cached computation are scaled by 255.0,
whereas the RGB values are kept in the [0, 1] interval. The ensures
that after premultiplication, all values will be in the [0, 255]
interval.
This scaling is done by first dividing all the all the channels by
257, and then later on dividing the r, g, b channels by 255. It would
be more natural to do all this scaling in only one place, but
inexplicably, that results in a (substantial) slowdown on Sandy Bridge
with GCC v 4.7.
== Performance impact (median of three runs of radial-perf-test):
== Intel Sandy Bridge, Core i3 @ 1.2GHz
Before: 0.014553
After: 0.014410
Change: 1.0% faster
== AMD Barcelona @ 1.2 GHz
Before: 0.021735
After: 0.021328
Change: 1.9% faster
Ie., slightly faster, though conceivably there could be a negative
impact on machines with a bigger difference between integer and
floating point performance.
V2:
- Use 's' and 'b' in the variable names instead of 'm' and 'd'. This
way they match the explanation above
- Move variable declarations to the top of the function
- Remove unused stepper field
- Some formatting fixes
- Don't pointlessly include pixman-combine32.h
- Don't offset x for each pixel; go back to offsetting left_x and
right_x at reset time. The offsets cancel out in the formula above,
so there is no impact on the calcualations.
This benchmark renders one of the radial gradients used in the
swfdec-youtube cairo trace 500 times and reports the average time it
took.
V2: Update .gitignore
This program displays a linear gradient from blue to yellow. Due to
limited precision in pixman-gradient-walker.c, it currently has some
ugly artefacts that gives it a 'brushed metal' appearance.
V2: Update .gitignore
The infinite loop detected by "affine-test 212944861" is caused by an
overflow in this expression:
max_x = pixman_fixed_to_int (vx + (width - 1) * unit_x) + 1;
where (width - 1) * unit_x doesn't fit in a signed int. This causes
max_x to be too small so that this:
src_width = 0
while (src_width < REPEAT_NORMAL_MIN_WIDTH && src_width <= max_x)
src_width += src_image->bits.width;
results in src_width being 0. Later on when src_width is used for
repeat calculations, we get the infinite loop.
By casting unit_x to int64_t, the expression no longer overflows and
affine-test 212944861 and infinite-loop no longer loop forever.
(cherry picked from commit de60e2e0e3)
GdkPixbufs are not premultiplied, so when using them to display pixman
images, there is some unecessary conversions going on: First the image
is converted to non-premultiplied, and then GdkPixbuf premultiplies
before sending the result to the X server. These conversions may cause
the displayed image to not be exactly identical to the original.
This patch just uses a cairo image surface instead, which avoids these
conversions.
Also make the comment about sRGB a little more concise.
The source, mask and destination buffers are initialised to 0xCC just after
they are allocated. Between each benchmark, there are a pair of memcpys,
from the destination buffer to the source buffer and back again (there are
no explanatory comments, but presumably this is an effort to flush the
caches). However, it has an unintended consequence, which is to change the
contents of the buffers on entry to subsequent benchmarks. This means it is
not a fair test: for example, with over_n_8888 (featured in the following
patches) it reports L2 and even M tests as being faster than the L1 test,
because after the L1 test, the source buffer is filled with fully opaque
pixels, for which over_n_8888 has a shortcut.
The fix here is simply to reverse the order of the memcpys, so src and
destination are both filled with 0xCC on entry to all tests.
Some recent code added new type casts from pointer to unsigned long.
These type casts result in compiler warnings for systems like
MinGW-w64 (64 bit Windows) where sizeof(unsigned long) != sizeof(void *).
Signed-off-by: Stefan Weil <sw@weilnetz.de>
Reviewed-by: Chris Wilson <chris@chris-wilson.co.uk>
If we fail to find a composite function, don't update the fast path
cache with the dummy compositing function.
Also make the error message state that the bug is likely caused by
issues with thread local storage.
While releasing 0.29.2 the distcheck run produced a number of error
messages that had to be fixed in 349015e1fc.
These were not caught before so nobody had actually run pixman with
debugging turned on. It's not the first time this has happened, see
5b0563f39e for example.
So this patch makes the return_if_fail() macros use unlikely() around
the expressions and then turns on error logging at all times. The
performance hit should negligible since we were already evaluating the
expressions.
The place where DEBUG actually does cause a performance hit is in the
region selfcheck code, and that will still only be enabled in
development snapshots.
The check-formats programs reveals that the 8 bit pipeline cannot meet
the current 0.004 acceptable deviation specified in utils.c, so we
have to increase it. Some of the failing pixels were captured in
pixel-test, which with this commit now passes.
== a4r4g4b4 DISJOINT_XOR a8r8g8b8 ==
The DISJOINT_XOR operator applied to an a4r4g4b4 source pixel of
0xd0c0 and a destination pixel of 0x5300ea00 results in the exact
value:
fa = (1 - da) / sa = (1 - 0x53 / 255.0) / (0xd / 15.0) = 0.7782
fb = (1 - sa) / da = (1 - 0xd / 15.0) / (0x53 / 255.0) = 0.4096
r = fa * (0xc / 15.0) + fb * (0xea / 255.0) = 0.99853
But when computing in 8 bits, we get:
fa8 = ((255 - 0x53) * 255 + 0xdd / 2) / 0xdd = 0xc6
fb8 = ((255 - 0xdd) * 255 + 0x53 / 3) / 0x53 = 0x68
r8 = (fa8 * 0xcc + 127) / 255 + (fb8 * 0xea + 127) / 255 = 0xfd
and
0xfd / 255.0 = 0.9921568627450981
for a deviation of 0.00637118610187, which we then have to consider
acceptable given the current implementation.
By switching to computing the result with
r = (fa * s + fb * d + 127) / 255
rather than
r = (fa * s + 127) / 255 + (fb * d + 127) / 255
the deviation would be only 0.00244961747442, so at some point it may
be worth doing either this, or switching to floating point for
operators that involve divisions.
Note that the conversion from 4 bits to 8 bits does not cause any
error in this case because both rounding and bit replication produces
an exact result when the number of from-bits divide the number of
to-bits.
== a8r8g8b8 OVER r5g6b5 ==
When OVER compositing the a8r8g8b8 pixel 0x0f00c300 with the x14r6g6b6
pixel 0x03c0, the true floating point value of the resulting green
channel is:
0xc3 / 255.0 + (1.0 - 0x0f / 255.0) * (0x0f / 63.0) = 0.9887955
but when compositing 8 bit values, where the 6-bit green channel is
converted to 8 bit through bit replication, the 8-bit result is:
0xc3 + ((255 - 0x0f) * 0x3c + 127) / 255 = 251
which corresponds to a real value of 0.984314. The difference from the
true value is 0.004482 which is bigger than the acceptable deviation
of 0.004. So, if we were to compute all the CONJOINT/DISJOINT
operators in floating point, or otherwise make them more accurate, the
acceptable deviation could be set at 0.0045.
If we were doing the 6-bit conversion with rounding:
(x / 63.0 * 255.0 + 0.5)
instead of bit replication, the deviation in this particular case
would be only 0.0005, so we may want to consider this at some
point.
This test program contains a table of individual operator/pixel
combinations. For each pixel combination, images of various sizes are
filled with the pixels and then composited. The result is then
verified against the output of do_composite(). If the result doesn't
match, detailed error information is printed.
The initial 14 pixel combinations currently all fail.
The check-formats.c test depends on the exact format of the strings
returned from these functions, so add a test here.
a1-trap-test isn't the ideal place, but it seems like overkill to add
a new test just for these trivial checks.
Given an operator and two formats, this program will composite and
check all pixels where the red and blue channels are 0. That is, if
the two formats are a8r8g8b8 and a4r4g4b4, all source pixels matching
the mask
0xff00ff00
are composited with the given operator against all destination pixels
matching the mask
0xf0f0
and the result is then verified against the do_composite() function
that was moved to utils.c earlier.
This program reveals that a number of operators and format
combinations are not computed to within the precision currently
accepted by pixel_checker_t. For example:
check-formats over a8r8g8b8 r5g6b5 | grep failed | wc -l
30
reveals that there are 30 pixel combinations where OVER produces
insufficiently precise results for the a8r8g8b8 and r5g6b5 formats.
In c2cb303d33, return_if_fail()s were added to
prevent the trapezoid rasterizers from being called with non-alpha
formats. However, stress-test actually does call the rasterizers with
non-alpha formats, but because _pixman_log_error() is disabled in
versions with an odd minor number, the errors never materialized.
Fix this by changing the argument to random format to an enum of three
values DONT_CARE, PREFER_ALPHA, or REQUIRE_ALPHA, and then in the
switch that calls the trapezoid rasterizers, pass the appropriate
value for the function in question.
The old one belongs to the email address sandmann@daimi.au.dk, which
doesn't work anyore.
Also use gpg to get the name and address for the "(Signed by ...)"
line since that works more reliably for me than using git.
In particular this affects single-core ARMs (e.g. ARM11, Cortex-A8), which
are usually configured this way. For other CPUs, this should only add a
constant time, which will be cancelled out by the EXCLUDE_OVERHEAD runs.
The problems were caused by cachelines becoming permanently evicted from
the cache, because the code that was intended to pull them back in again on
each iteration assumed too long a cache line (for the L1 test) or failed to
read memory beyond the first pixel row (for the L2 test). Also, the reloading
of the source buffer was unnecessary.
These issues were identified by Siarhei in this post:
http://lists.freedesktop.org/archives/pixman/2013-January/002543.html
The clip_color() function has some checks to avoid division by zero,
but they are done by comparing the value to 4 * FLT_EPSILON, where a
better choice is the IS_ZERO() macro that compares to +/- FLT_MIN.
In set_sat(), the check is that *max > *min before dividing by *max -
*min, but that has the potential problem that interactions between GCC
optimizions and 80 bit x87 registers could mean that (*max > *min) is
true in 80 bits, but (*max - *min) is 0 in 32 bits, so that the
division by zero is not prevented. Using IS_ZERO() here as well
prevents this.
Move the entire contents of pixman-arm-simd-asm.S to a new file;
ultimately this will only retain the scaled operations, so it is
named pixman-arm-simd-asm-scaled.S. Added new header file
pixman-arm-simd-asm.h, containing the macros which are the basis of
all the new ARMv6 implementations, although at this point in the
series, nothing uses them and the library should be binary-identical.
For large upscalings the level of subsampling for the filter has a
quite visible effect, so make it settable in the UI so that people can
experiment with various values.
Old functions pixman_transform_point() and pixman_transform_point_3d()
now become just wrappers for pixman_transform_point_31_16() and
pixman_transform_point_31_16_3d(). Eventually their uses should be
completely eliminated in the pixman code and replaced with their
extended range counterparts. This is needed in order to be able
to correctly handle any matrices and parameters that may come
to pixman from the code responsible for XRender implementation.
This test uses __float128 data type when it is available
for implementing a "perfect" reference implementation. The
output from from pixman_transform_point_31_16() and
pixman_transform_point_31_16_affine() is compared with the
reference implementation to make sure that the rounding
errors may only show up in a single least significant bit.
The platforms and compilers, which do not support __float128
data type, can rely on crc32 checksum for the pseudorandom
transform results.
GCC supports 128-bit floating point data type on some platforms (including
but not limited to x86 and x86-64). This may be useful for tests, which
need prefectly accurate reference implementations of certain algorithms.
The following new functions are added:
pixman_transform_point_31_16_3d() -
Calculates the product of a matrix and a vector multiplication.
pixman_transform_point_31_16() -
Calculates the product of a matrix and a vector multiplication.
Then converts the homogenous resulting vector [x, y, z] to
cartesian [x', y', 1] variant, where x' = x / z, and y' = y / z.
pixman_transform_point_31_16_affine() -
A faster sibling of the other two functions, which assumes affine
transformation, where the bottom row of the matrix is [0, 0, 1] and
the last element of the input vector is set to 1.
These functions transform a point with 31.16 fixed point coordinates from
the destination space to a point with 48.16 fixed point coordinates in
the source space.
The results are accurate and the rounding errors may only show up in
the least significant bit. No overflows are possible for the affine
transformations as long as the input data is provided in 31.16 format.
In the case of projective transformations, some output values may be not
representable using 48.16 fixed point format. In this case the results
are clamped to return maximum or minimum 48.16 values (so that the caller
can at least handle NONE and PAD repeats correctly).
Processing two pixels at once is used to reduce the number of
arithmetic operations.
The speedup relative to the generic fetch_scanline_r5g6b5() from
"pixman-access.c" (pixman was compiled with gcc 4.7.2):
MIPS 74K 480MHz : 20.32 MPix/s -> 26.47 MPix/s
ARM11 700MHz : 34.95 MPix/s -> 38.22 MPix/s
ARM Cortex-A8 1000MHz : 87.44 MPix/s -> 100.92 MPix/s
ARM Cortex-A9 1700MHz : 150.95 MPix/s -> 158.13 MPix/s
ARM Cortex-A15 1700MHz : 148.91 MPix/s -> 155.42 MPix/s
IBM Cell PPU 3200MHz : 75.29 MPix/s -> 98.33 MPix/s
Intel Core i7 2800MHz : 257.02 MPix/s -> 376.93 MPix/s
That's the performance for C code (SIMD and assembly optimizations
are disabled via PIXMAN_DISABLE environment variable).
Unrolling loops improves performance, so just use it here.
Also GCC can't properly optimize this code for RISC processors and
allocate 0x1F001F constant in a register. Because this constant is
too large to be represented as an immediate operand in instructions,
GCC inserts some redundant arithmetics. This problem can be workarounded
by explicitly using a variable for 0x1F001F constant and also initializing
it by a read from another volatile variable. In this case GCC is forced
to allocate a register for it, because it is not seen as a constant anymore.
The speedup relative to the generic store_scanline_r5g6b5() from
"pixman-access.c" (pixman was compiled with gcc 4.7.2):
MIPS 74K 480MHz : 33.22 MPix/s -> 43.42 MPix/s
ARM11 700MHz : 50.16 MPix/s -> 78.23 MPix/s
ARM Cortex-A8 1000MHz : 117.75 MPix/s -> 196.34 MPix/s
ARM Cortex-A9 1700MHz : 177.04 MPix/s -> 320.32 MPix/s
ARM Cortex-A15 1700MHz : 231.44 MPix/s -> 261.64 MPix/s
IBM Cell PPU 3200MHz : 130.25 MPix/s -> 145.61 MPix/s
Intel Core i7 2800MHz : 502.21 MPix/s -> 721.73 MPix/s
That's the performance for C code (SIMD and assembly optimizations
are disabled via PIXMAN_DISABLE environment variable).
Adding specialized iterators for r5g6b5 color format allows us to work
on fine tuning performance of r5g6b5 fetch/write-back operations in the
pixman general "fetch -> combine -> store" pipeline.
These iterators also make "src_x888_0565" fast path redundant, so it can
be removed.
We should always have at least a C combiner available, so we never
expect the search to fail. If it does, emit an error and return a
dummy function.
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
We never expect to fail to find the appropriate function as the
general_composite_rect should always match. So if somehow we fallthrough
the search, emit a _pixman_log_error() and return a dummy function.
Note that we remove some conditionals and a level of indentation hence a
large amount of code movement. This also reveals that in a few places we
are duplicating stack variables that can be eliminated later.
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
Based on the existing sse2_8888_n_8888 nearest scaling routines.
fishbowl on an i5-2500: 60.9s -> 56.9s
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
This path is being exercised by compositing of trapezoids for clipmasks, for
instance as used in the firefox-asteroids cairo-trace.
IVB i7-3720qm ./tests/lowlevel-blt-bench add_n_8_8888:
reference memcpy speed = 14846.7MB/s (3711.7MP/s for 32bpp fills)
before: L1: 681.10 L2: 735.14 M:701.44 ( 28.35%) HT:283.32 VT:213.23 R:208.93 RT: 77.89 ( 793Kops/s)
after: L1: 992.91 L2:1017.33 M:982.58 ( 39.88%) HT:458.93 VT:332.32 R:326.13 RT:136.66 (1287Kops/s)
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
This path is being exercised by inplace compositing of trapezoids, for
instance as used in the firefox-asteroids cairo-trace.
IVB i3-3720qm ./tests/lowlevel-blt-bench add_n_888:
reference memcpy speed = 14918.3MB/s (3729.6MP/s for 32bpp fills)
before: L1:1752.44 L2:2259.48 M:2215.73 ( 58.80%) HT:589.49 VT:404.04 R:424.69 RT:134.68 (1182Kops/s)
after: L1:3931.21 L2:6132.78 M:3440.17 ( 92.24%) HT:1337.70 VT:1357.64 R:1270.27 RT:359.78 (2161Kops/s)
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
Having 4 or fewer bits means we can do two components at
a time in a single 32 bit register.
Here are the results for firefox-fishtank on a Pandaboard with
4.6.3 and PIXMAN_DISABLE="arm-neon"
Before:
[ # ] backend test min(s) median(s) stddev. count
[ 0] image t-firefox-fishtank 7.841 7.910 0.70% 6/6
After:
[ # ] backend test min(s) median(s) stddev. count
[ 0] image t-firefox-fishtank 6.951 6.995 1.11% 6/6
This adds two extra tests, src_n_8 and src_8_8, which I have been
using to benchmark my ARMv6 changes.
I'd also like to propose that it requires an exact test name as the
executable's argument, as achieved by this strstr to strcmp change.
Without this, it is impossible to only benchmark (for example)
add_8_8, add_n_8 or src_n_8, due to those also being substrings of
many other test names.
This function returns the name of the given format code, which is
useful for printing out debug information. The function is written as
a switch without a default value so that the compiler will warn if new
formats are added in the future. The fake formats used in the fast
path tables are also recognized.
The function is used in alpha_map.c, where it replaces an existing
format_name() function, and in blitters-test.c, affine-test.c, and
scaling-test.c.
This function returns the name of the given operator, which is useful
for printing out debug information. The function is done as a switch
without a default value so that the compiler will warn if new
operators are added in the future.
The function is used in affine-test.c, scaling-test.c, and
blitters-test.c.
Ben Avison pointed out here:
http://lists.freedesktop.org/archives/pixman/2013-January/002485.html
that there isn't really any documentation about how to submit patches
to pixman. This patch adds some information to the README file.
v2: Incorporate some comments from Ben Avison
v3: Change gitweb URL to cgit
The noop src iterator already has code to handle solid images, but
that code never actually runs currently because it is not possible for
an image to have both a format code of PIXMAN_solid and a flag of
FAST_PATH_BITS_IMAGE.
If these two were to be set at the same time, the
fast_composite_tiled_repeat() fast path would trigger for solid images
(because it triggers for PIXMAN_any formats, which includes
PIXMAN_solid), but for solid images we can usually do better than that
fast path.
So this patch removes _pixman_solid_fill_iter_init() and instead
handles such images (along with repeating 1x1 bits images without an
alpha map) in pixman-noop.c.
When a 1x1R image is involved in the general composite path, before
this patch, it would hit this code in repeat() in pixman-inlines.h:
while (*c >= size)
*c -= size;
while (*c < 0)
*c += size;
and those loops could run for a huge number of iteratons (proportional
to the composite width). For such cases, the performance improvement
is really big:
./test/lowlevel-blt-bench -n add_n_8888:
Before:
add_n_8888 = L1: 3.86 L2: 3.78 M: 1.40 ( 0.06%) HT: 1.43 VT: 1.41 R: 1.41 RT: 1.38 ( 19Kops/s)
After:
add_n_8888 = L1:1236.86 L2:2468.49 M:1097.88 ( 49.04%) HT:476.49 VT:429.05 R:417.04 RT:155.12 ( 817Kops/s)
Automake-1.13 has removed long obsolete AM_CONFIG_HEADER macro (
http://lists.gnu.org/archive/html/automake/2012-12/msg00038.html )
and autoreconf errors out upon seeing it.
Attached patch replaces obsolete AM_CONFIG_HEADER with now proper
AC_CONFIG_HEADERS.
pixman-float-combiner.c currently uses checks like these:
if (x == 0.0f)
...
else
... / x;
to prevent division by 0. In theory this is correct: a division-by-zero
exception is only supposed to happen when the floating point numerator is
exactly equal to a positive or negative zero.
However, in practice, the combination of x87 and gcc optimizations
causes issues. The x87 registers are 80 bits wide, which means the
initial test:
if (x == 0.0f)
may be false when x is an 80 bit floating point number, but when x is
rounded to a 32 bit single precision number, it becomes equal to
0.0. In principle, gcc should compensate for this quirk of x87, and
there are some options such as -ffloat-store, -fexcess-precision=standard,
and -std=c99 that will make it do so, but these all have a performance
cost. It is also possible to set the FPU to a mode that makes it do
all computation with single or double precision, but that would
require pixman to save the existing mode before doing anything with
floating point and restore it afterwards.
Instead, this patch side-steps the issue by replacing exact checks for
equality with zero with a new macro that checkes whether the value is
between -FLT_MIN and FLT_MIN.
There is extensive reading material about this issue linked off the
infamous gcc bug 323:
http://gcc.gnu.org/bugzilla/show_bug.cgi?id=323
ARMv6 has UQADD8 instruction, which implements unsigned saturated
addition for 8-bit values packed in 32-bit registers. It is very useful
for UN8x4_ADD_UN8x4, UN8_rb_ADD_UN8_rb and ADD_UN8 macros (which would
otherwise need a lot of arithmetic operations to simulate this operation).
Since most of the major ARM linux distros are built for ARMv7, we are
much less dependent on runtime CPU detection and can get practical
benefits from conditional compilation here for a lot of users.
The results of cairo-perf-trace benchmark on ARM Cortex-A15 with pixman
compiled by gcc 4.7.2 and PIXMAN_DISABLE set to "arm-simd arm-neon":
Speedups
========
image firefox-talos-gfx (29938.22 0.12%) -> (27814.76 0.51%) : 1.08x speedup
image firefox-asteroids (23241.11 0.07%) -> (21795.19 0.07%) : 1.07x speedup
image firefox-canvas-alpha (174519.85 0.08%) -> (164788.64 0.20%) : 1.06x speedup
image poppler (9464.46 1.61%) -> (8991.53 0.14%) : 1.05x speedup
This change reduces 3 shifts, 3 ANDs and 2 ORs (total 8 arithmetic
operations) to 3 shifts, 2 ANDs and 2 ORs (total 7 arithmetic
operations).
We get garbage in the high 16 bits of the result, which might need
to be cleared when casting to uint16_t (it would bring us back to
total 8 arithmetic operations). However in the case if the result
of a8r8g8b8->r5g6b5 conversion is immediately stored to memory, no
extra instructions for clearing these garbage bits are needed.
This allows the a8r8g8b8->r5g6b5 conversion code to be compiled
into 4 instructions for ARM instead of 5 (assuming a good optimizing
compiler), which has no pipeline stalls on ARM11 as an additional
bonus.
The change in benchmark results for 'lowlevel-blt-bench src_8888_0565'
with PIXMAN_DISABLE="arm-simd arm-neon mips-dspr2 mmx sse2" and pixman
compiled by gcc-4.7.2:
MIPS 74K 480MHz : 40.44 MPix/s -> 40.13 MPix/s
ARM11 700MHz : 50.28 MPix/s -> 62.85 MPix/s
ARM Cortex-A8 1000MHz : 124.38 MPix/s -> 141.85 MPix/s
ARM Cortex-A15 1700MHz : 281.07 MPix/s -> 303.29 MPix/s
Intel Core i7 2800MHz : 515.92 MPix/s -> 531.16 MPix/s
The same trick was used in xomap (X server for Nokia N800/N810):
http://repository.maemo.org/pool/diablo/free/x/xorg-server/
xorg-server_1.3.99.0~git20070321-0osso20083801.tar.gz
It is easier and safer to modify their code in the case if the
calculations need some temporary variables. And the temporary
variables will be needed soon.
A check is needed that the creation of the temporary image in
pixman_composite_trapezoids() succeeds.
Fixes crash in stress-test -s 0x313c on my system.
stress-test -s 0x17ee crashes because pixman_composite_trapezoids() is
given a mask_format of PIXMAN_c8, which causes it to create a
temporary image with that format but without a palette. This causes
crashes later.
The only mask_format that we actually support are those of TYPE_ALPHA,
so this patch add a return_if_fail() to ensure this.
Similarly, although currently it won't crash if given an invalid
format, alpha-only formats have always been the only thing that made
sense for the pixman_rasterize_edges() functions, so add a
return_if_fail() ensuring that the destination format is of type
PIXMAN_TYPE_ALPHA.
The entry points add_trapezoids(), rasterize_trapezoid() and
composite_trapezoid() are exercised with random trapezoids.
This uncovers crashes with stress-test seeds 0x17ee and 0x313c.
Radial gradients are conceptually rendered as a sequence of circles
generated by linearly extrapolating from the two circles given by the
gradient specification. Any circles in that sequence that would end up
with a negative radius are not drawn, a condition that is enforced by
checking that t * dr is bigger than mindr:
if (t * dr > mindr)
However, it is legitimate for a circle to have radius exactly 0, so
the test should use >= rather than >.
This gets rid of the dots in demos/radial-test except for when the c2
circle has radius 0 and a repeat mode of either NONE or NORMAL. Both
those dots correspond to a t value of 1.0, which is outside the
defined interval of [0.0, 1.0) and therefore subject to the repeat
algorithm. As a result, in the NONE case, a value of 1.0 turns into
transparent black. In the NORMAL case, 1.0 wraps around and becomes
0.0 which is red, unlike 0.99 which is blue.
Cc: ranma42@gmail.com
Add two new gradient columns, one where the start circle is has radius
0 and one where the end circle has radius 0. All the new gradients
except for one are rendered with a bright dot in the middle. In most
but not all cases this is incorrect.
Cc: ranma42@gmail.com
MinGW-w64 uses the GNU compiler and does not define _MSC_VER.
Nevertheless, it provides xmmintrin.h and must be handled
here like the MS compiler. Otherwise compilation fails due to
conflicting declarations.
Signed-off-by: Stefan Weil <sw@weilnetz.de>
Similar to the fast paths for general affine access, add some fast
paths for the separable filter for all combinations of formats
x8r8g8b8, a8r8g8b8, r5g6b5, a8 with the four repeat modes.
It is easy to see the speedup in the demos/scale program.
This new test is derived from radial-test.c and displays conical
gradients at various angles.
It also demonstrates how PIXMAN_REPEAT_NORMAL is supposed to work when
used with a gradient specification where the first stop is not a 0.0:
In this case the gradient is supposed to have a smooth transition from
the last stop back to the first stop with no sharp transitions. It
also shows that the repeat mode is not ignored for conical gradients
as one might be tempted to think.
The zone plate image is a useful test case for image scalers because
it contains all representable frequencies, so any imperfection in
resampling filters will show up as Moire patterns.
This version is symmetric around the midpoint of the image, so since
rotating it is supposed to be a noop, it can also be used to verify
that the resampling filters don't shift the image.
V2: Run the file through OptiPNG to cut the size in half, as suggested
by Siarhei.
This program allows interactively scaling and rotating images with
using various filters and repeat modes. It uses
pixman_filter_create_separate_convolution() to generate the filters.
This new API is a helper function to create filter parameters suitable
for use with PIXMAN_FILTER_SEPARABLE_CONVOLUTION.
For each dimension, given a scale factor, reconstruction and sample
filter kernels, and a subsampling resolution, this function will
compute a convolution of the two kernels scaled appropriately, then
sample that convolution and return the resulting vectors in a form
suitable for being used as parameters to
PIXMAN_FILTER_SEPARABLE_CONVOLUTION.
The filter kernels offered are the following:
- IMPULSE: Dirac delta function, ie., point sampling
- BOX: Box filter
- LINEAR: Linear filter, aka. "Tent" filter
- CUBIC: Cubic filter, currently Mitchell-Netravali
- GAUSSIAN: Gaussian function, sigma=1, support=3*sigma
- LANCZOS2: Two-lobed Lanczos filter
- LANCZOS3: Three-lobed Lanczos filter
- LANCZOS3_STRETCHED: Three-lobed Lanczos filter, stretched by 4/3.0.
This is the "Nice" filter from Dirty Pixels by
Jim Blinn.
The intended way to use this function is to extract scaling factors
from the transformation and then pass those to this function to get a
filter suitable for compositing with that transformation. The filter
kernels can be chosen according to quality and performance tradeoffs.
To get equivalent quality to GdkPixbuf for downscalings, use BOX for
both reconstruction and sampling. For upscalings, use LINEAR for
reconstruction and IMPULSE for sampling (though note that for
upscaling in both X and Y directions, simply using
PIXMAN_FILTER_BILINEAR will likely be a better choice).
This filter is a new way to use a convolution matrix for filtering. In
contrast to the existing CONVOLUTION filter, this new variant is
different in two respects:
- It is subsampled: Instead of just one convolution matrix, this
filter chooses between a number of matrices based on the subpixel
sample location, allowing the convolution kernel to be sampled at a
higher resolution.
- It is separable: Each matrix is specified as the tensor product of
two vectors. This has the advantages that many fewer values have to
be stored, and that the filtering can be done separately in the x
and y dimensions (although the initial implementation doesn't
actually do that).
The motivation for this new filter is to improve image downsampling
quality. Currently, the best pixman can do is the regular convolution
filter which is limited to coarsely sampled convolution kernels.
With this new feature, any separable filter can be used at any desired
resolution.
This adds a fast SIMD-optimized variant of a small noncryptographic
PRNG originally developed by Bob Jenkins:
http://www.burtleburtle.net/bob/rand/smallprng.html
The generated pseudorandom data is good enough to pass "Big Crush"
tests from TestU01 (http://en.wikipedia.org/wiki/TestU01).
SIMD code uses http://gcc.gnu.org/onlinedocs/gcc/Vector-Extensions.html
which is a GCC specific extension. There is also a slower alternative
code path, which should work with any C compiler.
The performance of filling buffer with random data:
Intel Core i7 @2.8GHz (SSE2) : ~5.9 GB/s
ARM Cortex-A15 @1.7GHz (NEON) : ~2.2 GB/s
IBM Cell PPU @3.2GHz (Altivec) : ~1.7 GB/s
Also dropped redundant volatile keyword because any object
can be accessed via char* pointer without breaking aliasing
rules. The compilers are able to optimize this function to either
constant 0 or 1.
It is not entirely obvious how pixman gets from "location in the
source image" to "pixel value stored in the destination". This file
describes how the filters work, and in particular how positions are
rounded to samples.
The pixel computed by the convolution filter should be rounded off,
not truncated. As a simple example consider a convolution matrix
consisting of five times 0x3333. If all five all five input pixels are
0xff, then the result of truncating will be
(5 * 0x3333 * 255) >> 16 = 254
But the real value of the computation is (5 * 0x3333 / 65536.0) * 254
= 254.9961, so the error is almost 1. If the user isn't very careful
about normalizing the convolution kernel so that it sums to one in
fixed point, such error might cause solid images to change color, or
opaque images to become translucent.
The fix is simply to round instead of truncate.
After two fixed-point numbers are multiplied, the result is shifted
into place, but up until now pixman has simply discarded the low-order
bits instead of rounding to the closest number.
Fix that by adding 0x8000 (or 0x2 in one place) before shifting and
update the test checksums to match.
These modifications fix lots of compiler warnings for systems where
sizeof(unsigned long) != sizeof(void *).
This is especially true for MinGW-w64 (64 bit Windows).
Signed-off-by: Stefan Weil <sw@weilnetz.de>
MinGW-w64 uses the GNU compiler and does not define _MSC_VER.
Nevertheless, it provides xmmintrin.h and must be handled
here like the MS compiler. Otherwise compilation fails due to
conflicting declarations.
Signed-off-by: Stefan Weil <sw@weilnetz.de>
It is useful to be able to invert a matrix in place, but currently
pixman_f_transform_invert() will produce wrong results if you pass the
same matrix as both source and destination.
Fix that by inverting into a temporary matrix and then copying that to
the destination.
pixman_composite_trapezoids() is supposed to composite across the
entire destination, but it actually only composites across the extent
of the trapezoids. For operators such as ADD or OVER this doesn't
matter since a zero source has no effect on the destination. But for
operators such as SRC or IN, it does matter.
So for such operators where a zero source has an effect, don't clip to
the trap extents.
When pixman_image_create_bits() function is given NULL for bits, it
will allocate a new buffer and initialize it to zero. However, in some
cases, only a small region of the image is actually used; in that case
it is wasteful to touch all of the memory.
The new pixman_image_create_bits_no_clear() works exactly like
_create_bits() except that it doesn't initialize any newly allocated
memory.
(fixes bug #52101)
On MirBSD, the compiler produces a (harmless) warning when the compiler
is called without the standard CFLAGS:
foo.c:0: note: someone does not honour COPTS correctly, passed 0 times
However, PIXMAN_LINK_WITH_ENV considers _any_ output on stderr as an
error, even if the exit status of the compiler is 0. Furthermore, it
resets CFLAGS and LDFLAGS at the start. On MirBSD, this will lead to a
warning in each test, making all such tests fail. In particular, the
pthread_setspecific test fails, thus pixman is compiled without thread
support. This leads to compile errors later on, or at least it did when
I tried this on pkgsrc. Re-adding the saved CFLAGS, LDFLAGS and LIBS
before the test makes it work.
The second hunk inverts the order of the pthread flag checks. On BSD
systems (this is true at least on OpenBSD and MirBSD), both -lpthread
and -pthread work but the latter is "preferred", whatever this means.
This provides a way to enable MIPS DSP ASE optimizations if running
under qemu-user (where /proc/cpuinfo contains information about the
host processor instead of the emulated one). Can be used for running
pixman test suite in qemu-user when having no access to real MIPS
hardware.
The while part of a do/while loop was formatted as if it were a while
loop with an empty body. Probably some indent tool misinterpreted the
code at some point.
In order for a src/mask pair to be considered a pixbuf, they have to
have identical transformations, but we don't check for that. Since the
only fast paths we have for pixbufs require identity transformations,
it sufficies to check that both source and mask are
untransformed.
This is also the reason that this bug can't be triggered by any test
code - if the source and mask had different transformations, we would
consider them a pixbuf, but then wouldn't take the fast path because
at least one of the transformations would be different from the
identity.
GCC doesn't move the divisions out of the loop, so do it manually by
looking up the four (1.0f / mask) values in a table. Table lookups are
used under the theory that one L2 hit plus three L1 hits is preferable
to four floating point divisions.
Since pixman-combine64.[ch] are not used anymore, there is no point
generating these files from pixman-combine.[ch].template.
Also get rid of dependency on perl in configure.ac.
The 64 bit pipeline is not used anymore, so it can now be removed.
Don't generate pixman-combine64.[ch] anymore. Don't generate the
pixman-srgb.c anymore. Delete all the 64 bit fetchers in
pixman-access.c, all the 64 bit iterator functions in
pixman-bits-image.c and all the functions that expand from 8 to 16
bits.
In pixman-bits-image.c, remove bits_image_fetch_untransformed_64() and
add bits_image_fetch_untransformed_float(); change
dest_get_scanline_wide() to produce a floating point buffer,
In the gradients, change *_get_scanline_wide() to call
pixman_expand_to_float() instead of pixman_expand().
In pixman-general.c change the wide Bpp to 16 instead of 8, and
initialize the buffers to 0 to prevent NaNs from causing trouble.
In pixman-noop.c make the wide solid iterator generate floating point
pixels.
In pixman-solid-fill.c, cache a floating point pixel, and make the
wide iterator generate floating point pixels.
Bug fix in bits_image_fetch_untransformed_repeat_normal
Three new function pointer fields are added to bits_image_t:
fetch_scanline_float
fetch_pixel_float
store_scanline_float
similar to the existing 32 and 64 bit accessors. The fetcher_info_t
struct in pixman_access similarly gets a new get_scanline_float field.
For most formats, the new get_scanline_float field is set to a new
function fetch_scanline_generic_float() that first calls the 32 bit
fetcher uses the 32 bit scanline fetcher and then expands these pixels
to floating point.
For the 10 bpc formats, new floating point accessors are added that
use pixman_unorm_to_float() and pixman_float_to_unorm() to convert
back and forth.
The PIXMAN_a8r8g8b8_sRGB format is handled with a 256-entry table that
maps 8 bit sRGB channels to linear single precision floating point
numbers. The sRGB->linear direction can then be done with a simple
table lookup.
The other direction is currently done with 4096-entry table which
works fine for 16 bit integers, but not so great for floating
point. So instead this patch uses a binary search in the sRGB->linear
table. The existing 32 bit accessors for the sRGB format are also
converted to use this method.
A new struct argb_t containing a floating point pixel is added to
pixman-private.h and conversion routines are added to pixman-utils.c
to convert normalized integers to and from that struct.
New functions:
- pixman_expand_to_float()
Expands a buffer of integer pixels to a buffer of argb_t pixels
- pixman_contract_from_float()
Converts a buffer of argb_t pixels to a buffer integer pixels
- pixman_float_to_unorm()
Converts a floating point number to an unsigned normalized integer
- pixman_unorm_to_float()
Converts an unsigned normalized integer to a floating point number
This test runs the new floating point combiners on random input with
divide-by-zero exceptions turned on.
With the floating point combiners the only thing we guarantee is that
divide-by-zero exceptions are not generated, so change
enable_fp_exceptions() to only enable those, and rename accordingly.
This file contains floating point implementations of combiners for all
pixman operators. These combiners operate on buffers containing single
precision floating point pixels stored in (a, r, g, b) order.
The combiners are added to the pixman_implementation_t struct, but
nothing uses them yet.
This commit incorporates a number of bug fixes contributed by Andrea
Canciani.
Some notes:
- The combiners are making sure to never divide by zero regardless of
input, so an application could enable divide-by-zero exceptions and
pixman wouldn't generate any.
- The operators are implemented according to the Render spec. Ie.,
- If the input pixels are between 0 and 1, then so is the output.
- The source and destination coefficients for the conjoint and
disjoint operators are clamped to [0, 1].
- The PDF operators are not described in the render spec, and the
implementation here doesn't do any clamping except in the final
conversion from floating point to destination format.
All of the above will need to be rethought if we add support for pixel
formats that can support negative and greater-than-one pixels. It is
in fact already the case in principle that convolution filters can
produce pixels with negative values, but since these go through the
broken "wide" path that narrows everything to 32 bits, these negative
values don't currently survive to the combiners.
In preparation for an upcoming change of the wide pipe to use floating
point, comment out some formats in glyph-test that are going to be
using floating point and update the CRC32 value to match.
Add const to pointer arguments when the function doesn't change the
pointed-to data.
Also in add_glyphs() in pixman-glyph.c make 'white' in add_glyphs()
static and const.
Before this patch it was often faster to scale and repeat
in two passes because each pass used a fast path vs.
the slow path that the single pass approach takes. This
makes it so that the single pass approach has competitive
performance.
The infinite loop detected by "affine-test 212944861" is caused by an
overflow in this expression:
max_x = pixman_fixed_to_int (vx + (width - 1) * unit_x) + 1;
where (width - 1) * unit_x doesn't fit in a signed int. This causes
max_x to be too small so that this:
src_width = 0
while (src_width < REPEAT_NORMAL_MIN_WIDTH && src_width <= max_x)
src_width += src_image->bits.width;
results in src_width being 0. Later on when src_width is used for
repeat calculations, we get the infinite loop.
By casting unit_x to int64_t, the expression no longer overflows and
affine-test 212944861 and infinite-loop no longer loop forever.
This test demonstrates a bug where a certain transformation matrix can
result in an infinite loop. It was extracted as a standalone version
of "affine-test 212944861".
If given the option -nf, the test program will not call fail_after()
and therefore potentially run forever.
Printing out the translation and scale is a bit misleading because the
actual transformation matrix can be modified in various other ways.
Instead simply print the whole transformation matrix that is actually
used.
In the checks for whether the transforms are rotation matrices "-1"
and "1" were used instead of the correct -pixman_fixed_1 and
pixman_fixed_1.
Fixes test suite failure for rotate-test.
This program exercises a bug in pixman-image.c where "-1" and "1" were
used instead of the correct "- pixman_fixed_1" and "pixman_fixed_1".
With the fast implementation enabled:
% ./rotate-test
rotate test failed! (checksum=35A01AAB, expected 03A24D51)
Without it:
% env PIXMAN_DISABLE=fast ./rotate-test
pixman: Disabled fast implementation
rotate test passed (checksum=03A24D51)
V2: The first version didn't have lcg_srand (testnum) in test_transform().
In general, the component alpha version of an operator is supposed to
do this:
- multiply source with mask in all channels
- multiply mask with source alpha in all channels
- compute the regular operator in all channels using the
mask value whenever source alpha is called for
The first two steps are usually accomplished with the function
combine_mask_ca(), but for operators where source alpha is not used,
such as SRC, ADD and OUT, the simpler function
combine_mask_value_ca(), which doesn't compute the new mask values,
can be used.
However, the PDF blend modes generally *do* make use of source alpha,
so they can't use combine_mask_value_ca() as they do now. They have to
use combine_mask_ca().
This patch fixes this in combine_multiply_ca() and the CA combiners
generated by PDF_SEPARABLE_BLEND_MODE.
The fast_composite_scaled_nearest() function can be called when the
format is x8b8g8r8. In that case pixels fetched in fetch_nearest()
need to have their alpha channel set to 0xff.
Fixes test suite failure in scaling-test.
Reviewed-by: Matt Turner <mattst88@gmail.com>
Update the CRC values based on what the general implementation
reports. This reveals a bug in the fast implementation:
% env PIXMAN_DISABLE="mmx sse2" ./test/scaling-test
pixman: Disabled mmx implementation
pixman: Disabled sse2 implementation
scaling test failed! (checksum=AA722B06, expected 03A23E0C)
vs.
% env PIXMAN_DISABLE="mmx sse2 fast" ./test/scaling-test
pixman: Disabled fast implementation
pixman: Disabled mmx implementation
pixman: Disabled sse2 implementation
scaling test passed (checksum=03A23E0C)
Reviewed-by: Matt Turner <mattst88@gmail.com>
Instead of relying on each implementation to delegate when an iterator
can't be initialized, change the type of iterator initializers to
boolean and make pixman-implementation.c do the delegation whenever an
iterator initializer returns FALSE.
As in the blt commit, do the delegation in pixman-implementation.c
whenever the implementation fill returns FALSE instead of relying on
each implementation to do it by itself.
With this change there is no longer any reason for the implementations
to have one fill function that delegates and one that actually blits,
so consolidate those in the NEON, DSPr2, SSE2, and MMX
implementations.
Rather than require each individual implementation to do the
delegation for blt, just do it in pixman-implementation.c whenever the
implementation blt returns FALSE.
With this change, there is no longer any reason for the
implementations to have one blt function that delegates and one that
actually blits, so consolidate those in the NEON, DSPr2, SSE2, and MMX
implementations.
The MSVC compiler is very strict about variable declarations after
statements.
Move all the declarations of each block before any statement in
the same block to fix multiple instances of:
pixman-mmx.c(xxxx) : error C2275: '__m64' : illegal use of this type
as an expression
The sRGB conversion has to be done every time the limits are being
computed. Without this fix, pixel_checker_get_min/max() will produce
the wrong results when called from somewhere other than
pixel_checker_check().
This declaration used to be necessary when
_pixman_image_get_scanline_generic_64() referred to a structure that
itself referred back to _pixman_image_get_scanline_generic_64().
This makes show_image() deal with more formats than just a8r8g8b8, in
particular, a8r8g8b8_sRGB can now be handled.
Images that are passed to show_image with a format of a8r8g8b8_sRGB
are displayed without modification under the assumption that the
monitor is approximately sRGB.
Images with a format of a8r8g8b8 are also displayed without
modification since many other users of show_image() have been
generating essentially sRGB data with this format. Other formats are
also assumed to be gamma compressed; these are converted to a8r8g8b8
before being displayed.
With these changes, srgb-test.c doesn't need to do its own conversion
anymore.
glyph-test would sometimes set a solid image as an alpha map, which is
not allowed. When this happened and the debug spew was enabled,
messages like this one would be generated:
*** BUG ***
In pixman_image_set_alpha_map: The expression
!alpha_map || alpha_map->type == BITS was false
Set a breakpoint on '_pixman_log_error' to debug
Fix this by not passing the ALLOW_SOLID flag to create_image() when
the resulting is to be used as an alpha map.
The rectangles in the clip region set in set_general_properties()
would sometimes overflow, which would lead to messages like these:
*** BUG ***
In pixman_region32_union_rect: Invalid rectangle passed
Set a breakpoint on '_pixman_log_error' to debug
when the micro version number of pixman is even.
Fix this by detecting the overflow and clamping such that the x2/y2
coordinates are less than INT32_MAX.
Composite checks random combinations of operations that now also have
sRGB sources, masks and destinations, and stress-test validates the
read/write primitives.
Simple sRGB color blender test can be used to determine if the sRGB processing
works as expected. It blends alpha ramps of purple and green together such that
at midpoint of image, 50 % blend of both is realized. At that point, sRGB-aware
processing yields a result close to #bbb rather than #888, which is the linear
light blending result.
The demo also contains the sample computation for sRGB premultiplied alpha.
sRGB format is defined as a new format type, PIXMAN_TYPE_ARGB_SRGB. One form of
this type is provided, PIXMAN_a8r8g8b8_sRGB. Use of an sRGB format triggers
wide processing, and the pixel fetch/store functions handle the relevant
conversion between color spaces. Pixman itself is thought to compose in the
linearized sRGB color space.
sRGB conversion is tabularized. For sRGB to linear, we are using only 256
values because the current source format uses 8 bits per component precision.
For linear to sRGB, it turns out that only 4096 brightness levels are required
to generate all of the 256 sRGB color values, and therefore only 12 bits per
component are considered during store. As a special case, a no-op
sRGB->linear->sRGB conversion is constructed to be lossless by adjusting the
sRGB->linear conversion table where necessary.
When not optimizing, write _mm_shuffle_pi16() as a statement
expression with inline assembly. That way we avoid
__builtin_ia32_pshufw(), which is only available when compiling with
-msse, while still allowing the non-optimizing gcc to understand that
the second argument is a compile time constant.
Tested-by: Knut Petersen <knut_petersen@t-online.de>
A new function pixman_cpuid() is added that runs the cpuid instruction
and returns the results. On GCC this function uses inline assembly; on
MSVC, the function calls the __cpuid intrinsic.
There is also a new function called have_cpuid() which detects whether
cpuid is available. On x86-64 and MSVC, it simply returns TRUE; on
x86-32 bit, it checks whether the 22nd bit of eflags can be
modified. On MSVC this does have the consequence that pixman will no
longer work CPUS without cpuid (ie., older than 486 and some 486
models).
These two functions together makes it possible to write a generic
detect_cpu_features() in plain C. This function is then used in a new
have_feature() function that checks whether a specific set of feature
bits is available.
Aside from the cleanups and simplifications, the main benefit from
this patch is that pixman now can do feature detection on x86-64, so
that newer instruction sets such as SSSE3 and SSE4.1 can be used. (And
apparently the assumption that x86-64 CPUs always have MMX and SSE2 is
no longer correct: Knight's Corner is x86-64, but doesn't have them).
V2: Rename the constants in the getisax() code, as pointed out by Alan
Coopersmith. Also reinstate the result variable and initialize
features to 0.
V3: Fixes for the fact that the upper 32 bits of a 64 bit register are
zeroed whenever the corresponding 32 bit register is written to.
V4: Fixes for the fact that in 32 bit mode, when gcc is not optimizing
there were not enough registers available. The new code uses the "a",
"b", "c", and "d" constraints instead, and has two separate versions
for 32 and 64 bit modes.
Declare functions *_inverse() and *_contains_rectangle() in the same
way as the other functions are declared. This doesn't imply any semantic
changes. It's just a unification of coding styles.
Get rid of the initialized and have_vmx static variables in
pixman-ppc.c There is no point to them since CPU detection only
happens once per process.
On Linux, just read /proc/self/auxv instead of generating the filename
with getpid() and don't bother with the stack buffer. Instead just
read the aux entries one by one.
Organize pixman-arm.c such that each operating system/compiler exports
a detect_cpu_features() function that returns a bitmask with the
various features that we are interested in. A new function
have_feature() then calls this function, caches the result, and return
whether the given feature is available.
The result is that all the pixman_have_arm_<feature> functions become
redundant and can be deleted.
There is no reason to have pixman_have_<feature> functions when all
they do is call pixman_have_mips_feature().
Instead rename pixman_have_mips_feature() to have_feature() and call
it directly from _pixman_mips_get_implementations(). Also on
non-Linux, just make have_feature() return FALSE.
Similar to the x86 commit, this moves the ARM specific CPU detection
to its own file which exports a pixman_arm_get_implementations()
function that is supposed to be a noop on non-ARM.
Extract the x86 specific parts of pixman-cpu.c and put them in their
own file called pixman-x86.c which exports one function
pixman_x86_get_implementations() that creates the MMX and SSE2
implementations. This file is supposed to be compiled on all
architectures, but pixman_x86_get_implementations() should be a noop
on non-x86.
When compiling with -O0, gcc doesn't understand that in
signed char x = 0;
...
asm ("...",
: "K" (x));
x is constant. Fix this by using an immediate constant instead of a
variable.
In fast_composite_tiled_repeat() if the source image is less than a
certain constant width, a clone is created which is then
pre-repeated. However, the source image's palette, if it has one, is
not cloned, so for indexed images, the pre-repeating would crash.
Fix this by not doing any pre-repeating for images with a palette set.
stress-test current almost never composites anything because the clip
rectangles and transformations are such that either
_pixman_compute_composite_region32() or analyze_extent() will return
FALSE.
Fix this by:
- making log_rand() return smaller numbers so that the clip rectangles
are more likely to be within the destination image
- adding rand_x() and rand_y() functions that pick positions within an
image and using them for positioning alpha maps and source/mask
positions.
- making it less likely that clip regions are used in general
These changes make the test take longer, so speed it up a little by
making most images smaller and by reducing the maximum convolution
filter from 17x19 to 3x4.
With these changes, stress-test reveals a crash in iteration 0xd39
where fast_composite_tiled_repeat() creates an indexed image without a
palette.
Macro BILINEAR_INTERPOLATION_BITS in pixman-private.h selects
the number of fractional bits used for bilinear interpolation.
scaling-test and affine-test have checksums for 4-bit, 7-bit
and 8-bit configurations.
Using _mm_loadl_epi64() to load two pixels at once (pairs of top
and bottom pixels) is faster than loading each pixel separately
and combining them with _mm_set_epi32().
=== cairo-perf-trace ===
before: image firefox-fishtank 66.912 66.931 0.13% 3/3
after: image firefox-fishtank 57.584 58.349 0.74% 3/3
=== lowlevel-blt-bench ===
before: src_8888_8888 = L1: 181.10 L2: 179.14 M:178.08 ( 11.02%) HT:153.22 VT:133.45 R:142.24 RT: 95.32
after: src_8888_8888 = L1: 228.68 L2: 225.75 M:223.98 ( 14.23%) HT:185.32 VT:155.06 R:162.73 RT:102.52
This improvement was suggested by Matt Turner on irc.
When compiling using the win32 build system, config.h is not
available nor needed.
Fixes:
pixman-glyph.c(26) : fatal error C1083: Cannot open include file:
'config.h': No such file or directory
Port of 2ddd1c498b to SSE2.
Uses the pmadd technique described in
http://software.intel.com/sites/landingpage/legacy/mmx/MMX_App_24-16_Bit_Conversion.pdf
Works around lack of packusdw instruction by first sign extending the
values.
fast: src_8888_0565 = L1: 681.40 L2: 689.20 M: 644.76 ( 25.51%) HT:404.42 VT:288.04 R:306.07 RT:150.80 (1619Kops/s)
mmx: src_8888_0565 = L1:2056.03 L2:1985.44 M:1574.91 ( 61.87%) HT:533.10 VT:376.35 R:416.10 RT:178.79 (1833Kops/s)
sse2: src_8888_0565 = L1:3793.42 L2:3653.44 M:1878.83 ( 73.94%) HT:535.03 VT:407.96 R:421.46 RT:163.31 (1727Kops/s)
and for reference, using packusdw
sse4: src_8888_0565 = L1:4396.18 L2:4229.25 M:1904.04 ( 75.18%) HT:559.79 VT:427.96 R:440.06 RT:165.71 (1744Kops/s)
Notice that MMX is faster in the RT case because it can operate on
8-bytes instead of the current 16-bytes for SSE2.
Before bisecting to find the exact test which has failed, we
first need to make sure that the first test is fine (the first
test is "good" and the whole range is "bad"). Otherwise
test 2 gets incorrectly flagged as problematic in the case
if we already got a failure on test 1 right from the start.
Unsigned loop variables are only supported since version 3.0
of OpenMP specification. Changing loop variables to use int32_t
type fixes pixman build problems with path64 compiler.
The destination buffer was initialized with random uint32_t values, so
it started out different on big endian vs. little endian. Fix that by
initializing the buffer with random uint8_t values instead.
Instead of caching these fetchers in the image structure, and then
have the iterator getter call them from there, simply change them to
be iterator getters themselves.
This avoids an extra indirect function call and lets us get rid of the
get_scanline_32/64 fields in pixman_image_t.
Optimizing the unorm_to_unorm functions allows a speedup from:
src_8888_2x10 = L1: 62.08 L2: 60.73 M: 59.61 ( 4.30%) HT: 46.81
VT: 42.17 R: 43.18 RT: 26.01 (325Kops/s)
to:
src_8888_2x10 = L1: 76.94 L2: 78.43 M: 75.87 ( 5.59%) HT: 56.73
VT: 52.39 R: 53.00 RT: 29.29 (363Kops/s)
on a i7 Q720 -based laptop.
The key of the patch is the observation that unorm_to_unorm's work can
more easily be done with a simple multiplication and shift, when the
function is applied repeatedly and the parameters are not compile-time
constants. For instance, converting from 0xfe to 0xfefe (expanding
from 8 bits to 16 bits) can be done by calculating
c = c * 0x101
However, sometimes the result is not a neat replication of all the
bits. For instance, going from 10 bits to 16 bits can be done by
calculating
c = c * 0x401UL >> 4
where the intermediate result is 20 bit wide repetition of the 10-bit
pattern followed by shifting off the unnecessary lowest bits.
The patch has the algorithm to calculate the factor and the shift, and
converts the code to use it.
The flag allows the user to select whether pixman-mmx.c is compiled with
-march=iwmmxt or -march=iwmmxt2.
gcc has scheduling support for the Marvell CPU in the XO 1.75 when
building with -march=iwmmxt2.
gcc has no sane way of enabling iwmmxt code generation, like -msse for
SSE, so you have to use -march=iwmmxt{,2}. User CFLAGS are placed after
-march=iwmmxt and override the march value, so we have to use a custom
build rule to order the CFLAGS such that pixman-mmx.c will be built with
the necessary CFLAGS.
Make _pixman_image_get_solid() faster by special-casing the common
cases where the image is SOLID or a repeating a8r8g8b8 image.
This optimization together with the previous one results in a small
but reproducable performance improvement on the xfce4-terminal-a1
cairo trace:
[ # ] backend test min(s) median(s) stddev. count
Before:
[ 0] image xfce4-terminal-a1 1.221 1.239 1.21% 100/100
After:
[ 0] image xfce4-terminal-a1 1.170 1.199 1.26% 100/100
Either optimization by itself is difficult to separate from noise.
Bypass much of the overhead of pixman_image_composite32() by only
computing the composite region once instead of once per glyph, and by
only looking up the composite function whenever the glyph format or
flags change.
As part of this, the pixman_compute_composite_region32() was renamed
to _pixman_compute_composite_region32() and exported in
pixman-private.h.
I couldn't find a trace that would reliably demonstrate that this is
actually an improvement by itself (since _pixman_composite_glyphs_no_mask()
is called so rarely), but together with the following optimization for
solid sources, there is a small but reliable improvement to the
xfce4-a1-terminal cairo trace.
When adding glyphs to the mask, bypass most of the overhead of
pixman_image_composite32() by:
- Only looking up the composite function when the glyph changes either
format or flags.
- Only using a white source when the glyph format is different from
the mask format.
- Simply intersecting the glyph rectangle with the destination
rectangle instead of doing the full _pixman_composite_region32().
Performance results:
[ # ] backend test min(s) median(s) stddev. count
Before:
[ 0] image firefox-talos-gfx 6.570 6.577 0.13% 8/10
After:
[ 0] image firefox-talos-gfx 4.272 4.289 0.28% 10/10
V2: Changes to deal with white sources
This test tests the new glyph cache and compositing API. Much of this
test is intending to making sure that clipping and alpha map handling
survive any optimizations that may be added to the glyph compositing.
V2: Evaluating lcg_rand_n() multiple times in an argument list lead
to undefined behavior.
When a destination image I has an alpha map A, the following rules apply:
- If I has an alpha channel itself, the content of that channel is
undefined
- If A has RGB channels, the content of those channels is
undefined.
Hence in order to compute the CRC32 for such an image, we have to mask
off the alpha channel of the image, and the RGB channels of the alpha
map.
V2: Shifting by 32 is undefined in C
This new API allows entire glyph strings to be composited in one go
which reduces overhead compared to multiple calls to
pixman_image_composite32().
The pixman_glyph_cache_t is a hash table that maps two keys (a "font"
and a "glyph" key, but they are just keys; there is no distinction
between them as far as pixman is concerned) to a glyph. Glyphs in the
cache can be composited through two new entry points
pixman_glyph_cache_composite_glyphs() and
pixman_glyph_cache_composite_glyphs_no_mask().
A glyph cache may only be inserted into when it is "frozen", which is
achieved by calling pixman_glyph_cache_freeze(). When
pixman_glyph_cache_thaw() is later called, if the cache has become too
crowded, some glyphs (currently the least-recently-used) will
automatically be evicted. This means that a user must ensure that all
the required glyphs are present in the cache before compositing a
string. The intended way to use the cache is like this:
pixman_glyph_t glyphs[MAX_GLYPHS];
pixman_glyph_cache_freeze (cache);
for (i = 0; i < n_glyphs; ++i)
{
const void *g;
if (!(g = pixman_glyph_cache_lookup (cache, font_key, glyph_key)))
{
img = <rasterize glyph as a pixman_image_t>;
g = pixman_glyph_cache_insert (cache, font_key, glyph_key,
glyph_origin_x, glyph_origin_y,
img);
if (!g)
{
/* Clean up out-of-memory condition */
goto oom;
}
glyphs[i].pos_x = glyph_x_pos;
glyphs[i].pos_y = glyph_y_pos;
glyphs[i].glyph = g;
}
}
pixman_composite_glyphs (op, src, dest, ..., cache, n_glyphs, glyphs);
pixman_glyph_cache_thaw (cache);
V2:
- Move glyphs to front of the MRU list when they are used. Pointed
out by Behdad Esfahbod.
- Composite glyphs with (white IN glyph) ADD mask in order to support
mixed a8 and a8r8g8b8 glyphs. Also pointed out by Behdad.
- Add pixman_glyph_get_mask_format
This commit adds some new inline functions to maintain a doubly linked
list.
The way to use them is to embed a pixman_link_t into the structures
that should be linked, and use a pixman_list_t as the head of the
list.
The new functions are
pixman_list_init (pixman_list_t *list);
pixman_list_prepend (pixman_list_t *list, pixman_link_t *link);
pixman_list_move_to_front (pixman_list_t *list, pixman_link_t *link);
There are also a new macro:
CONTAINER_OF(type, member, data);
that can be used to get from a pointer to a member to the containing
structure.
V2: Use the C89 macro offsetof() instead of rolling our own -
suggested by Alan Coopersmith.
Now that we have the full image flags available, the SSE2 and MMX
iterators can simply check against SAMPLES_COVER_CLIP_NEAREST (which
is computed in pixman_image_composite32()) instead of comparing all
the x/y/width/height parameters.
When pixman_image_composite32() is called some flags are computed that
indicate various things about the composite operation that can't be
deduced from the image flags themselves. These additional flags are
not currently available to iterators. All they can do is read the
image flags in image->common.flags.
Fix that by passing the info->{src, mask, dest}_flags on to the
iterator initialization and store the flags in the iter struct as
"image_flags". At the same time rename the *iterator* flags variable
to "iter_flags" to avoid confusion.
There is a couple of places where the test suite uses the
pixman_image_fill_* functions to initialize images. These functions
can fail, and will do so if the "fast" implementation is disabled.
So to make sure the test suite passes even using
PIXMAN_DISABLE="fast", use pixman_image_composite32() with a solid
image instead of pixman_image_fill_*.
In main loop (unrolled by factor 2), instead of negating multiplied
mask values by srca, values of srca was negated, and passed as alpha
argument for
UN8x4_MUL_UN8x4_ADD_UN8x4 macro.
Instead of:
ma = ~ma;
UN8x4_MUL_UN8x4_ADD_UN8x4 (d, ma, s);
Code was doing this:
ma = ~srca;
UN8x4_MUL_UN8x4_ADD_UN8x4 (d, ma, s);
Key is in substituting registers s0/s1 (containing srca value), with
t0/t1 containing mask values multiplied by srca. Register usage is
also improved (less registers are saved on stack, for
over_n_8888_8888_ca routine).
The bug was introduced in commit d2ee5631 and revealed by composite test.
If not compiling with -march=iwmmxt, the configure test will still pass,
thinking that the __builtin_arm_* intrinsic is a function instead of
generating a single instruction. Since no linking is done, the configure
test doesn't catch this, and we get linking errors in the build.
Note that 0.25.4 was a botched release that doesn't have a tag and
doesn't correspond to any commit ID. It was however uploaded and
announced, so I'll just use the 0.25.6 version number.
Otherwise we'd have -march=loongson2f being overridden by automake's
CFLAGS ordering which causes build failures when -march=<not loongson2f>
is specified by the user.
Uses the pmadd technique described in
http://software.intel.com/sites/landingpage/legacy/mmx/MMX_App_24-16_Bit_Conversion.pdf
The technique uses the packssdw instruction which uses signed
saturatation. This works in their example because they pack 888 to 555
leaving the high bit as zero. For packing to 565, it is unsuitable, so
we replace it with an or+shuffle.
Loongson:
src_8888_0565 = L1: 106.13 L2: 83.57 M: 33.46 ( 68.90%) HT: 30.29 VT: 27.67 R: 26.11 RT: 15.06 ( 135Kops/s)
src_8888_0565 = L1: 122.10 L2: 117.53 M: 37.97 ( 78.58%) HT: 33.14 VT: 30.09 R: 29.01 RT: 15.76 ( 139Kops/s)
ARM/iwMMXt:
src_8888_0565 = L1: 67.88 L2: 56.61 M: 31.20 ( 56.74%) HT: 29.22 VT: 27.01 R: 25.39 RT: 19.29 ( 130Kops/s)
src_8888_0565 = L1: 110.38 L2: 82.33 M: 40.92 ( 73.22%) HT: 35.63 VT: 32.22 R: 30.07 RT: 18.40 ( 132Kops/s)
The pinsrh instruction is analogous to MMX EXT's pinsrw, except like
other Loongson vector instructions it cannot access the general purpose
registers. In the cases of other Loongson vector instructions, this is a
headache, but it is actually a good thing here. Since the instruction is
different from MMX, I've named the intrinsic loongson_insert_pi16.
text data bss dec hex filename
25976 1952 0 27928 6d18 .libs/libpixman_loongson_mmi_la-pixman-mmx.o
25336 1952 0 27288 6a98 .libs/libpixman_loongson_mmi_la-pixman-mmx.o
-and: 181
+and: 147
-dsll: 143
+dsll: 95
-dsrl: 87
+dsrl: 135
-ldc1: 523
+ldc1: 462
-lw: 767
+lw: 721
+pinsrh: 35
The combine function was store8888'ing the result, and all consumers
were immediately load8888'ing it, causing lots of unnecessary pack and
unpack instructions.
It's a very straight forward conversion, except for mmx_combine_over_u
and mmx_combine_saturate_u. mmx_combine_over_u was testing the integer
result to skip pixels, so we use the is_* functions to test the __m64
data directly without loading it into an integer register.
For mmx_combine_saturate_u there's not a lot we can do, since it uses
DIV_UN8.
Before, if __m64 is allocated in vector or floating-point registers,
__m64 vs = ldq_u((uint64_t *)src);
would cause src to be loaded into an integer register and then
transferred to an __m64 register. By switching ldq_u's argument type to
__m64 we give the compile enough information to recognize that it can
load to the vector register directly.
This patch is necessary for the Loongson optimizations when __m64 is
typedef'd as double.
In the computation:
srtot += RED_8 (pixel) * f
RED_8 (pixel) is an unsigned quantity, which means the signed filter
coefficient f gets converted to an unsigned integer before the
multiplication. We get away with this because when the 32 bit unsigned
result is converted to int32_t, the correct sign is produced. But if
srtot had been an int64_t, the result would have been a very large
positive number.
Fix this by explicitly casting the channels to int.
The last argument must be an immediate value, and when compiling without
optimization the compiler might not recognize this. So use a macro if
not optimizing.
We're using a patched gcc-4.5, and having to modify configure.ac and
autoreconf between changes is annoying. And besides, 4.5, 4.6, and 4.7's
iwMMXt intrinsic support is equally broken, and we test a known broken
intrinsic in the configure test program, so the version check is rather
meaningless.
This function converts from a8r8g8b8 to non-premultiplied RGBA (the
PNG or GdkPixbuf format that has the channels in this order: R, G, B,
A in memory regardless of the computer's endianness). The function's
new name is a8r8g8b8_to_rgba_np().
This program can compute the projective transformation that transforms
one quadrilateral into another. The code is basically maxima[1] output
translated into C.
[1] http://maxima.sourceforge.net/
In 32 bit mode the "=A" constraint refers to the register pair
edx:eax, but according to GCC developers this is not the case in 64
bit mode, where it refers to "rax".
Hence, using "=A" for rdtsc is incorrect in 64 bit mode.
See http://gcc.gnu.org/bugzilla/show_bug.cgi?id=21249
The xmmintrin.h as shipped with recent Visual C++ (2003+) provides
_mm_shuffle_pi16 and _mm_mulhi_pu16, so including that header
will do for using these functions, and MSVC does not like the GCC-specific
implementations of _mm_shuffle_pi16 and _mm_mulhi_pu16 that is
currently in the code.
_MM_SHUFFLE is declared in the same way in MSVC's xmmintrin.h, so don't
re-define it here to avoid a compilation warning.
Silence warnings that could make -Werror give a false negative
Use signed char to avoid cases where int8_t isn't declared
Reported-by: Mike Lothian <mike@fireburn.co.uk>
Tested-by: Mike Lothian <mike@fireburn.co.uk>
Reviewed-by: Matt Turner <mattst88@gmail.com>
Signed-off-by: Jeremy Huddleston <jeremyhu@apple.com>
This code was pretty much coppied from a similar commit that I made to
xorg-server in April.
cf: xorg/xserver: bb4d145bd25e2aee988b100ecf1105ea3b6a40b8
Signed-off-by: Jeremy Huddleston <jeremyhu@apple.com>
Since the Solaris Studio compilers don't have a mode where MMX
instructions are available and SSE instructions are not, we can
just use the <xmmintrin.h> header directly.
Fixes build failure due to Studio not supporting the __gnu_inline__
or __artificial__ attributes.
Signed-off-by: Alan Coopersmith <alan.coopersmith@oracle.com>
Acked-by: Matt Turner <mattst88@gmail.com>
With this, it becomes possible to do
PIXMAN_DISABLE="sse2 mmx" some_app
which will run some_app without SSE2 and MMX enabled. This is useful
for benchmarking, testing and narrowing down bugs.
The current list of implementations that can be disabled:
fast
mmx
sse2
arm-simd
arm-iwmmxt
arm-neon
mips-dspr2
vmx
The general and noop implementations can't be disabled because pixman
depends on those being available for correct operation.
Reviewed-by: Matt Turner <mattst88@gmail.com>
There are several issues with the Clang compiler and pixman-mmx.c:
- When not optimizing, it doesn't seem to recognize that an argument
to an __always_inline__ function is compile-time constant. This
results in this error being produced:
fatal error: error in backend: Invalid operand for inline asm
constraint 'K'!
- This inline assembly:
asm ("pmulhuw %1, %0\n\t"
: "+y" (__A)
: "y" (__B)
);
results in
fatal error: error in backend: Unsupported asm: input constraint
with a matching output constraint of incompatible type!
So disable MMX when the compiler is Clang.
Allows us to tune how we load data into the vector registers.
Signed-off-by: Matt Turner <mattst88@gmail.com>
And squashed in:
mmx: define and use load8888u function
For unaligned loads.
Signed-off-by: Matt Turner <mattst88@gmail.com>
It used to be slower than the generic code (with the gcc that was
current in 2007), but that doesn't seem to be the case anymore:
over_x888_8_8888 = L1: 22.97 L2: 22.88 M: 22.27 ( 5.29%) HT: 18.30 VT: 15.81 R: 15.54 RT: 10.35 ( 131Kops/s)
over_x888_8_8888 = L1: 53.56 L2: 53.20 M: 50.50 ( 11.99%) HT: 38.60 VT: 31.19 R: 29.00 RT: 17.37 ( 208Kops/s)
Reviewed-by: Matt Turner <mattst88@gmail.com>
The pshufw x86 instruction is part of Extended 3DNow! and SSE1. The
equivalent ARM wshufh instruction was available from the first iwMMXt
instrucion set.
This instruction is already used in the SSE2 code.
Reduces code size by ~9%.
amd64
text data bss dec hex filename
29925 2240 0 32165 7da5 .libs/libpixman_mmx_la-pixman-mmx.o
27237 2240 0 29477 7325 .libs/libpixman_mmx_la-pixman-mmx.o
x86
text data bss dec hex filename
27677 1792 0 29469 731d .libs/libpixman_mmx_la-pixman-mmx.o
24959 1792 0 26751 687f .libs/libpixman_mmx_la-pixman-mmx.o
arm
text data bss dec hex filename
30176 1792 0 31968 7ce0 .libs/libpixman_iwmmxt_la-pixman-mmx.o
27384 1792 0 29176 71f8 .libs/libpixman_iwmmxt_la-pixman-mmx.o
Signed-off-by: Matt Turner <mattst88@gmail.com>
The pmulhuw x86 instruction is part of Extended 3DNow! and SSE1. The
equivalent ARM wmuluh instruction was available from the first iwMMXt
instrucion set.
This instruction is already used in the SSE2 code.
Reduces code size by ~5%.
amd64
text data bss dec hex filename
31325 2240 0 33565 831d .libs/libpixman_mmx_la-pixman-mmx.o
29925 2240 0 32165 7da5 .libs/libpixman_mmx_la-pixman-mmx.o
x86
text data bss dec hex filename
29165 1792 0 30957 78ed .libs/libpixman_mmx_la-pixman-mmx.o
27677 1792 0 29469 731d .libs/libpixman_mmx_la-pixman-mmx.o
arm
text data bss dec hex filename
31632 1792 0 33424 8290 .libs/libpixman_iwmmxt_la-pixman-mmx.o
30176 1792 0 31968 7ce0 .libs/libpixman_iwmmxt_la-pixman-mmx.o
Signed-off-by: Matt Turner <mattst88@gmail.com>
Allows you to compile without -flax-vector-conversions in your CFLAGS,
though -march=iwmmxt2 is still necessary since specifying some other
-march= value will override it, and disable iwmmxt.
Signed-off-by: Matt Turner <mattst88@gmail.com>
Cairo 1.10 will sometimes generate trapezoids like this, so we can't
consider them invalid. Fixes bug 45009, reported by Michael Biebl.
This reverts commit 2437ae80e5.
Cairo 1.10 will sometimes generate trapezoids like this, so we can't
consider them invalid. Fixes bug 45009, reported by Michael Biebl.
This reverts commit 2437ae80e5.
The alpha channel from the alpha map must be inserted as the new alpha
channel when a scanline is fetched from an image. Previously the alpha
map would overwrite the buffer instead. This wasn't caught be the
alpha map test because it would only verify that the resulting alpha
channel was correct, and not pay attention to incorrect color
channels.
Rearranged some of the existing gcc & Intel compiler checks to allow
easier sharing of common cases among the compilers.
Signed-off-by: Alan Coopersmith <alan.coopersmith@oracle.com>
When a trapezoid has a top/bottom that is above/below the left/right
edges, degenerate trapezoids become possible. For example the edge
could be very short and close to horizontal. If the bottom edge is far
below the bottom point of such a short edge, the result is that the
lower right corner of the trapezoid will be extremely far to the left.
This kind of trapezoid causes overflows in the rasterization code, so
change pixman_trapezoid_valid() to reject them.
In the macros for the PDF blend modes, two comp1_t variables are
multiplied together and then used as if the result were a
comp4_t. When comp1_t is a uint8_t, this is fine because they are
promoted to int, and the product of two uint8_ts fits in an
int. However, when comp1_t is uint16, the product does not necessarily
fit in an int, so casts are necessary.
Fix for bug 43906, reported by Siarhei Siamashka.
A parenthesis was misplaced so that the size argument to memcmp() was
always 0. The bug is harmless except that the flags might be
unnecessarily recomputed in some cases.
A bug reporting this in Mozilla's fork was discovered here:
https://bugzilla.mozilla.org/show_bug.cgi?id=710992
ec7c9c2b68 introduced a bug where NONE gradients would be
misrendered, causing the area outside the gradient to be treated as a
(very) long fade to transparent.The problem was that a check for
positions outside the gradients were dropped in favor of relying on
the sentinels.
Aside from misrendering, this also caused a signed integer overflow
when the code would compute a stepper size based on MIN_INT32.
This patches fixes the issue by reinstating a check for these cases
and setting both the right and left colors to transparent black.
This patch adds runtime detection support for the ARM NEON fast paths
for code compiled with the Android NDK. This is the only code change
needed to enable the ARM NEON pixman fast paths for the ever growing
Android platform (200 million+ smartphones, tablets, etc.). Just make
sure to #define USE_ARM_NEON in your makefile.
Add a new pixel_checker_t object to test/utils.[ch]. This object
should be initialized with a format and can then be used to check
whether a given "real" pixel in that format is close enough to a
"perfect" pixel given as a double precision ARGB struct.
The acceptable deviation is calcuated as follows. Each channel of the
perfect pixel has 0.004 subtracted from it and is then converted to
the format. The resulting value is the minimum value that will be
accepted. Similarly, to compute the maximum value, the channel has
0.004 added to it and is then converted to the given format. Checking
a pixel is then a matter of splitting it into channels and checking
that each is within the computed bounds.
The value of 0.004 was chosen because it is the minimum one that will
make the existing composite test pass (see next commit). A problem
with this value is that it causes 0xFE to be acceptable when the
correct value is 1.0, and 0x01 to be acceptable when the correct value
is 0. It would be better if, when the result is exactly 0 or exactly
1, an a8r8g8b8 pixel were required to produce exactly 0x00 or 0xff to
preserve full black and full white. A deviation value of 0.003 would
produce this, but currently this would cause tests with operators that
involve divisions to fail.
Add a new function _pixman_implementation_lookup_combiner() that will
find a usable combiner given an operator and information about whether
the combiner should apply component alpha and whether it should be 64
bit.
In pixman-general.c use this function to look up a combiner up front
instead of walking the delegate chain for every scanline.
When making the copy of the destination, do so separately for the
image and the alpha map. This ensures that the alpha channel of the
alpha map will be different from the alpha channel of the actual
image.
Previously, orig_dst would be copied onto dst along with its alpha
map, which mean that the alpha map of orig_dst would become the new
alpha channel of *both* dst and dst's alpha map. This meant that test
didn't actually test that the alpha maps alpha channel was actually
fetched.
The alpha channel from the alpha map must be inserted as the new alpha
channel when a scanline is fetched from an image. Previously the alpha
map would overwrite the buffer instead. This wasn't caught be the
alpha map test because it would only verify that the resulting alpha
channel was correct, and not pay attention to incorrect color
channels.
Rearranged some of the existing gcc & Intel compiler checks to allow
easier sharing of common cases among the compilers.
Signed-off-by: Alan Coopersmith <alan.coopersmith@oracle.com>
When a trapezoid has a top/bottom that is above/below the left/right
edges, degenerate trapezoids become possible. For example the edge
could be very short and close to horizontal. If the bottom edge is far
below the bottom point of such a short edge, the result is that the
lower right corner of the trapezoid will be extremely far to the left.
This kind of trapezoid causes overflows in the rasterization code, so
change pixman_trapezoid_valid() to reject them.
In pixman-fast-path.c: (1 << 31) - 1 causes a signed overflow, so
change to (1U << n) - 1.
In pixman-image.c: The check for whether m10 == -m01 will overflow
when -m01 == INT_MIN. Instead just check whether the variables are 1
and -1.
In pixman-utils.c: When the depth of the topmost channel is 0, we can
end up shifting by 32.
In blitters-test.c: Replicating the mask would end up shifting more
than 32.
In region-contains-test.c: Computing the average of two large integers
could overflow. Instead add half the difference between them to the
first integer.
In stress-test.c: Masking the value in fake_reader() would sometimes
shift by 32. Instead just use the most significant bits instead of
the least significant.
All these issues were found by the IOC tool:
http://embed.cs.utah.edu/ioc/
In the macros for the PDF blend modes, two comp1_t variables are
multiplied together and then used as if the result were a
comp4_t. When comp1_t is a uint8_t, this is fine because they are
promoted to int, and the product of two uint8_ts fits in an
int. However, when comp1_t is uint16, the product does not necessarily
fit in an int, so casts are necessary.
Fix for bug 43906, reported by Siarhei Siamashka.
A parenthesis was misplaced so that the size argument to memcmp() was
always 0. The bug is harmless except that the flags might be
unnecessarily recomputed in some cases.
A bug reporting this in Mozilla's fork was discovered here:
https://bugzilla.mozilla.org/show_bug.cgi?id=710992
ec7c9c2b68 introduced a bug where NONE gradients would be
misrendered, causing the area outside the gradient to be treated as a
(very) long fade to transparent.The problem was that a check for
positions outside the gradients were dropped in favor of relying on
the sentinels.
Aside from misrendering, this also caused a signed integer overflow
when the code would compute a stepper size based on MIN_INT32.
This patches fixes the issue by reinstating a check for these cases
and setting both the right and left colors to transparent black.
This patch modifies demos/gradient-test to display a bug in gradients
with a repeat mode of NONE. With the current gradient code, the left
side will be a solid red (actually an extremely long fade from solid
red to transparent) instead of a sharp transition from red to green.
This patch adds runtime detection support for the ARM NEON fast paths
for code compiled with the Android NDK. This is the only code change
needed to enable the ARM NEON pixman fast paths for the ever growing
Android platform (200 million+ smartphones, tablets, etc.). Just make
sure to #define USE_ARM_NEON in your makefile.
Tweak the commands used to run the tests on win32 to make the output
look mostly like that produced by the autotools test system.
In addition to this, make sure that the exit status of the test target
is success (0) if and only if no failure occurred.
This patch has been generated by the following Coccinelle semantic patch:
// Use the ARRAY_LENGTH() macro when possible
//
// Replace open-coded array length computations with the
// ARRAY_LENGTH() macro
@@
type T;
T[] E;
@@
- (sizeof(E)/sizeof(T))
+ ARRAY_LENGTH (E)
All the tests are linked to libutil, hence it makes sence to always
include utils.h and reuse what it provides (config.h inclusion, access
to private pixman APIs, ARRAY_LENGTH, ...).
This patch has been generated by the following Coccinelle semantic patch:
// Remove useless checks for NULL before freeing
//
// free (NULL) is a no-op, so there is no need to avoid it
@@
expression E;
@@
+ free (E);
+ E = NULL;
- if (unlikely (E != NULL)) {
- free(E);
(
- E = NULL;
|
- E = 0;
)
...
- }
@@
expression E;
@@
+ free (E);
- if (unlikely (E != NULL)) {
- free (E);
- }
Sun/Oracle Studio compilers allow the pointers to be cast, but not the
non-pointer forms, causing pixman compiles to fail with many errors of:
"pixman-mmx.c", line 1411: invalid cast expression
Signed-off-by: Alan Coopersmith <alan.coopersmith@oracle.com>
In pixman-noop.c and pixman-sse2.c, we are accessing
image->bits.width/height without first making sure the image is a bits
image. The warning is harmless because we never act on this
information without checking that the image is a8r8g8b8, but valgrind
does warn about it.
In pixman-noop.c, just reorder the clauses in the if statement; in
pixman-sse2.c require images to have the FAST_PATH_BITS_IMAGE flag
set.
Binutils 2.21 does not complain about missing comma between ARM
register and alignement specifier in vld/vst instructions which
causes build error on binutils 2.20.
Instructions are reordered to eliminate pipeline stalls and get
better memory access.
Performance of before/after on cortex-a8 @ 1GHz
<< 2000 x 2000 with scale factor close to 1.x >>
before : 40.53 Mpix/s
after : 50.76 Mpix/s
Instructions are reordered to eliminate pipeline stalls and get
better memory access.
Performance of before/after on cortex-a8 @ 1GHz
<< 2000 x 2000 with scale factor close to 1.x >>
before : 50.43 Mpix/s
after : 61.09 Mpix/s
This macro template takes 6 code blocks.
1. process_last_pixel
2. process_two_pixels
3. process_four_pixels
4. process_pixblock_head
5. process_pixblock_tail
6. process_pixblock_tail_head
process_last_pixel does not need to update horizontal weight. This
is done by the template. two and four code block should update
horizontal weight inside of them. head/tail/tail_head blocks
consist unrolled core loop. You can apply instruction scheduling
to the tail_head blocks.
You can also specify size of the pixel block. Supported size is 4
and 8. If you want to use mask, give BILINEAR_FLAG_USE_MASK flags
to the template, then you can use register MASK. When using d8~d15
registers, give BILINEAR_FLAG_USE_ALL_NEON_REGS to make sure
registers are properly saved on the stack and later restored.
The code that searches for the closest color stop to the given
position is duplicated across the various repeat modes. Replace the
switch with two if/else constructions, and put the search code between
them.
When storing the gradient stops internally, allocate two more stops,
one before the beginning of the stop list and one after the
end. Initialize those stops based on the repeat property of the
gradient.
This allows gradient_walker_reset() to be simplified because it can
now simply pick the two closest stops to the position without special
casing the first and last stops.
The type of pos in gradient_walker_reset() and gradient_walker_pixel()
is pixman_fixed_48_16_t and not pixman_fixed_32_32. The types of the
positions in the walker struct are pixman_fixed_t and not int32_t, and
need_reset is a boolean, not an integer. The spread field should be
called repeat and have the type pixman_repeat_t.
Also fix some formatting issues, make gradient_walker_reset() static,
and delete the pointless PIXMAN_GRADIENT_WALKER_NEED_RESET() macro.
Too short scanlines can cause repeat handling overhead and optimized
pixman composite functions usually process a bunch of pixels in a
single loop iteration it might be beneficial to pre-extend source
scanlines. The temporary buffers will usually reside in cache, so
accessing them should be quite efficient.
We can implement simple repeat by stitching existing fast path
functions. First lookup COVER_CLIP function for given input and
then stitch horizontally using the function.
These flags are useful in the various compositing routines, and the
flags stored in the image structs are missing some bits of information
that can only be computed when pixman_image_composite() is called.
pixman_image_t itself can be on stack or heap. So segregating
init/fini from create/unref can be useful when we want to use
pixman_image_t on stack or other memory.
Primitive bilinear interpolation code is reusable to implement other
bilinear functions.
BILINEAR_DECLARE_VARIABLES
- Declare variables needed to interpolate src pixels.
BILINEAR_INTERPOLATE_ONE_PIXEL
- Interpolate one pixel and advance to next pixel
BILINEAR_SKIP_ONE_PIXEL
- Skip interpolation and just advance to next pixel
This is useful for skipping zero mask
iwMMXt is incorrectly detected on x86 and amd64. This happens because
the test uses standard _mm_* intrinsic functions which it compiles with
-march=iwmmxt, but when the user has set CFLAGS=-march=k8 for instance,
no error is generated from -march=iwmmxt, even though it's not a valid
flag on x86/amd64. Passing CFLAGS=-march=native does not override the
-march=iwmmxt flag though, which is why it wasn't noticed before.
So, just #error out in the test if the __arm__ preprocessor directive
isn't defined.
Fixes https://bugs.gentoo.org/show_bug.cgi?id=385179
Signed-off-by: Matt Turner <mattst88@gmail.com>
Check in configure for at least gcc-4.6, since gcc-4.7 (and hopefully
4.6) will be the eariest version capable of compiling the _mm_*
intrinsics on ARM/iwmmxt. Even for suitable compile versions I use
_mm_srli_si64 which is known to cause unpatched compilers to fail.
Select iwmmxt at runtime only after NEON, since we expect the NEON
optimizations to be more capable and faster than iwmmxt.
Signed-off-by: Matt Turner <mattst88@gmail.com>
Simply return *p in the unaligned access functions, since alignment
constraints are very relaxed on x86 and this allows us to generate
identical code as before.
Tested with the test suite, lowlevel-blit-test, and cairo-perf-trace on
ARM and Alpha with no unaligned accesses found.
Signed-off-by: Matt Turner <mattst88@gmail.com>
gcc isn't able to see that w is no greater than 1, so it generates
unnecessary loop instructions with while (w).
Signed-off-by: Matt Turner <mattst88@gmail.com>
An image with a bilinear filter and an identity transform is
equivalent to one with a nearest filter, so there is no reason the
standard fast paths shouldn't be usable.
But because a BILINEAR filter samples a 2x2 pixel block in the source
image, FAST_PATH_SAMPLES_COVER_CLIP can't be set in the case where the
source area is the entire image, because some compositing operations
might then read pixels outside the image.
This patch fixes the problem by splitting the
FAST_PATH_SAMPLES_COVER_CLIP flag into two separate flags
FAST_PATH_SAMPLES_COVER_CLIP_NEAREST and
FAST_PATH_SAMPLES_COVER_CLIP_BILINEAR that indicate that the clip
covers the samples taking into account NEAREST/BILINEAR filters
respectively.
All the existing compositing operations that require
FAST_PATH_SAMPLES_COVER_CLIP then have their flags modified to pick
either COVER_CLIP_NEAREST or COVER_CLIP_BILINEAR depending on which
filter they depend on.
In compute_image_info() both COVER_CILP_NEAREST and
COVER_CLIP_BILINEAR can be set depending on how much room there is
around the clip rectangle.
Finally, images with an identity transform and a bilinear filter get
FAST_PATH_NEAREST_FILTER set as well as FAST_PATH_BILINEAR_FILTER.
Performance measurementas with render_bench against Xephyr:
Before
*** ROUND 1 ***
---------------------------------------------------------------
Test: Test Xrender doing non-scaled Over blends
Time: 5.720 sec.
---------------------------------------------------------------
Test: Test Xrender (offscreen) doing non-scaled Over blends
Time: 5.149 sec.
---------------------------------------------------------------
Test: Test Imlib2 doing non-scaled Over blends
Time: 6.237 sec.
After:
*** ROUND 1 ***
---------------------------------------------------------------
Test: Test Xrender doing non-scaled Over blends
Time: 4.947 sec.
---------------------------------------------------------------
Test: Test Xrender (offscreen) doing non-scaled Over blends
Time: 4.487 sec.
---------------------------------------------------------------
Test: Test Imlib2 doing non-scaled Over blends
Time: 6.235 sec.
The upcoming optimization which is going to be able to replace BILINEAR filter
with NEAREST where appropriate needs to analyze the transformation matrix
and not to make any mistakes.
The changes to affine-test include:
1. Higher chance of using the same scale factor for x and y axes. This can help
to stress some special cases (for example the case when both x and y scale
factors are integer). The same applies to x/y translation.
2. Introduced a small chance for "corrupting" transformation matrix by flipping
random bits. This supposedly can help to identify the cases when some of the
fast paths or other code logic is wrongly activated due to insufficient checks.
In analyze_extents(), instead of calling compute_sample_extents() call
compute_transformed_extents() and inline the remaining part of
compute_sample_extents(). The upcoming bilinear->nearest optimization
will do something different with these two pieces of code.
compute_sample_extents() have two parts: one that computes the
transformed extents, and one that checks whether the computed extents
fit within the 16.16 coordinate space.
Split the first part into its own function
compute_transformed_extents().
These coordinates were only ever used for subtracting from the extents
box to put it into the coordinate space of the image, so we might as
well do this coordinate translation only once before entering the
functions.
Add support in convert_pixel_from_a8r8g8b8() and
convert_pixel_to_a8r8g8b8() for conversion to/from paletted formats,
then use MAKE_ACCESSORS() to generate accessors for the indexed
formats: c8, g8, g4, c4, g1
Add FETCH_1 and STORE_1 macros and use them to add support for 1bpp
pixels to fetch_and_convert_pixel() and convert_and_store_pixel(),
then use MAKE_ACCESSORS() to generate the accessors for the a1
format. (Not the g1 format as it is indexed).
Add FETCH_24 and STORE_24 macros and use them to add support for 24bpp
pixels in fetch_and_convert_pixel() and
convert_and_store_pixel(). Then use MAKE_ACCESSORS() to generate
accessors for the 24 bpp formats:
r8g8b8
b8g8r8
Use FETCH_4 and STORE_4 macros to add support for 4bpp pixels to
fetch_and_convert_pixel() and convert_and_store_pixel(), then use
MAKE_ACCESSORS() to generate accessors for 4 bpp formats, except g4 and
c4 which are indexed:
a4
r1g2b1
b1g2r1
a1r1g1b1
a1b1g1r1
Add support for 8 bpp formats to fetch_and_convert_pixel() and
convert_and_store_pixel(), then use MAKE_ACCESSORS() to generate the
accessors for all the 8 bpp formats, except g8 and c8, which are
indexed:
a8
r3g3b2
b2g3r3
a2r2g2b2
a2b2g2r2
x4a4
Add support for 16bpp pixels to fetch_and_convert_pixel() and
convert_and_store_pixel(), then use MAKE_ACCESSORS() to generate
accessors for all the 16bpp formats:
r5g6b5
b5g6r5
a1r5g5b5
x1r5g5b5
a1b5g5r5
x1b5g5r5
a4r4g4b4
x4r4g4b4
a4b4g4r4
x4b4g4r4
Add support for 32bpp formats in fetch_and_convert_pixel() and
convert_and_store_pixel(), then use MAKE_ACCESSORS() to generate
accessors for all the 32 bpp formats:
a8r8g8b8
x8r8g8b8
a8b8g8r8
x8b8g8r8
x14r6g6b6
b8g8r8a8
b8g8r8x8
r8g8b8x8
r8g8b8a8
This macro will eventually allow the fetchers and storers to be
generated automatically. For now, it's just a skeleton that doesn't
actually do anything.
This function can convert between normalized numbers of different
depths. When converting to higher bit depths, it will replicate the
existing bits, when converting to lower bit depths, it will simply
truncate.
This function replaces the expand16() function in pixman-utils.c
The boxes used region_contains_test() sometimes overflow causing
*** BUG ***
In pixman_region32_union_rect: Invalid rectangle passed
Set a breakpoint on '_pixman_log_error' to debug
messages to be printed when pixman is compiled with DEBUG. Fix this by
dividing the x, y, w, h coordinates by 4 to prevent overflows.
On win32 the tests are built but they are not run automatically by the
build system.
A minimal 'check' target (depending on the tests being built) can
simply run them and log to the console their success/failure.
The win32 build system does not generate config.h and correctly runs
the compiler without defining HAVE_CONFIG_H. Nevertheless some files
include config.h without checking for its availability, breaking the
build from a clean directory:
test\utils.h(2) : fatal error C1083: Cannot open include file:
'config.h': No such file or directory
...
The win32 build system repeatedly defines some basic variables
(notably program names and flags) and C sources compilation rules.
They can be factored out to a common Makefile, to be included in every
other Makefile.win32.
Makefile.am and Makefile.win32 should not duplicate content, as this
leads to breaking the build when they are not kept in sync.
This can be avoided by listing sources, headers and common build
variables/rules in a Makefile.sources file.
In order to further simplify the test makefiles, the utility functions
are now in a static library, which gets linked to all the tests and
benchmarks.
Makefile.am and Makefile.win32 should not duplicate content, as this
leads to breaking the build when they are not kept in sync.
This can be avoided by listing sources, headers and common build
variables/rules in a Makefile.sources file.
Adding scaling-helpers-test to the testsuite on win32 makes MSVC
complain about int64_t being used as an expression:
scaling-helpers-test.c(27) : error C2275: 'int64_t' : illegal use of
this type as an expression
When debugging it is often very useful to be able to save an image as
a png file. This commit adds a function "write_png()" that does that.
If libpng is not available, then the function becomes a noop.
Profiling ign.com, 20% of the entire render time was absorbed in this
single operation:
<< /content //COLOR_ALPHA /width 480 /height 800 >> surface context
<< /width 1 /height 677 /format //ARGB32 /source <|!!!@jGb!m5gD']#$jFHGWtZcK&2i)Up=!TuR9`G<8;ZQp[FQk;emL9ibhbEL&NTh-j63LhHo$E=mSG,0p71`cRJHcget4%<S\X+~> >> image pattern
//EXTEND_REPEAT set-extend
set-source
n 0 0 480 677 rectangle
fill+
pop
which is a simple composition of a single pixel wide image. Sadly this
is a workaround for lack of independent repeat-x/y handling in cairo and
pixman. Worse still is that the worst-case behaviour of the general repeat
path is for width 1 images...
Signed-off-by: Chris Wilson <chris@chris-wilson.co.uk>
llvm-gcc (shipped in Apple XCode 4.1.1 as the default compiler or in
the 2.9 release of LLVM) performs an invalid optimization which
unifies the empty_region and the bad_region structures because they
have the same content.
A bugreport has been filed against Apple Developers Tool for this
issue. This commit works around this bug by making one of the two
structures volatile, so that it cannot be merged.
Fixes region-contains-test.
There is no reason for pixman_image_create_bits() to check that the
image size fits in int32_t. The correct check is against size_t since
that is what the argument to calloc() is.
This patch fixes this by adding a new _pixman_multiply_overflows_size()
and using it in create_bits(). Also prepend an underscore to the names
of other similar functions since they are internal to pixman.
V2: Use int, not ssize_t for the arguments in create_bits() since
width/height are still limited to 32 bits, as pointed out by Chris
Wilson.
The same binary search from the previous commit can be used in this
function too.
V2: Remove check from loop that is not needed anymore, pointed out by
Andrea Canciani.
When someone selects some text in Firefox under a non-composited X
server and initiates a drag, a shaped window is created with a complex
shape corresponding to the outline of the text. Then, on every mouse
movement pixman_region_contains_rectangle() is called many times on
that complicated region. And pixman_region_contains_rectangle() is
doing a linear scan through the rectangles in the region, although the
scan does exit when it finds the first box that can't possibly
intersect the passed-in rectangle.
This patch changes the loop so that it uses a binary search to skip
boxes that don't overlap the current y position. The performance
improvement for the text dragging case is easily noticable.
V2: Use the binary search for the "getting up to speed or skippping
remainder of band" as well.
This test generates random regions and checks whether random boxes and
points are contained within them. The results are combined and a CRC32
value is computed and compared to a known-correct one.
The lcg_rand() function only returns 15 random bits, so lcg_rand_u32()
would always have 0 in bit 31 and bit 15. Fix that by calling
lcg_rand() three times, to generate 15, 15, and 2 random bits
respectively.
V2: Use the 10/11 most significant bits from the 3 lcg results and mix
them with the low ones from the adjacent one, as suggested by Andrea
Canciani.
The necessity is justified by a message in the pixman mailing list:
http://lists.freedesktop.org/archives/pixman/2011-July/001330.html
NONE repeat is not supported, but could be added by tweaking
the interpretation and making use of 'fully_transparent_src'
scanline function argument.
Add a comment to explain why the tests guarantee that the code always
computes the greatest valid root.
Rename "det" as "discr" to make it match the mathematical name
"discriminant".
Based on a patch by Jeff Muizelaar <jmuizelaar@mozilla.com>.
To avoid function call and other calculation overhead, extend source
scanline into temporary buffer when source width is too small.
Temporary buffer will be repeatedly accessed, so extension cost is
very small due to cache effect.
Now bilinear template support REPEAT_NORMAL, so functions for that
is added to PIXMAN_ARM_BIND_SCALED_BILINEAR_ macros. Fast path
entries are not enabled yet.
The basic idea is to break down normal repeat into a set of
non-repeat scanline compositions and stitching them together.
Bilinear may interpolate last and first pixels of source scanline.
In this case, we can use temporary wrap around buffer.
By replacing boolean arguments with flags, the code can be more
readable and flags can be extended to do some more things later.
Currently following flags are defined.
FLAG_NONE
- No flags are turned on.
FLAG_HAVE_SOLID_MASK
- Template will generate solid mask composite functions.
FLAG_HAVE_NON_SOLID_MASK
- Template will generate bits mask composite functions.
FLAG_HAVE_SOLID_MASK and FLAG_NON_SOLID_MASK should be mutually
exclusive.
The first bug is that a vmull.u8 instruction would store its result in
the q1 register, clobbering the d2 register used later on. The second
is that a vraddhn instruction would overwrite d25, corrupting the q12
register used later.
Fixing the second bug caused a pipeline bubble where the d18 register
would be unavailable for a clock cycle. This is fixed by swapping the
instruction with its successor.
Move the eight most common formats to the top of the list of image
formats and make create_random_image() much more likely to select one
of those eight formats.
This should help catch more bugs in SIMD optimized operations.
Autoconf 2.86 reports:
warning: AC_LANG_CONFTEST: no AC_LANG_SOURCE call detected in body
Every code fragment must be wrapped in [AC_LANG_SOURCE([...])]
The variables in question were dst_x, dst_y, dst_image. The majority
of _x and _y uses were already dest_x and dest_y, while the majority
of _image uses were dst_image.
When the image is a8r8g8b8 and not transformed, and the fetched
rectangle is within the image bounds, scanlines can be fetched by
simply returning a pointer instead of copying the bits.
It will at some point become useful to have CPU specific destination
iterators. However, a problem with that, is that such iterators should
not be used if we can composite directly in the destination image.
By moving the noop destination iterator to the noop implementation, we
can ensure that it will be chosen before any CPU specific iterator.
The DST operator doesn't actually do anything, so add a noop "fast
path" for it, instead of checking in pixman_image_composite32().
The performance tradeoff here is that we get rid of a test for DST in
the common case where the operator is not DST, in return for an extra
walk over the clip rectangles in the uncommon case where the operator
actually is DST.
This new implementation is ahead of all other implementations in the
fallback chain and is supposed to contain operations that are "noops",
ie., they don't require any work. For example, it might contain a
"fast path" for the DST operator that doesn't actually do anything or
an iterator for a8r8g8b8 that just returns a pointer into the image.
General fetch->combine->store based bilinear scanline functions.
Need further optimizations and eventually will be replaced with optimal
functions one by one.
General functions should be located in pixman-arm-neon-asm-bilinear.S and
optimal functions in pixman-arm-neon-asm.S
Following general bilinear scanline functions are implemented
over_8888_8888
add_8888_8888
src_8888_8_8888
src_8888_8_0565
src_0565_8_x888
src_0565_8_0565
over_8888_8_8888
add_8888_8_8888
Previously, this function would do coordinate calculations in such a
way that (x_dst, y_dst) would only affect the alignment of the source
image, but not of the traps, which would always be considered to be in
absolute destination coordinates. This is unlike the
pixman_image_composite() function which also registers the mask to the
destination.
This patch makes it so that traps are also offset by (x_dst, y_dst).
Also add a comment explaining how this function is supposed to
operate, and update tri-test.c and composite-trap-test.c to deal with
the new semantics.
This improves the performance of the firefox-talos-gfx benchmark with
the image16 backend. Benchmark on an 800 MHz ARM Cortex A8:
Before:
[ # ] backend test min(s) median(s) stddev. count
[ 0] image16 firefox-talos-gfx 121.773 122.218 0.15% 6/6
After:
[ # ] backend test min(s) median(s) stddev. count
[ 0] image16 firefox-talos-gfx 85.247 85.563 0.22% 6/6
V2: Slightly better instruction scheduling based on comments from Taekyun Kim.
V3: Eliminate all stalls from the inner loop. Also based on comments from Taekyun Kim.
PIXMAN_LINK_WITH_ENV did not fail unless -Wall -Werror is used.
So even when the compiler did not support OpenMP, USE_OPENMP was defined.
Fix that by running the second OpenMP test only when first AC_OPENMP find supported
configure tested in the cases :
gcc without libgomp support, no openmp option, --enable-openmp and --disable-openmp
gcc with libgomp support, no openmp option, --enable-openmp and --disable-openmp
Not tested with autoconf version not knowing openmp (<2.62)
Warn when --enable-openmp is requested but no support is found
Signed-off-by: Gilles Espinasse <g.esp@free.fr>
Performance of the inner loop when working with the data in L1 cache:
ARM Cortex-A8: 41 cycles per 4 pixels (no stalls and partial dual issue)
ARM Cortex-A9: 48 cycles per 4 pixels (no stalls)
It might be still possible to improve performance even more on ARM Cortex-A8
with a better use of dual issue.
Benchmark on ARM Cortex-A8 r1p3 @600MHz, 32-bit LPDDR @166MHz:
Microbenchmark (scaling 2000x2000 image with scale factor close to 1x):
before: op=1, src=20028888, dst=20028888, speed=40.38 MPix/s
after: op=1, src=20028888, dst=20028888, speed=48.47 MPix/s
Benchmark on ARM Cortex-A8 r2p2 @1GHz, 32-bit LPDDR @200MHz:
Microbenchmark (scaling 2000x2000 image with scale factor close to 1x):
before: op=1, src=20028888, dst=20028888, speed=79.68 MPix/s
after: op=1, src=20028888, dst=20028888, speed=93.11 MPix/s
Now an extra 'flag' parameter is supported in bilinear scaline scaling
function generation macro. It can be used to enable 4 or 8 pixels per
loop iteration unrolling and provide save/restore code for d8-d15
registers.
Moving horizontal interpolation weights update instructions from the
beginning of loop to its end allows to hide some pipeline stalls and
improve performance.
Instead of two
mvn d24, d24
mvn d25, d25
use just one
mvn q12, q12
Also move another vmvn instruction into the created pipeline bubble,
as pointed out by Siarhei.
Up until now, all pixman release, both snapshots and releases were
uploaded to the "releases" directory on www.cairographics.org, but
it's better to development snapshots in the "snapshots" directory.
This patch changes Makefile.am to do that.
When run in PIXMAN_RANDOMIZE_TESTS mode, this test would go into an
infinite loop because the loop started at 'seed' but the stop
condition was still N_TESTS.
This format is particularly useful on big-endian architectures, where RGBA in
memory/file order corresponds to r8g8b8a8 as an uint32_t. This is important
because RGBA is in some cases the only available choice (for example as a pixel
format in OpenGL ES 2.0).
This patch makes so that composite and stress-test will start from a
random seed if the PIXMAN_RANDOMIZE_TESTS environment variable is
set. Running the test suite in this mode is useful to get more test
coverage.
Also, in stress-test.c make it so that setting the initial seed causes
threads to be turned off. This makes it much easier to see when
something fails.
All of the information previously passed to the iterator initializers
is now available in the iterator itself, so there is no need to pass
it as arguments anymore.
This makes _pixman_implementation_{src,dest}_iter_init() responsible
for filling parts of the information in the iterators. Specifically,
the information passed as arguments is stored in the iterator.
Also add a height field to pixman_iter_t().
There is no reason to go through
_pixman_implementation_{src,dest}_iter_init(), especially since
_pixman_implementation_src_iter_init() is doing various other checks
that only need to be done once.
Also call delegate->src_iter_init() directly in pixman-sse2.c
Instructions scheduling improved in the code responsible for fetching r5g6b5
pixels and converting them to the intermediate x8r8g8b8 color format used in
the interpolation part of code. Still a lot of NEON stalls are remaining,
which can be resolved later by the use of pipelining.
Benchmark on ARM Cortex-A8 r2p2 @1GHz, 32-bit LPDDR @200MHz:
Microbenchmark (scaling 2000x2000 image with scale factor close to 1x):
before: op=1, src=10020565, dst=10020565, speed=32.29 MPix/s
op=1, src=10020565, dst=20020888, speed=36.82 MPix/s
after: op=1, src=10020565, dst=10020565, speed=41.35 MPix/s
op=1, src=10020565, dst=20020888, speed=49.16 MPix/s
This is a cleanup for old and now duplicated code. The performance improvement
is mostly coming from the enabled use of software prefetch, but instructions
scheduling is also slightly better.
Benchmark on ARM Cortex-A8 r2p2 @1GHz, 32-bit LPDDR @200MHz:
Microbenchmark (scaling 2000x2000 image with scale factor close to 1x):
before: op=1, src=20028888, dst=20028888, speed=53.24 MPix/s
after: op=1, src=20028888, dst=20028888, speed=74.36 MPix/s
This allows to generate bilinear scanline scaling functions targeting
various source and destination color formats. Right now a8r8g8b8/x8r8g8b8
and r5g6b5 color formats are supported. More formats can be added if needed.
Initial NEON optimization for bilinear scaling. Can be probably
improved more.
Benchmark on ARM Cortex-A8:
Microbenchmark (scaling 2000x2000 image with scale factor close to 1x):
before: op=1, src=20028888, dst=20028888, speed=6.70 MPix/s
after: op=1, src=20028888, dst=20028888, speed=44.27 MPix/s
A primitive naive implementation of bilinear scaling using SSE2 intrinsics,
which only handles one pixel at a time. It is approximately 2x faster than
pixman general compositing path. Single pass processing without intermediate
temporary buffer contributes to ~15% and loop unrolling contributes to ~20%
of this speedup.
Benchmark on Intel Core i7 (x86-64):
Using cairo-perf-trace:
before: image firefox-planet-gnome 12.566 12.610 0.23% 6/6
after: image firefox-planet-gnome 10.961 11.013 0.19% 5/6
Microbenchmark (scaling 2000x2000 image with scale factor close to 1x):
before: op=1, src=20028888, dst=20028888, speed=70.48 MPix/s
after: op=1, src=20028888, dst=20028888, speed=165.38 MPix/s
Individual correctness check for the new bilinear scaling related
supplementary function. This test program uses a bit wider range
of input arguments, not covered by other tests.
Can be used for implementing SIMD optimized fast path
functions which work with bilinear scaled source images.
Similar to the template for nearest scaling main loop, the
following types of mask are supported:
1. no mask
2. non-scaled a8 mask with SAMPLES_COVER_CLIP flag
3. solid mask
PAD repeat is fully supported. NONE repeat is partially
supported (right now only works if source image has alpha
channel or when alpha channel of the source image does not
have any effect on the compositing operation).
MSVC does not notice non-returning functions (abort() / assert(0))
and warns about paths which end with them in non-void functions:
c:\cygwin\home\ranma42\code\fdo\pixman\test\fetch-test.c(114) :
warning C4715: 'reader' : not all control paths return a value
c:\cygwin\home\ranma42\code\fdo\pixman\test\stress-test.c(133) :
warning C4715: 'real_reader' : not all control paths return a value
c:\cygwin\home\ranma42\code\fdo\pixman\test\composite.c(431) :
warning C4715: 'calc_op' : not all control paths return a value
These warnings can be silenced by adding a return after the
termination call.
The Microsoft C compiler cannot handle subobject initialization and
Win32 does not provide snprintf.
Work around these limitations by using normal struct initialization
and using sprintf (a manual check shows that the buffer size is
sufficient).
Previously 'make check' would compile and run tests first, and only
then proceed to compiling demos. Which is not very convenient
because of the need to scroll back console output to see the
tests verdict. Swapping order of SUBDIRS variable entries in
Makefile.am resolves this.
This allows some more code to be deleted from the X server. The
implementation consists of converting to trapezoids, and is shared
with pixman_composite_triangles().
The Render X extension can draw triangles as well as trapezoids, but
the implementation has always converted them to trapezoids. This patch
moves the X server's triangle conversion code into pixman, where we
can reuse the pixman_composite_trapezoid() code.
This function is an implementation of the X server request
Trapezoids. That request is what the X backend of cairo is using all
the time; by moving it into pixman we can hopefully make it faster.
This separates the test suite from the random gtk+ using test
programs. "demos" is somewhat misleading because the programs there
are not particularly exciting (with the possible exception of
composite-test which shows off all the compositing operators).
Scaling function now gets an extra boolean argument, which is set
to TRUE when we are fetching padding pixels for NONE repeat. This
allows to make a decision whether to interpret alpha as 0xFF or 0x00
for such pixels when working with formats which don't have alpha
channel (for example x8r8g8b8 and r5g6b5).
In addition to the most common case of not having any mask at all, two
variants of scaling with mask show up in cairo traces:
1. non-scaled a8 mask with SAMPLES_COVER_CLIP flag
2. solid mask
This patch extends the nearest scaling main loop template to also
support these cases.
Depending on CPU architecture, performance is in the range of 1.5 to 4 times
slower than simple nonrotated copy (which would be an ideal case, perfectly
utilizing memory bandwidth), but still is more than 7 times faster if
compared to general path.
This implementation sets a performance baseline for rotation. The use
of SIMD instructions may further improve memory bandwidth utilization.
Split this function into two, one that has a mask, and one that
doesn't. This is a fairly substantial speed-up in many cases.
New output of lowlevel-blt-bench over_x888_8_0565:
over_x888_8_0565 = L1: 63.76 L2: 62.75 M: 59.37 ( 21.55%) HT: 45.89 VT: 43.55 R: 34.51 RT: 16.80 ( 201Kops/s)
New output of lowlevel-blt-bench over_x888_8_0565:
over_x888_8_0565 = L1: 57.85 L2: 56.80 M: 54.14 ( 19.50%) HT: 42.64 VT: 40.56 R: 32.67 RT: 16.22 ( 195Kops/s)
Based in part on code by Steve Snyder from
https://bugs.freedesktop.org/show_bug.cgi?id=21173
New output of lowlevel-blt-bench over_x888_8_0565:
over_x888_8_0565 = L1: 55.68 L2: 55.11 M: 52.83 ( 19.04%) HT: 39.62 VT: 37.70 R: 30.88 RT: 14.62 ( 174Kops/s)
The fetcher is looked up in a table, so that other fetchers can easily
be added.
See also https://bugs.freedesktop.org/show_bug.cgi?id=20709
The next few commits will speed this up quite a bit.
Current output:
---
reference memcpy speed = 2217.5MB/s (554.4MP/s for 32bpp fills)
---
over_x888_8_0565 = L1: 54.67 L2: 54.01 M: 52.33 ( 18.88%) HT: 37.19 VT: 35.54 R: 29.40 RT: 13.63 ( 162Kops/s)
Instead of having each individual implementation decide which fallback
to use, move it into pixman-cpu.c, where a more global decision can be
made.
This is accomplished by adding a "fallback" argument to all the
pixman_implementation_create_*() implementations, and then in
_pixman_choose_implementation() pass in the desired fallback.
It seems to be relatively common for people to use development
snapshots of pixman thinking they are ordinary releases. This patch
makes it such that if the current minor version is odd, configure will
print a banner explaining the version number scheme plus information
about where to report bugs.
Removes useless variable declarations. This can only result in more
efficient code, as these variables where sometimes assigned, but
their values were never used.
Green Hills Software MULTI compiler was producing a number
of warnings due to incorrect uses of int instead of the correct
corresponding pixman_*_t type.
The mask_bits variable is only declared in a limited scope, so the
pointer to it becomes invalid instantly. Somehow this didn't actually
trigger any bugs, but Brent Fulgham reported that Bounds Checker was
complaining about it.
Fix the bug by moving mask_bits to the function scope.
radial-test is a port of the radial-gradient test from the cairo test
suite. It has been modified so that some pixels have 0 in both the a
and b coefficients of the quadratic equation solved by the rasterizer,
to expose a division by zero in the original implementation.
When fetching from destinations, we need to ignore transformations,
repeat and filtering. Currently we don't ignore them, which means all
kinds of bad things can happen.
This bug fixes this problem by directly calling the scanline fetchers
for destinations instead of going through the full
get_scanline_32/64().
Add two new iterator flags, ITER_IGNORE_ALPHA and ITER_IGNORE_RGB that
are set when the alpha and rgb values are not needed. If both are set,
then we can skip fetching entirely and just use
_pixman_iter_get_scanline_noop.
Introduce a new ITER_LOCALIZED_ALPHA flag that indicates that the
alpha value computed is used only for the alpha channel of the output;
it doesn't affect the RGB channels.
Then in pixman-bits-image.c, if a destination is either a8r8g8b8 or
x8r8g8b8 with localized alpha, the iterator will return a pointer
directly into the image.
The separate get_scanline_32() functions in solid, linear, radial and
conical images are no longer necessary because all access to these
images now go through iterators.
At this point these functions are basically a cache that the bits
image uses for its fetchers, so they can be moved to the bits image.
With the scanline getters only being initialized in the bits image,
the _pixman_image_get_scanline_generic_64 can be moved to
pixman-bits-image.c. That gets rid of the final user of
_pixman_image_get_scanline_32/64, so these can be deleted.
Make src_iter_init() and dest_iter_init() virtual methods in the
implementation struct. This allows individual implementations to plug
in their own CPU specific scanline fetchers.
Instead of calling _pixman_image_get_scanline_32/64(), move the
iterator initialization into the respecive image implementations and
call the scanline generators directly.
We add a new structure called a pixman_iter_t that encapsulates the
information required to read scanlines from an image. It contains two
functions, get_scanline() and write_back(). The get_scanline()
function will generate pixels for the current scanline. For iterators
for source images, it will also advance to the next scanline. The
write_back() function is only called for destination images. Its
function is to write back the modified pixels to the image and then
advance to the next scanline.
When an iterator is initialized, it is passed this information:
- The image to iterate
- The rectangle to be iterated
- A buffer that the iterator may (but is not required to) use. This
buffer is guaranteed to have space for at least width pixels.
- A flag indicating whether a8r8g8b8 or a16r16g16b16 pixels should
be fetched
There are a number of (eventual) benefits to the iterators:
- The initialization of the iterator can be virtualized such that
implementations can plug in their own CPU specific get_scanline()
and write_back() functions.
- If an image is horizontal, it can simply plug in an appropriate
get_scanline(). This way we can get rid of the annoying
classify() virtual function.
- In general, iterators can remember what they did on the last
scanline, so for example a REPEAT_NONE image might reuse the same
data for all the empty scanlines generated by the zero-extension.
- More detailed information can be passed to iterator, allowing
more specialized fetchers to be used.
- We can fix the bug where destination filters and transformations
are not currently being ignored as they should be.
However, this initial implementation is not optimized at all. We lose
several existing optimizations:
- The ability to composite directly in the destination
- The ability to only fetch one scanline for horizontal images
- The ability to avoid fetching the src and mask for the CLEAR
operator
Later patches will re-introduce these optimizations.
This option can be used for building fully static binaries of the test
programs so that they can be easily run using qemu-user. With binfmt-misc
configured, 'make check' works fine for crosscompiled pixman builds.
Taking address of a variable and then using it as an array looks suspicious
to static code analyzers. So change it into an array with 1 element to make
them happy. Both old and new variants of this code are correct because 'vx'
and 'unit_x' arguments are set to 0 and it means that the called scanline
function can only access a single element of 'zero' buffer.
When 'pixman_transform_multiply' fails, the result of multiplication just
could not have been identity matrix (one of the values in the resulting
matrix can't be represented as 16.16 fixed point value). So it is safe
to return FALSE.
When b is 0, avoid the division by zero and just return transparent
black.
When the solution t would have an invalid radius (negative or outside
[0,1] for none-extended gradients), return transparent black.
All objects using test/util.c fail to link:
| CCLD region-test
| /usr/bin/ld: utils.o: in function enable_fp_exceptions:utils.c(.text+0x939): error: undefined reference to 'feenableexcept'
There's indeed no explicit dependency on -lm, and if HAVE_FEENABLEEXCEPT
happens to be set, test/util.c uses feenableexcept(), which is nowhere
to be found while linking.
Fix this by adding -lm to TEST_LDADD, although two alternatives could be
thought of:
- Only specifying -lm for objects using util.c.
- Introducing a conditional to add -lm only when configure detects
have_feenableexcept=yes.
Signed-off-by: Cyril Brulebois <kibi@debian.org>
Remove a stray #include <fenv.h> added in commit 2444b2265a
to fix compilation on platforms which don't have fenv.h
Signed-off-by: Jon TURNEY <jon.turney@dronecode.org.uk>
This test program tries to use as many rarely-used features as
possible, including alpha maps, accessor functions, oddly-sized
images, strange transformations, conical gradients, etc.
The hope is to provoke crashes or irregular behavior in pixman.
The temporary scanline buffer allocated on stack was declared
as uint8_t array. As a result, the compiler was free to select
any arbitrary alignment for it (even though there is typically
no reason to use really weird alignments here and the stack is
normally at least 4 bytes aligned on most platforms). Having
improper alignment is non-portable and can impact performance
or even make the code misbehave depending on the target platform.
Using uint64_t type for this array should ensure that any possible
memory accesses done by pixman code are going to be handled correctly
(pixman-combine64.c can access this buffer via uint64_t * pointer).
Some alignment related problem was reported in:
http://lists.freedesktop.org/archives/pixman/2010-November/000747.html
With this optimization added, pixman assisted conversion from
non-premultiplied to premultiplied alpha format is now fully
NEON optimized (both with and without R/B color components
swapping in the process).
Not all types of operations can be skipped when having transparent
solid source or transparent solid mask. Add an extra flags parameter
for providing this information to the wrappers.
Renamed suppementary macros from 'over_n_8_0565' to 'over_8888_8_0565',
because they can actually support all variants of this operation:
over_8888_8_0565/over_n_8_0565/over_8888_n_0565.
Also 'over_8888_8_0565' now uses more optimized common code instead of its
own variant, improving performance a bit. Even though this operation is
still memory bandwidth limited, scaled variants of these fast paths may
put more stress on CPU later.
Benchmarked on ARM Cortex-A8 @500MHz:
== before ==
over_8888_8_0565 = L1: 67.10 L2: 53.82 M: 44.70 (105.17%)
HT: 18.73 VT: 16.91 R: 14.25 RT: 4.80 (52Kops/s)
== after ==
over_8888_8_0565 = L1: 77.83 L2: 58.14 M: 44.82 (105.52%)
HT: 20.58 VT: 17.44 R: 15.05 RT: 4.88 (52Kops/s)
Code rearranged to get better instructions scheduling for ARM Cortex-A8/A9.
Now it is ~30% faster for the pixel data in L1 cache and makes better use
of memory bandwidth when running at lower clock frequencies (ex. 500MHz).
Also register d24 (pixels from the mask image) is now not clobbered by
supplementary macros, which allows to reuse them for the other variants
of compositing operations later.
Benchmark from ARM Cortex-A8 @500MHz:
== before ==
over_n_8_0565 = L1: 63.90 L2: 63.15 M: 60.97 ( 73.53%)
HT: 28.89 VT: 24.14 R: 21.33 RT: 6.78 ( 67Kops/s)
== after ==
over_n_8_0565 = L1: 82.64 L2: 75.19 M: 71.52 ( 84.14%)
HT: 30.49 VT: 25.56 R: 22.36 RT: 6.89 ( 68Kops/s)
This macro hides the implementation details of pixels fetching
for the mask image just like 'fetch_src_pixblock' does for the
source image. This provides more possibilities for reusing the
same code blocks in different compositing functions.
This patch does not introduce any functional changes and the
resulting code in the compiled object file is exactly the same.
There are versions for all combinations of x8r8g8b8/a8r8g8b8 and
pad/repeat/none/normal repeat modes. The bulk of each function is an
inline function that takes a format and a repeat mode as parameters.
Radial gradients are "conical", thus they can have some non-opaque
parts even if all of their stops are completely opaque.
To guarantee that a radial gradient is actually opaque, it needs to
also have one of the two circles containing the other one. In this
case when extrapolating, the whole plane is completely covered (as
explained in the comment in pixman-radial-gradient.c).
The performance improvement is only in the ballpark of 5% when
compared against C code built with a reasonably good compiler
(gcc 4.5.1). But gcc 4.4 produces approximately 30% slower code
here, so assembly optimization makes sense to avoid dependency
on the compiler quality and/or optimization options.
Benchmark from ARM11:
== before ==
op=1, src_fmt=10020565, dst_fmt=10020565, speed=34.86 MPix/s
== after ==
op=1, src_fmt=10020565, dst_fmt=10020565, speed=36.62 MPix/s
Benchmark from ARM Cortex-A8:
== before ==
op=1, src_fmt=10020565, dst_fmt=10020565, speed=89.55 MPix/s
== after ==
op=1, src_fmt=10020565, dst_fmt=10020565, speed=94.91 MPix/s
This template can be used to instantiate scaled fast path functions
by providing main loop code and calling NEON assembly optimized
scanline processing functions from it. Another macro can be used
to simplify adding entries to fast path tables.
Now it is possible to generate scanline processing functions
for the case when the source image is scaled with NEAREST filter.
Only 16bpp and 32bpp pixel formats are supported for now. But the
others can be also added later when needed. All the existing NEON
fast path functions should be quite easy to reuse for implementing
fast paths which can work with scaled source images.
Added a special macro 'pixld_src' which is now responsible for fetching
pixels from the source image. Right now it just passes all its arguments
directly to 'pixld' macro, but it can be used in the future to provide
a special pixel fetcher for implementing nearest scaling.
The 'pixld_src' has a lot of arguments which define its behavior. But
for each particular fast path implementation, we already know NEON
registers allocation and how many pixels are processed in a single block.
That's why a higher level macro 'fetch_src_pixblock' is also introduced
(it's easier to use because it has no arguments) and used everywhere
in 'pixman-arm-neon-asm.S' instead of VLD instructions.
This patch does not introduce any functional changes and the resulting code
in the compiled object file is exactly the same.
This was mostly harmless and had no effect on little endian systems.
But wrong vector element size is at least inconsistent and also
can theoretically cause problems on big endian ARM systems.
There is attribute 'constructor' supported since gcc 2.7 which allows
to have a constructor function for library initialization. This eliminates
an extra branch for each composite operation and also helps to avoid
complains from race condition detection tools like helgrind.
The other compilers may or may not support this attribute properly.
Ideally, the compilers should fail to compile the code with unknown
attribute, so the configure check should do the right job. But in
reality the problems are surely possible. Fortunately such problems
should be quite easy to find because NULL pointer dereference should
happen almost immediately if the constructor fails to run.
clang 2.7:
supports __attribute__((constructor)) properly and pretends to be gcc
tcc 0.9.25:
ignores __attribute__((constructor)), but does not pretend to be gcc
GCC assumes that input variables in inline assembly are fully consumed
before any output variable is written. This means it may allocate the
variables in the same register unless the output variables are marked
as early-clobber.
From Jeremy Huddleston:
I noticed a problem building pixman with clang and reported it to
the clang developers. They responded back with a comment about
the inline asm in pixman-mmx.c and suggested a fix:
"""
Incidentally, Jeremy, in the asm that reads
__asm__ (
"movq %7, %0\n"
"movq %7, %1\n"
"movq %7, %2\n"
"movq %7, %3\n"
"movq %7, %4\n"
"movq %7, %5\n"
"movq %7, %6\n"
: "=y" (v1), "=y" (v2), "=y" (v3),
"=y" (v4), "=y" (v5), "=y" (v6), "=y" (v7)
: "y" (vfill));
all the output operands except the last one should be marked as
earlyclobber ("=&y"). This is working by accident with gcc.
"""
Cc: jeremyhu@apple.com
Reviewed-by: Matt Turner <mattst88@gmail.com>
There used to be a bug in the X server where it would rely on
out-of-bounds accesses when it was asked to composite with a
window as the source. It would create a pixman image pointing
to some bogus position in memory, but then set a clip region
to the position where the actual bits were.
Due to a bug in old versions of pixman, where it would not clip
against the image bounds when a clip region was set, this would
actually work. So when the pixman bug was fixed, a workaround was
added to allow certain out-of-bound accesses.
However, the 1.6 X server is so old now that we can remove this
workaround. This does mean that if you update pixman to 0.22 or later,
you will need to use a 1.7 X server or later.
As of pixman-0.19.2-5-g5b99710, Gtk+ is auto-detected, make sure not to
pick it accidentally, by passing --disable-gtk. (That's only for test
purposes, but would require pixman-1 itself.)
Even after commit e46be417ce alphamap
test is still leaking the alphamap pixmap, leading to mmap() failures
on cygwin
Signed-off-by: Jon TURNEY <jon.turney@dronecode.org.uk>
huge-radial in the cairo test suite pointed out an undocumented
overflow in the radial gradient code.
By casting to pixman_fixed_48_16_t before doing the operations,
the overflow can be avoided.
The linear gradient was the only image type that relied on the class
being stored in the image struct itself. With the previous changes, it
doesn't need that anymore, so we can delete the field.
Use the same computations to classify the gradient and to
rasterize it.
This improves the correctness of the classification by
avoiding integer division.
Integer division (without keeping the remainder) can discard a lot
of information. Doing the division maths in floating point (and
paying attention to error propagation) allows to greatly improve
the precision of linear gradients.
Change radial gradient computations and definition to reflect the
radial gradients in PDF specifications (see section 8.7.4.5.4,
Type 3 (Radial) Shadings of the PDF Reference Manual).
Instead of having a valid interpolation parameter value for every
point of the plane, define it only for points withing the area
covered by the family of circles generated by interpolating or
extrapolating the start and end circles.
Points outside this area are now transparent black (rgba 0 0 0 0).
Points within this area have the color assiciated with the maximum
value of the interpolation parameter in that point (if multiple
solutions exist within the range specified by the extend mode).
The images are being created with non-NULL data, so we have to free it
outselves. This is important because the Cygwin tinderbox is running
out of memory and produces this:
mmap failed on 20000 1507328
mmap failed on 40000 1507328
mmap failed on 20000 1507328
mmap failed on 40000 1507328
mmap failed on 40000 1507328
mmap failed on 40000 1507328
http://tinderbox.x.org/builds/2010-10-05-0014/logs/pixman/#check
We already exit early for DST, but for the HSL operators with
component alpha, we crash at the moment. Fix that by adding a dummy
combine_dst() function.
Each test uses the test number as the random number seed; if it
didn't, all the threads would run the same tests since they would all
start from the same seed.
Previously this test would try to exhaustively test all combinations
of formats and operators, which meant that it would take hours to run.
Instead, generate images randomly and test compositing those.
Cc: chris@chris-wilson.co.uk
Previously, this function would evaluate the error under the
assumption that the format was 565 or wider. This patch changes it to
take the actual format into account.
With that fixed, we can turn on testing for the rest of the formats.
Cc: chris@chris-wilson.co.uk
This function was using the number of bits in a channel as if it were
a mask, which lead to many spurious errors. With that fixed, we can
turn on testing for all formats where all channels have 5 or more
bits.
Cc: chris@chris-wilson.co.uk
The first broken optimization is that it checks "a != 0x00" where it
should check "s != 0x00". The other is that it skips the computation
when alpha is 0xff. That is wrong because in the formula:
min (1, (1 - Aa)/Ab)
the render specification states that if Ab is 0, the quotient is
defined to positive infinity. That is the case even if (1 - Aa) is 0.
After fast path cache introduction, the overhead of having this fallback is
insignificant. On the other hand, some of the ARM assembly optimizations (for
example nearest neighbor scaling) do not need NEON.
These minor changes should fix a large number of
macro declaration - related "syntax error: empty declaration" warnings
which are seen while compiling the code with the Solaris Studio
compiler.
This was supposedly an optimization, but it has pathological cases
where it definitely isn't. For example a 1 x n image will cause it to
have terrible memory access patterns and to generate a ton of modulus
operations.
Since no one has ever measured whether it actually is an improvement,
and since it is doing the repeating at the wrong the stage in the
pipeline, and since with the previous commit it can't be triggered
anymore because we now require SAMPLES_COVER_CLIP for regular fast
paths, just delete it.
The standard fast paths deal with two kinds of images: solids and
bits. These two image types require different flags, but
PIXMAN_STD_FAST_PATH uses the same ones for both.
This patch makes it so that solid images just get the standard flags,
while bits images must be untransformed contain the destination clip
within the sample grid.
This means that the old FAST_PATH_COVERS_CLIP flag is now not used
anymore, so it can be deleted.
This patch removes an unnecessary typecast of MAP_FAILED,
replaces an erroneous free() by the correct munmap() in the
error path for a failing mprotect(), and, finally, removes
redundant calls to mprotect() that aren't necessary, because
munmap() doesn't call for any specific memory protection.
Not all systems are regular Unices, so let's be careful with the
mmap()-related stuff, which might be unavailable. This patch makes
sure that mmap() and friends is used only when the <sys/mman.h>
header is found.
OK. here is the work to clear all cache prefetch. Please review it. 3x
On Tue, Sep 21, 2010 at 11:36:30PM +0800, Soeren Sandmann wrote:
> Liu Xinyun <xinyun.liu@intel.com> writes:
>
> > This patch is to add a new configuration option: enable-cache-prefetch,
> > which is default yes.
> >
> > Here is a link which talks on cache issue.
> > http://lists.freedesktop.org/archives/pixman/2010-June/000218.html
> >
> > When disable it on Atom CPU(configured with --enable-cache-prefetch=no),
> > it will have a little performance gain. Here is the patch.
>
> I think the cache prefetch code should just be deleted outright. No
> benchmarks that I'm aware of show it to be an improvement.
>
>
> Thanks,
> Soren
>From bca2192ef524bcae4eea84d0ffed9e8c4855675f Mon Sep 17 00:00:00 2001
From: Liu Xinyun <xinyun.liu@intel.com>
Date: Wed, 22 Sep 2010 00:11:56 +0800
Subject: [PATCH] remove cache prefetch
If the extents of the composite region are broken such that x2 <= x1
or y2 <= y1, then we need to zero the extents before returning so that
the region won't be completely broken when calling
pixman_region32_fini().
This test is a modified version of Siarhei's compositor throughput
benchmark. It's expanded with explicit reporting of memory bandwidth
consumption for the M-test, and with an additional 8x8-random test
intended to determine peak ops/sec capability. There are also quite a
lot more operations tested for.
Impending benchmark code will need a function to get current time
in seconds, and this patch introduces such routine. We try to use
the POSIX gettimeofday() function when available, and fall back to
clock() when not.
The aligned_malloc() routine will be used in more than one test utility.
At least, a low-level blitter benchmark needs it. Therefore, let's make
this function a part of common test utilities code.
There are versions for all combinations of x8r8g8b8/a8r8g8b8 and
pad/repeat/none/normal repeat modes. The bulk of each scaler is an
inline function that takes a format and a repeat mode as parameters.
The new scalers are all commented out, but the next commits will
enable them one at a time to facilitate bisecting.
This test tests compositing with various affine transformations. It is
almost identical to scaling-test, except that it also applies a random
rotation in addition to the random scaling and translation.
Profiling various cairo traces showed that we were spending a lot of
time in analyze_extents and compute_sample_extents(). This was
especially bad for glyphs where all this computation was completely
unnecessary.
This patch adds a fast path for the case of non-transformed BITS
images. The result is approximately a 6% improvement on the
firefox-talos-gfx benchmark:
Before:
[ # ] backend test min(s) median(s) stddev. count
[ 0] image firefox-talos-gfx 13.797 13.848 0.20% 6/6
After:
[ # ] backend test min(s) median(s) stddev. count
[ 0] image firefox-talos-gfx 12.946 13.018 0.39% 6/6
When an image is solid or repeating, the FAST_PATH_COVERS_CLIP flag
can be set in compute_image_info().
Also the code that turned this flag off in pixman.c was not correct;
it didn't take transformations into account. With this patch, pixman.c
doesn't set the flag by default, but instead relies on the call to
compute_samples_extents() to set it when possible.
By the way, it seems that with gcc 4.5.0 from mingw.org, __thread, sse
and mmx work fine.
I added the below to pixman 0.18 and as far as I can see, it works.
make check reports no problems. (Earlier I had to use --disable-mmx
and --disable-sse2.) Also gtk-demo and gimp run fine.
(Also a change to get rid of the warnings about -fvisibility being ignored.)
If an image has an alpha map that has wide components, then we need to
use 64 bit processing for that image. We detect this situation in
pixman-image.c and remove the FAST_PATH_NARROW_FORMAT flag.
In pixman-general, the wide/narrow decision is now based on the flags
instead of on the formats.
This avoids a negative in the name. Also, by renaming the "wide"
variable in pixman-general.c to "narrow" and fixing up the logic
correspondingly, the code there reads a lot more straightforwardly.
- Test many more combinations of formats
- Test destination alpha maps
- Test various different alpha origins
Also add a transformation to the destination, but comment it out
because it is actually broken at the moment (and pretty difficult to
fix).
These variants of malloc() and free() try to surround the allocated
memory with protected pages so that out-of-bounds accessess will cause
a segmentation fault.
If mprotect() and getpagesize() are not available, these functions are
simply equivalent to malloc() and free().
This is the first demo implementation, it should be possible to
generalize it later to cover more operations with less lines of code.
It should be also possible to introduce the use of '__builtin_constant_p'
gcc builtin function for an efficient way of checking if 'unit_x' is known
to be zero at compile time (when processing padding pixels for NONE, or
PAD repeat).
Benchmarks from Intel Core i7 860:
== before (nearest OVER) ==
op=3, src_fmt=20028888, dst_fmt=20028888, speed=142.01 MPix/s
== after (nearest OVER) ==
op=3, src_fmt=20028888, dst_fmt=20028888, speed=314.99 MPix/s
== performance of nonscaled operation as a reference ==
op=3, src_fmt=20028888, dst_fmt=20028888, speed=652.09 MPix/s
Implemented very similar to PAD repeat.
And gcc also seems to be able to completely eliminate the
code responsible for left and right padding pixels for OVER
operation with NONE repeat.
When processing pixels from the left and right padding, the same
scanline function is used with 'unit_x' set to 0.
Actually appears that gcc can handle this quite efficiently. When
using 'restrict' keyword, it is able to optimize the whole operation
performed on left or right padding pixels to a small unrolled loop
(the code is reduced to a simple fill implementation):
9b30: 89 08 mov %ecx,(%rax)
9b32: 89 48 04 mov %ecx,0x4(%rax)
9b35: 48 83 c0 08 add $0x8,%rax
9b39: 49 39 c0 cmp %rax,%r8
9b3c: 75 f2 jne 9b30
Without 'restrict' keyword, there is one instruction more: reloading
source pixel data from memory in the beginning of each iteration. That
is slower, but also acceptable.
We need to implement a true PIXMAN_REPEAT_NONE support later (padding
the source with zero pixels). So it's better not to use PIXMAN_REPEAT_NONE
for handling FAST_PATH_SAMPLES_COVER_CLIP special case.
Scanline processing is now split into a separate function. This provides
an easy way of overriding it with a platform specific implementation,
which may use SIMD optimizations. Only basic C data types are used as
the arguments for this function, so it may be implemented entirely in
assembly or be generated by some JIT engine.
Also as a result of this split, the complexity of code is reduced a
bit and now it should be easier to introduce support for the currently
missing NONE, PAD and REFLECT repeat types.
These macros with some modifications can can be reused later by
various platform specific implementations, introducing SIMD
optimizations for nearest scaling fast paths.
Added a pair of macros which can help to detect corruption
of floating point registers after a function call. This may
happen if _mm_empty() call is forgotten in MMX/SSE2 fast
path code, or ARM NEON assembly optimized function
forgets to save/restore d8-d15 registers before use.
The rule is that the region passed in must be initialized and that the
region returned will still be valid. Ie., the lifecycle is the
responsibility of the caller, regardless of what the function returns.
Previously, compute_composite_region32() would finalize the region and
then return FALSE, and then the caller would finalize the region
again, leading to memory corruption in some cases.
This patch adresses the issue discussed in
http://lists.freedesktop.org/archives/pixman/2010-April/000163.html
There were only two clashing identifiers. The first one is IN, which
obviously causes problems in Pixman for lines like
PIXMAN_STD_FAST_PATH (IN, solid, a8, a8, fast_composite_in_n_8_8),
Fortunately the mingw headers provide a solution: by defining
_NO_W32_PSEUDO_MODIFIERS, these stupid symbols are skipped.
The other name is UINT64, used in pixman-mmx.c. I renamed that
function to to_uint64, but may be another name is more appropriate.
From time to time people run into issues where the configure script
detects GTK+ when it is either not installed, or not functional due to
a missing pixman. Most recently:
https://bugs.freedesktop.org/show_bug.cgi?id=29736
This patch makes the configure script more paranoid by
- always using PKG_CHECK_MODULES and not PKG_CHECK_EXISTS, since it
seems PKG_CHECK_EXISTS will sometimes return true even if a dependency
of GTK+, such as pixman-1, is missing.
- explicitly checking that pixman-1 is installed before enabling GTK+.
Cc: my.somewhat.lengthy.loginname@gmail.com
There is not much point having a separate function that just validates
the images. Also add a boolean return to lookup_composite_function()
so that we can return if no composite function is found.
Fixes the region-translate test case by clipping region translations to
the newly defined PIXMAN_REGION_MIN/MAX and using the newly introduced
type overflow_int_t to check for the overflow.
Also uses INT16_MAX or INT32_MAX for these values instead of relying on
the size of short and int types.
It doesn't make sense in other cases, and the computation would make
use of image->bits.{width,height} which lead to uninitialized memory
accesses when the image wasn't of type BITS.
This flag is set whenever the pixels of a bits image don't have an
alpha channel. Together with FAST_PATH_SAMPLES_COVER_CLIP it implies
that the image effectively is opaque, so we can do operator reductions
such as OVER->SRC.
If someone tries to set an alpha map that itself has an alpha map,
simply return. Also, if someone tries to add an alpha map to an image
that is being _used_ as an alpha map, simply return.
This ensures that an alpha map can never have an alpha map.
This tests what happens if you attempt to make an image with an alpha
map that has the image as its alpha map. This results in an infinite
loop in _pixman_image_validate(), so the test sets up a SIGALRM to
exit if it runs for more than five seconds.
Similarly to how the fast paths are done, put the various bits_image
fetchers in a table, so that we can quickly find the best one based on
the image's flags and format.
The flags are:
* AFFINE_TRANSFORM, for affine transforms
* Y_UNIT_ZERO, for when the 10 entry in the transformation is zero
* FILTER_BILINEAR, for when the image has a bilinear filter
* NO_NORMAL_REPEAT, for when the repeat mode is not NORMAL
* HAS_TRANSFORM, for when the transform is not NULL
Also add some new FAST_PATH_REPEAT_* macros. These are just shorthands
for the image not having any of the other repeat modes. For example
REPEAT_NORMAL is (NO_NONE | NO_PAD | NO_REFLECT).
These functions can simply be passed as arguments to the various pixel
fetchers. We don't need to store them. Since they are known at compile
time and the pixel fetchers are force_inline, this is not a
performance issue.
Also temporarily make all pixel access go through the alpha path.
This commit fixes two separate problems: 1. Incorrect computation of
the FAST_PATH_SAMPLES_COVER_CLIP flag, and 2. FAST_PATH_16BIT_SAFE is
a nonsensical thing to compute.
== 1. Incorrect computation of SAMPLES_COVER_CLIP:
Previously we were using pixman_transform_bounds() to compute which
source samples would be used for a composite operation. This is
incorrect for several reasons:
(a) pixman_transform_bounds() is transforming the integer bounding box
of the destination samples, where it should be transforming the
bounding box of the samples themselves. In other words, it is too
pessimistic in some cases.
(b) pixman_transform_bounds() is not rounding the same way as we do
during sampling. For example, for a NEAREST filter we subtract
pixman_fixed_e before rounding off to the nearest sample so that a
transformed value of 1 will round to the sample at 0.5 and not to the
one at 1.5. However, pixman_transform_bounds() would simply truncate
to 1 which would imply that the first sample to be used was the one at
1.5. In other words, it is too optimistic in some cases.
(c) The result of pixman_transform_bounds() does not account for the
interpolation filter applied to the source.
== 2. FAST_PATH_16BIT_SAFE is nonsensical
The FAST_PATH_16BIT_SAFE is a flag that indicates that various
computations can be safely done within a 16.16 fixed-point
variable. It was used by certain fast paths who relied on those
computations succeeding. The problem is that many other compositing
functions were making similar assumptions but not actually requiring
the flag to be set. Notably, all the general compositing functions
simply walk the source region using 16.16 variables. If the
transformation happens to overflow, strange things will happen.
So instead of computing this flag in certain cases, it is better to
simply detect that overflows will happen and not try to composite at
all in that case. This has the advantage that most compositing
functions can be written naturally way.
It does have the disadvantage that we are giving up on some cases that
previously worked, but those are all corner cases where the areas
involved were very close to the limits of the coordinate
system. Relying on these working reliably was always a somewhat
dubious proposition. The most important case that might have worked
previously was untransformed compositing involving images larger than
32 bits. But even in those cases, if you had REPEAT_PAD or
REPEAT_REFLECT turned on, you would hit bits_image_fetch_transformed()
which has the 16 bit limitations.
== Fixes
This patch fixes both problems by introducing a new function called
analyze_extents() that has the responsibility to reject corner cases,
and to compute flags based on the extents.
It does this through a new compute_sample_extents() function that will
compute a conservative (but tight) approximation to the bounding box
of the samples that will actually be needed. By basing the computation
on the positions of the _sample_ locations in the destination, and by
taking the interpolation filter into account, it fixes problem one.
The same function is also used with a one-pixel expanded version of
the destination extents. By checking if the transformed bounding box
will overflow 16.16 fixed point, it fixes problem two.
This extends scaling-crash-test to test some more things:
- All combinations of NEAREST/BILINEAR/CONVOLUTION filters and
NORMAL/PAD/REFLECT repeat modes.
- Tests various scale factors very close to 1/7th such that the source
area is very close to edge of the source image.
- The same things, only with scale factors very close to 1/32767th.
- Enables the commented-out tests for accessing memory outside the
source buffer.
Also there is now a border around the source buffer which has a
different color than the source buffer itself so that if we sample
outside, it will show up.
Finally, the test now allows the destination buffer to not be changed
at all. This allows pixman to simply bail out in cases where the
transformation too strange.
This format is used on PXA framebuffer with some boards. It uses only 18 bits
from the 32 bit framebuffer to interpret color.
Signed-off-by: Marek Vasut <marek.vasut@gmail.com>
Negative scale factors are now also tested. A small additional
translate transform helps to stress the use of fractional
coordinates better.
Also the number of iterations to run by default increased in order
to compensate increased variety of operations to be tested.
This test tries to exploit some corner cases and previously known
bugs in nearest neighbor scaling fast path code, attempting to
crash pixman or cause some other nasty effect.
Instead of relying on preprocessor version checks to see if a
some compiler flags are supported, actually try to compile and
link a test program with the flags.
This patch adds extra guards around our use of
OpenMP pragmas and checks that the pragmas won't
cause link errors. This fixes the build on
Tru64 and Solaris with the native compilers and clang.
The x888 suggests that they have something to do with the x8r8g8b8
formats, but that's not the case; they are assuming a8r8g8b8
formats. (Although in some cases they also work for x8r8g8b8 type
formats).
The palettes for indexed formats must satisfy the condition that if
some index maps to a color C, then the 15 bit version of that color
must map back to the index. This ensures that the destination operator
is always a no-op, which seems like a reasonable assumption to make.
Protect the arguments to the combiner macros with parentheses, and
postfix their temporary variables with underscores to avoid name space
collisions with the surrounding code.
Alexander Shulgin pointed out that underscore-prefixed identifiers are
reserved for the C implementation, so we use postfix underscores
instead.
Under the assumption that pixman gradients are supposed to match
QConicalgradient, described here:
http://doc.trolltech.com/4.4/qconicalgradient.html
this patch fixes two separate bugs in pixman-conical-gradient.c.
The first bug is that the output of atan2() is in the range of [-pi,
pi], which means the parameter into the gradient can be negative. This
is wrong since a QConicalGradient always interpolates around the
center from 0 to 1. The fix for that is to (a) make sure the given
angle is between 0 and 360, and (b) add or subtract 2 * M_PI if the
computed angle ends up outside [0, 2 * pi].
The other bug is that we were interpolating clockwise, whereas
QConicalGradient calls for a counter-clockwise interpolation. This is
easily fixed by subtracting the parameter from 1.
Finally, this patch encapsulates the computation in a new force-inline
function so that it can be reused in both the affine and non-affine
case.
Back in the day, the mask_bits argument was used to distinguish
between masks used for component alpha (where it was 0xffffffff) and
masks for unified alpha (where it was 0xff000000). In this way, the
fetchers could check if just the alpha channel was 0 and in that case
avoid fetching the source.
However, we haven't actually used it like that for a long time; it is
currently always either 0xffffffff or 0 (if the mask is NULL). It also
doesn't seem worthwhile resurrecting it because for premultiplied
buffers, if alpha is 0, then so are the color channels
normally.
This patch eliminates the mask_bits and changes the fetchers to just
assume it is 0xffffffff if mask is non-NULL.
This patch comes from the mozilla central tree. See
http://hg.mozilla.org/mozilla-central/rev/89338a224278 for the
original changeset.
Signed-off-by: Jeff Muizelaar <jmuizelaar@mozilla.com>
Signed-off-by: Egor Starkov <egor.starkov@nokia.com>
Signed-off-by: Rami Ylimaki <ext-rami.ylimaki@nokia.com>
Signed-off-by: Siarhei Siamashka <siarhei.siamashka@nokia.com>
Some of the tests are quite heavy CPU users and may benefit from
using multiple CPU cores, so the programs from 'test' directory
are now built with OpenMP support. OpenMP is easy to use, portable
and also takes care of making a decision about how many threads
to spawn.
This new script can be used to run continuously to compare two test
programs based on fuzzer_test_main() function from 'util.c' and
narrow down to a single problematic test from the batch which results
in different behavior.
This new generalized function can be reused in both blitters-test
and scaling-test. Final checksum calculation changed in order to make
it parallelizable (it is a sum of individual 32-bit values returned
by a callback function, which is now responsible for running test-specific
code). Return values may be crc32, some other hash or even just zero on
success and non-zero on error (in this case, the expected result of the
whole test run should be 0).
This line:
mask = mask | mask >> 8 | mask >> 16 | mask >> 24;
only works when mask has 0s in the lower 24 bits, so add
mask &= 0xff000000;
before.
Reported by Todd Rinaldo on the #cairo IRC channel.
The tls_name_key variable is passed to tls_name_get(), and the first
time this happens it isn't initialized. tls_name_get() then passes it
on to tls_name_alloc() which passes it on to pthread_setspecific()
leading to undefined behavior.
None of this is actually necessary at all because there is only one
such variable per thread local variable, so it doesn't need to passed
as a parameter at all.
All of this was pointed out by Tor Lillqvist on the cairo mailing
list.
This line:
mask = mask | mask >> 8 | mask >> 16 | mask >> 24;
only works when mask has 0s in the lower 24 bits, so add
mask &= 0xff000000;
before.
Reported by Todd Rinaldo on the #cairo IRC channel.
The tls_name_key variable is passed to tls_name_get(), and the first
time this happens it isn't initialized. tls_name_get() then passes it
on to tls_name_alloc() which passes it on to pthread_setspecific()
leading to undefined behavior.
None of this is actually necessary at all because there is only one
such variable per thread local variable, so it doesn't need to passed
as a parameter at all.
All of this was pointed out by Tor Lillqvist on the cairo mailing
list.
The problem was reported as bug 25534 against pixman in
freedesktop.org bugzila. Link to a patch for binutils:
http://sourceware.org/ml/binutils/2008-03/msg00260.html
For pixman the impact is a build failure when using
binutils 2.18. Versions 2.19 and higer are fine. Still
some distros may be using older versions of binutils and
this is causing problems.
This patch workarounds the problem by replacing a problematic
"vmov a, b" instruction with equivalent "vorr a, b, b". Actually
they even map to the same instruction opcode in the generated
code, so the resulting binary is identical with and without patch.
This can be used to override the architecture recorded in the EABI object
attribute section. We set a minimum arch to 'armv4'. Binutils documentation
recommends to use this directive with the code performing runtime detection
of CPU features.
Additionally NEON/VFP EABI attributes are suppressed. And the instruction
set to use is explicitly set to '.arm'.
Configure test for NEON support is also updated to include a bunch of
these new directives (if any of these is unsupported by the assembler,
it is better to fail configure test than to fail library build).
All these changes are required to fix SIGILL problem on armv4t, reported in
http://lists.freedesktop.org/archives/pixman/2010-March/000123.html
Avoid a division-by-zero exception if the first number returned by
rand() is a multiple of 500, causing us to create a zero width pixmap,
and then attempt to use get_rand(0) when generating a random stride...
Fixes https://bugs.freedesktop.org/attachment.cgi?id=34162
This is a macroized version of SRC/OVER repeat normal/unneeded nearest
neighbour scaling instantiated for some common 8888 and 565 formats.
Based on work by Siarhei Siamashka
FAST_PATH_SAMPLES_COVER_CLIP:
This is set of the source sample grid, unrepeated but transformed
completely completely covers the clip destination. If this is set
you can use a simple scaled that doesn't have to care about the repeat
mode.
FAST_PATH_16BIT_SAFE:
This signifies two things:
1) The size of the src/mask fits in a 16.16 fixed point, so something like:
max_vx = src_image->bits.width << 16;
Is allowed and is guaranteed to not overflow max_vx
2) When stepping the source space we're guaranteed to never overflow
a 16.16 bit fix point variable, even if we step one extra step
in the destination space. This means that a loop doing:
x = vx >> 16;
vx += unit_x; d = src_row[x];
will never overflow vx causing x to be negative.
And additionally, if you track vx like above and apply NORMAL repeat
after the vx addition with something like:
while (vx >= max_vx) vx -= max_vx;
This will never overflow the vx even on the final increment that
takes vx one past the end of where we will read, which makes the
repeat loop safe.
In some cases we end up trying to use the STORE_4 macro with an 8 bit
values, which resulted in other pixels getting overwritten. Fix this
by always masking off the low 4 bits.
This fixes blitters-test on big-endian machines.
These macros hide the various types of thread local support. On Linux
and Unix, they expand to just __thread. On Microsoft Visual C++, they
expand to __declspec(thread).
On OS X and other systems that don't have __thread, they expand to a
complicated concoction that uses pthread_once() and
pthread_get/set_specific() to get thread local variables.
OS X does not support __thread, so we have to check for it before
using it. It does however support pthread_get/setspecific(), so if we
don't have __thread, check if those are available.
The previous code worked in GNU make, but caused a syntax error in Solaris
make ( https://bugs.freedesktop.org/show_bug.cgi?id=27062 ) - this seems to
work in both, and should hopefully not cause syntax errors in any versions
of make not supporting the macro-substitution-in-macro-name feature, just
cause the macro to expand to nothing.
Signed-off-by: Alan Coopersmith <alan.coopersmith@sun.com>
In SPICE, with Microsoft Visual C++, pixman.h is included after
another file that defines these types, which causes warnings and
errors.
This patch allows such code to just define PIXMAN_DONT_DEFINE_STDINT
to use its own version of those types.
The four cases for each operator:
none-are-opaque, src-is-opaque, dest-is-opaque, both-are-opaque
are packed into one uint32_t per operator. The relevant strength
reduced operator can then be found by packing the source-is-opaque and
dest-is-opaque into two bits and shifting that number of bytes.
Chris Wilson pointed out a bug in the original version of this commit:
dest_is_opaque and source_is_opaque were used as booleans, but their
actual values were the results of a logical AND with the
FAST_PATH_OPAQUE flag, so the shift value was wildly wrong.
The only reason it actually passed the test suite (on x86) was that
the compiler computed the shift amount in the cl register, and the low
byte of FAST_PATH_OPAQUE happens to be 0, so no shifting actually took
place, and the original operator was returned.
By extending the operator information table to cover all operators we
can replace the loop with a table look-up. At the same time, base the
operator optimization on the computed flags rather than the ones in
the image struct.
Finally, as an extra optimization, we no longer ignore the case where
there is a mask. Instead we consider the source opaque if both source
and mask are opaque, or if the source is opaque and the mask is
missing.
https://bugs.freedesktop.org/show_bug.cgi?id=27050
Pixman is not compiling with c++ compiler. During compilation it gives
the following error:
/usr/include/pixman-1/pixman.h:335: error: comma at end of enumerator list
Signed-off-by: Søren Sandmann Pedersen <ssp@redhat.com>
This patch adds a cache in front of the fast path tables to reduce the
overhead of pixman_composite(). It is fixed size with move-to-front to
make sure the most popular fast paths are at the beginning of the cache.
The cache is thread local to avoid locking.
Instead of calling this function in compute_image_info(), just do the
relevant checks when the extended format is computed.
Move computation of solidness to validate
When a trapezoid sample point is exactly on a polygon edge, the rule
is that it is considered inside the trapezoid if the edge is a top or
left edge, but outside for bottom and right edges.
This program tests that for a1 trapezoids.
Rather than the region code having its own little debug system, move
all of it into pixman-private where there is already return_if_fail()
macros etc. These macros are now enabled in development snapshots and
nowhere else. Previously they were never enabled unless you modified
the code.
At the same time, remove all the asserts from the region code since we
can never turn them on anyway, and replace them with
critical_if_fail() macros that will print spew to standard error when
DEBUG is defined.
Finally, also change the debugging spew in pixman-bits-image.c to use
return_val_if_fail() instead of its own fprintf().
Although we added MMX emulation for Microsoft Visual C++ compiler for x64,
USE_SSE2 still requires USE_MMX. So we remove dependency of USE_MMX
for Windows x64.
Signed-off-by: Makoto Kato <m_kato@ga2.so-net.ne.jp>
In the common case where there is no repeating, the loop in
walk_region_internal() reduces to just walking of the boxes involved
and calling the composite function.
_pixman_run_fast_path() and pixman_compute_composite_region() are both
moved to pixman-image, since at this point that's the only place they
are being called from.
In the common case no images need the workaround, so we check for that
first, and only if an image does need a workaround do we check which
one of the images actually need it.
They are no longer necessary because we will just walk the fast path
tables, and the general composite path is treated as another fast
path.
This unfortunately means that sse2_composite() can no longer be
responsible for realigning the stack to 16 bytes, so we have to move
that to pixman_image_composite().
We introduce a new PIXMAN_OP_any fake operator and a PIXMAN_any fake
format that match anything. Then general_composite_rect() can be used
as another fast path.
Because general_composite_rect() does not require the sources to cover
the clip region, we add a new flag FAST_PATH_COVERS_CLIP which is part
of the set of standard flags for fast paths.
Because this flag cannot be computed until after the clip region is
available, we have to call pixman_compute_composite_region32() before
checking for fast paths. This will resolve itself when we get to the
point where _pixman_run_fast_path() is only called once per composite
operation.
- Make it work for PIXMAN_OP_OVER
- Split repeat computation for x and y, and only the x part in the
inner loop.
- Move stride multiplication outside of inner loop
There is not much real benefit in having asserts turned on in
snapshots because it doesn't lead to any new bug reports, just to
people not installing development snapshots since they case X server
crashes. So just turn them off.
While we are at it, limit the number of messages to stderr to 5
instead of 50.
Old code assumed that all ARMv7 processors support NEON instructions
unless overrided by environment variable ARM_TRUST_HWCAP. This causes
X server to die with SIGILL if NEON support is disabled in the kernel
configuration. Additionally, ARMv7 processors lacking NEON unit are
going to become available eventually.
The problem was reported by user bearsh at irc.freenode.net #gentoo-embedded
This makes sets the stage for caching the information by image instead
of computing it on each composite invocation.
This patch also computes format codes for images such as PIXMAN_solid,
so that we can no longer end up in the situation that a fast path is
selected for a 1x1 solid image, when that fast path doesn't actually
understand repeating.
Previously it would be multiplied onto the image pixel, but the Render
specification is pretty clear that the alpha map should be used
*instead* of any alpha channel within the image.
This makes the assumption that the pixels in the image are already
premultiplied with the alpha channel from the alpha map. If we don't
make this assumption and the image has an alpha channel of its own, we
would have to first unpremultiply that pixel, and then premultiply the
alpha value onto the color channels, and then replace the alpha
channel.
This program demonstrates three bugs relating to alpha maps:
- When fetching from an alpha map into 32 bit intermediates, we use
the fetcher from the image, and not the one from the alpha map.
- For 64 bit intermediates we call fetch_pixel_generic_lossy_32()
which then calls fetch_pixel_raw_64, which is NULL because alpha
images are never validated.
- The alpha map should be used *in place* of any existing alpha
channel, but we are actually multiplying it onto the image.
There is a couple of bugs in bugzilla where bugs in the X server
triggered asserts in the pixman region code. It is probably better to
let the X server survive this. (In fact, I thought I had disabled them
for 0.16.0, but apparently not).
The patch below uses these rules:
- In _stable_ pixman releases, assertions and selfchecks are turned
off. Assertions, so that the X server doesn't die. Selfchecks,
for performance reasons.
- In _unstable_ pixman releases, both assertions and selfcheck are
turned on. These releases are what get added to development
distributions such as rawhide, so we want as much self-checking
as possible.
- In _random git checkouts_, assertions are enabled, so that bugs
are caught, but selfchecks are disabled so that you can use them
for performance work without having to fiddle with turning
selfchecks off.
Existing template already supports 2D images processing,
but pixman also needs some NEON optimized functions for
improving performance when compositing is decoupled
into "fetch -> process -> store" stages and done via
temporary scanline buffer. That's why a new simplified
template which deals only with the generation of single
scanline processing functions is handy.
This fix prevents build failure due to not accepting PLD instruction when
compiling for armv4 cpu with the relevant -mcpu/-march options set in CFLAGS.
NEON unit has fast access to L1/L2 caches and even simple
copy of memory buffers using NEON provides more than 1.5x
performance improvement on ARM Cortex-A8.
This function is needed to improve performance of xfce4 terminal when
using bitmap fonts and running with 16bpp desktop. Some other applications
may potentially benefit too.
After applying this patch, top functions from Xorg process in
oprofile log change from
samples % image name symbol name
13296 29.1528 libpixman-1.so.0.17.1 combine_over_u
6452 14.1466 libpixman-1.so.0.17.1 fetch_scanline_r5g6b5
5516 12.0944 libpixman-1.so.0.17.1 fetch_scanline_a1
2273 4.9838 libpixman-1.so.0.17.1 store_scanline_r5g6b5
1741 3.8173 libpixman-1.so.0.17.1 fast_composite_add_1000_1000
1718 3.7669 libc-2.9.so memcpy
to
samples % image name symbol name
5594 14.7033 libpixman-1.so.0.17.1 fast_composite_over_n_1_0565
4323 11.3626 libc-2.9.so memcpy
3695 9.7119 libpixman-1.so.0.17.1 fast_composite_add_1000_1000
when scrolling text in terminal (reading man page).
This is a similar change as the top/bottom one, but in this case the
rounding is simpler because it's just always rounding down.
Based on a patch by M Joonas Pihlaja.
The rules for trap rasterization is that coordinates are rounded
towards north-west.
The pixman_sample_ceil() function is used to compute the first
(top-most) sample row included in the trap, so when the input
coordinate is already exactly on a sample row, no rounding should take
place.
On the other hand, pixman_sample_floor() is used to compute the final
(bottom-most) sample row, so if the input is precisely on a sample
row, it needs to be rounded down to the previous row.
This commit fixes the rounding computation. The idea of the
computation is like this:
Floor operation that rounds exact matches down: First subtract
pixman_fixed_e to make sure input already on a sample row gets rounded
down. Then find out how many small steps are between the input and the
first fraction. Then add those small steps to the first fraction.
The ceil operation first adds (small_step + pixman_e), then runs a
floor. This ensures that exact matches are not rounded off.
Based on a patch by M Joonas Pihlaja.
The sampling grid is slightly skewed in the antialiased case. Consider
the case where we have n = 8 bits of alpha.
The small step is
small_step = fixed_1 / 15 = 65536 / 15 = 4369
The first fraction is then
frac_first = (small_step / 2) = (65536 - 15) / 2 = 2184
and the last fraction becomes
frac_last
= frac_first + (15 - 1) * small_step = 2184 + 14 * 4369 = 63350
which means the size of the last bit of the pixel is
65536 - 63350 = 2186
which is 2 bigger than the first fraction. This is not the end of the
world, but it would be more correct to have 2185 and 2185, and we can
accomplish that simply by making the first fraction half the *big*
step instead of half the small step.
If we ever move to coordinates with 8 fractional bits, the
corresponding values become 8 and 10 out of 256, where 9 and 9 would
be better.
Similarly in the X direction.
Instead introduce two new fake formats
PIXMAN_pixbuf
PIXMAN_rpixbuf
and compute whether the source and mask have them in
find_fast_path(). This lead to some duplicate entries in the fast path
tables that could then be removed.
This flag was used to indicate that the mask was solid while still
allowing a specific format to be required. However, there is not
actually any need for this because the fast paths all used
_pixman_image_get_solid() which already allowed arbitrary formats.
The one thing that had to be dealt with was component alpha. In
addition to interpreting the presence of the NEED_COMPONENT_ALPHA
flag, we now also interprete the *absence* of this flag as a
requirement that the mask does *not* have component alpha.
Siarhei Siamashka pointed out that the first version of this commit
had a bug, in which a NEED_SOLID_MASK was accidentally not turned into
a PIXMAN_solid in the ARM NEON implementation.
When the destination buffer is either a8r8g8b8 or x8r8g8b8, we can use
it directly instead of fetching into a temporary buffer. When the
format is x8r8g8b8, we require the operator to not make use of
destination alpha, but when it is a8r8g8b8, there are no restrictions.
This is approximately a 5% speedup on the poppler cairo benchmark:
[ # ] backend test min(s) median(s) stddev. count
Before:
[ 0] image poppler 6.661 6.709 0.59% 6/6
After:
[ 0] image poppler 6.307 6.320 0.12% 5/6
This is a small speedup on the swfdec-youtube benchmark:
Before:
[ 0] image swfdec-youtube 5.789 5.806 0.20% 6/6
After:
[ 0] image swfdec-youtube 5.489 5.524 0.27% 6/6
Ie., approximately 5% faster.
GNU assembler and its macro preprocessor is now used to generate
NEON optimized functions from a common template. This automatically
takes care of nuisances like ensuring optimal alignment, dealing with
leading/trailing pixels, doing prefetch, etc.
Implementations for a lot of compositing functions are also added,
but not enabled.
Instead of mucking around with CFLAGS in configure.ac, preventing
users from setting their own CFLAGS, just define the
PIXMAN_USE_INTERNAL_API and PIXMAN_DISABLE_DEPRECATED in
pixman-private.h
This adds a bilinear fetcher for the case where the image has a scaled
transformation, does not repeat, and the format {ax}8r8g8b8.
Results for the swfdec-youtube benchmark
Before:
[ # ] backend test min(s) median(s) stddev. count
[ 0] image swfdec-youtube 7.841 7.915 0.72% 6/6
After:
[ # ] backend test min(s) median(s) stddev. count
[ 0] image swfdec-youtube 6.677 6.780 0.94% 6/6
These results were measured on a faster machine than the ones in the
previous commit, so the numbers are not comparable.
Signed-off-by: Søren Sandmann Pedersen <sandmann@redhat.com>
Speed up bilinear interpolation by processing more than one component
at a time on 64 bit architectures, and by precomputing the dist{ixiy}
products on 32 bit architectures.
Previously bilinear interpolation for one pixel would take 24
multiplications. With this improvement it takes 12 on 64 bit, and 20
on 32 bit.
This is a small but consistent speedup on the swfdec-youtube
benchmark:
[ # ] backend test min(s) median(s) stddev. count
Before:
[ 0] image swfdec-youtube 18.010 18.020 0.09% 4/5
After:
[ 0] image swfdec-youtube 17.488 17.584 0.22% 5/6
Signed-off-by: Søren Sandmann Pedersen <sandmann@redhat.com>
On Wed, 2009-10-21 at 13:36 +1000, Peter Hutterer wrote:
> On Tue, Oct 20, 2009 at 08:23:55PM -0700, Jeremy Huddleston wrote:
> > I noticed an INSTALL file in xlsclients and libXvMC today, and it
> > was quite annoying to work around since 'autoreconf -fvi' replaces
> > it and git wants to commit it. Should these files even be in git?
> > Can I nuke them for the betterment of humanity and since they get
> > created by autoreconf anyways?
>
> See https://bugs.freedesktop.org/show_bug.cgi?id=24206
As an interim measure, replace AM_INIT_AUTOMAKE([dist-bzip2]) with
AM_INIT_AUTOMAKE([foreign dist-bzip2]). This will prevent the generation
of the INSTALL file. It is also part of the 24206 solution.
Signed-off-by: Jeremy Huddleston <jeremyhu@freedesktop.org>
It was bounding the clip region to INT16_MIN, INT16_MAX, but this was
a relic from the X server. We don't need it since we are already
restricting the clip region to the geometry of the destination.
When masking out the x bits, blitter-test would make the incorrect
assumption that the they were always in the topmost position. This is
not correct for formats of type PIXMAN_TYPE_BGRA.
The first bug is that it is treating the input as if it were a1r1g1b1;
the second one is that the red channel should only be shifted two
bits, not three.
The original Render code used to index pixels with their position in
bits in the image. When the scanline code was introduced pixels were
indexed in bytes, but the FETCH/STORE_4/8 macros still assumed bits.
This commit fixes that by making the FETCH/STORE_4 macros first
convert the index to bit position.
These generally extracted the 2 bits of alpha, then shifted them 62
bits and replicated across 16 bits. Then they were shifted another 48
bits, making the resulting alpha channel 0.
For consistency we will probably want to allow component alpha to be
set on all masks at some point, but this commit only enabled it for
solid images.
This reverts commit 29e22cf38e.
On an Athlon64 box prefetch from NULL slows down
the rgba OVER rgba fast for predominantly solid sources
by up to 3.5x in the one-rounded-rectangle test case
when run using a tiling polygon renderer. This patch
conditionalises the prefetches of the mask everywhere
where the mask pointer may be NULL in a fast path.
Compile warnings are being lost in the sea of noise. Automake-1.11 finally
introduced AM_SILENT_RULES to suppress the echoing of the compile line for
every object. Enable this to bring sanity to the pixman build.
CFLAGS are always appended to the end of gcc options when compiling
sources in autotools based projects. Configure tests should do the
same. Otherwise build fails on PPC when using CFLAGS="-O2 -mno-altivec"
for example. Similar problem affects ARM.
This can help to fix build problems with '-mthumb' gcc option in CFLAGS.
ARMv6 optimized code can't be compiled for thumb (because of its inline
assembly) and gets automatically disabled in configure. Reference
to it from NEON optimized code resulted in linking problems.
Every ARMv6 optimized fast path function also has a better NEON
counterpart, so there is no need to fallback to ARMv6. Shorter
delegate chain should additionally result in a bit better performance.
Autoconf's AC_PROG_CC sets the default CFLAGS to -O2 -g for
gcc and -g for every other compiler. This patch defaults
CFLAGS to the equivalent -O -g when we're using Sun Studio's cc
if the user or site admin hasn't already set CFLAGS.
Calling a static function wrapper around _mm_set_epi32() when not
using optimisation causes Sun Studio 12's cc to emit a spurious
floating point load which confuses the assembler. Using a macro wrapper
rather than a function steps around the problem.
Some versions of gcc (cs2009q1, 4.4.1) incorrectly reject
shift operand having value >= 8, claiming that it is out of
range. So inline assembly is used as a workaround.
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
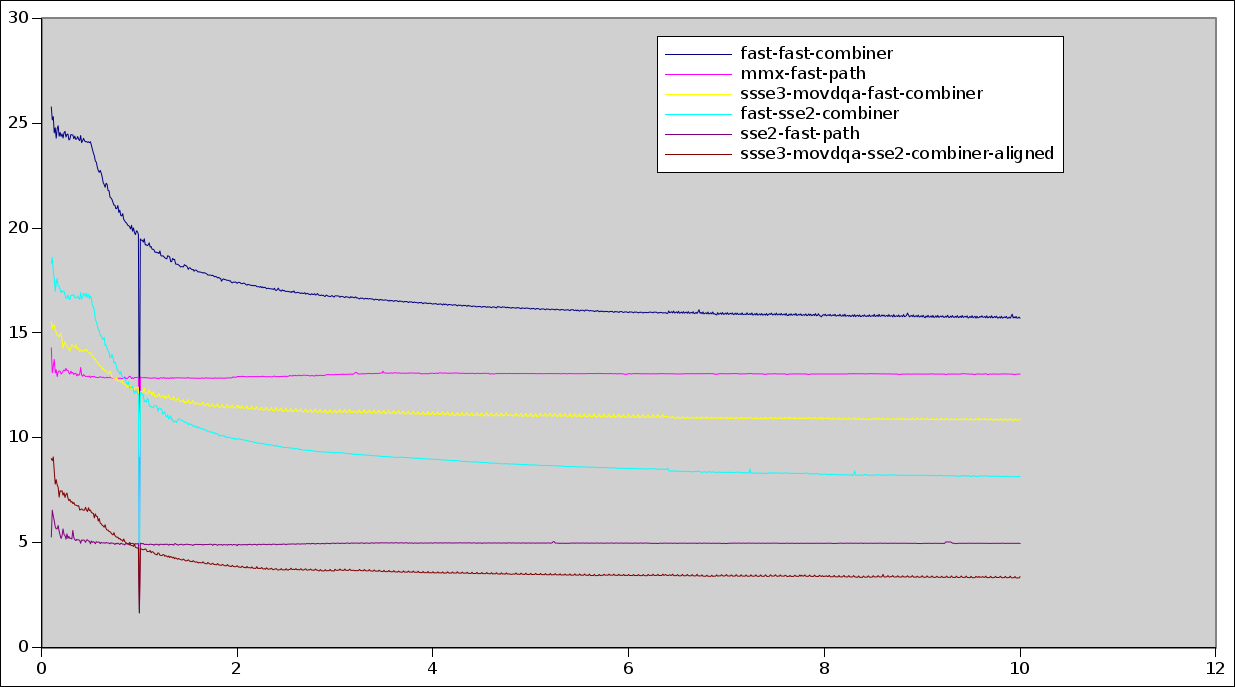{kind=link}
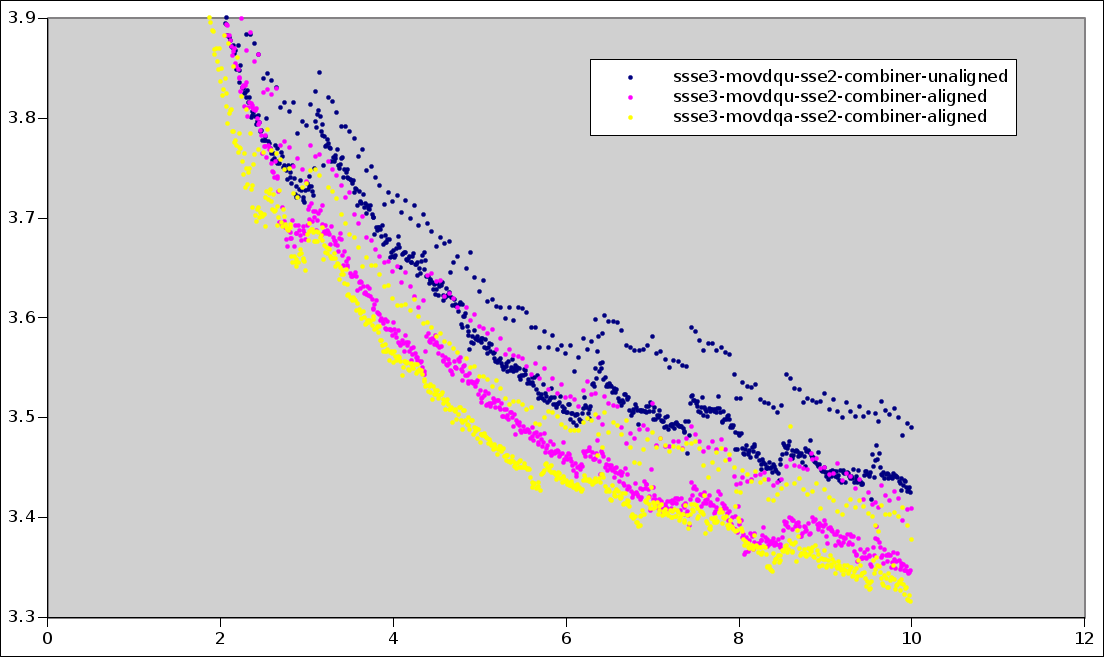{kind=link}
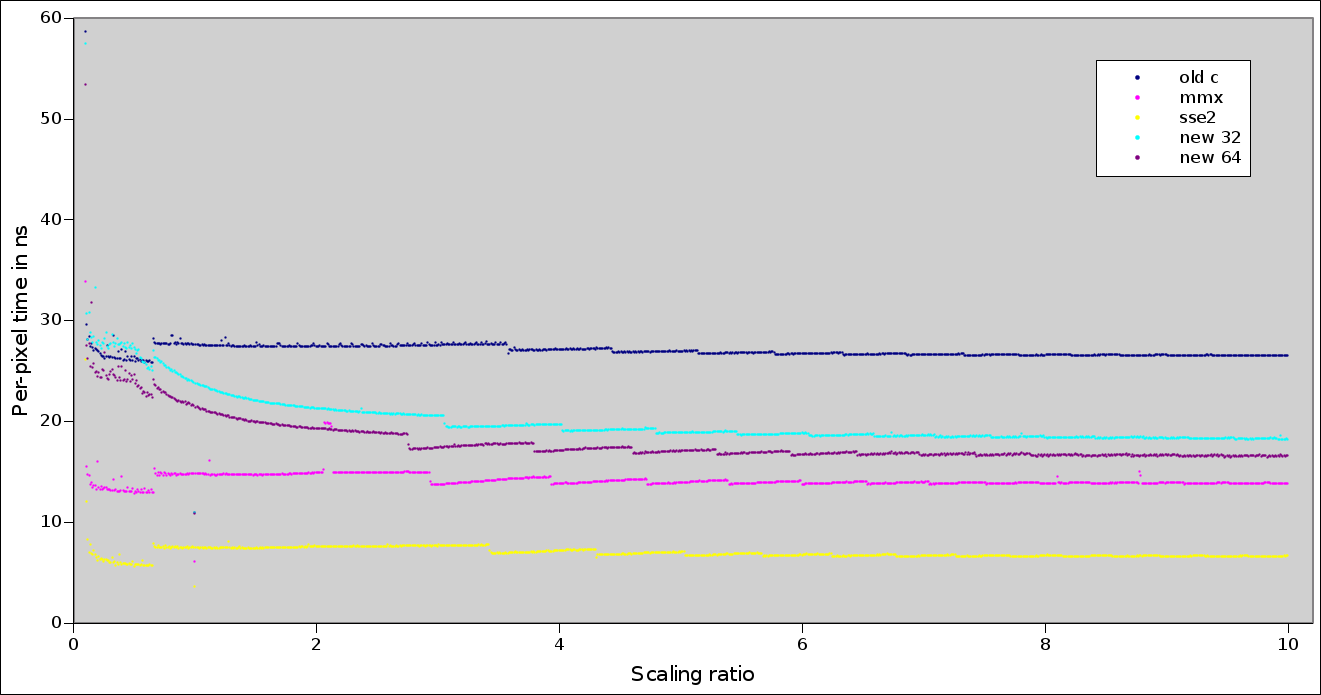{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}