The MSVC compiler is very strict about variable declarations after
statements.
Move all the declarations of each block before any statement in the
same block to fix multiple instances of:
alpha-loop.c(XX) : error C2275: 'pixman_image_t' : illegal use of this
type as an expression
I'm got bug in my system:
lcc: "scale.c", line 374: warning: function "gtk_scale_add_mark" declared
implicitly [-Wimplicit-function-declaration]
gtk_scale_add_mark (GTK_SCALE (widget), 0.0, GTK_POS_LEFT, NULL);
^
CCLD scale
scale.o: In function `app_new':
(.text+0x23e4): undefined reference to `gtk_scale_add_mark'
scale.o: In function `app_new':
(.text+0x250c): undefined reference to `gtk_scale_add_mark'
scale.o: In function `app_new':
(.text+0x2634): undefined reference to `gtk_scale_add_mark'
make[2]: *** [scale] Error 1
make[2]: Target `all' not remade because of errors.
$ pkg-config --modversion gtk+-2.0
2.12.1
The demos/scale.c use call to gtk_scale_add_mark() function from 2.16+
version of GTK+. Need do support old GTK+ (rewrite scale.c) or simple
demand of high version of GTK+, like this:
The SSE2, MMX, and fast implementations all have a copy of the
function iter_init_bits_stride that computes an image buffer and
stride.
Move that function to pixman-utils.c and share it among all the
implementations.
Now that we are using the new _pixman_implementation_iter_init(), the
old _src/_dest_iter_init() functions are no longer needed, so they can
be deleted, and the corresponding fields in pixman_implementation_t
can be removed.
A new field, 'iter_info', is added to the implementation struct, and
all the implementations store a pointer to their iterator tables in
it. A new function, _pixman_implementation_iter_init(), is then added
that searches those tables, and the new function is called in
pixman-general.c and pixman-image.c instead of the old
_pixman_implementation_src_init() and _pixman_implementation_dest_init().
In preparation for sharing all iterator initialization code from all
the implementations, move the general implementation to use a table of
pixman_iter_info_t.
The existing src_iter_init and dest_iter_init functions are
consolidated into one general_iter_init() function that checks the
iter_flags for whether it is dealing with a source or destination
iterator.
Unlike in the other implementations, the general_iter_init() function
stores its own get_scanline() and write_back() functions in the
iterator, so it relies on the initializer being called after
get_scanline and write_back being copied from the struct to the
iterator.
Similar to the SSE2 and MMX patches, this commit replaces a table of
fetcher_info_t with a table of pixman_iter_info_t, and similar to the
noop patch, both fast_src_iter_init() and fast_dest_iter_init() are
now doing exactly the same thing, so their code can be shared in a new
function called fast_iter_init_common().
Similar to the changes to noop, put all the iterators into a table of
pixman_iter_info_t and then do a generic search of that table during
iterator initialization.
Instead of having a nest of if statements, store the information about
iterators in a table of a new struct type, pixman_iter_info_t, and
then walk that table when initializing iterators.
The new struct contains a format, a set of image flags, and a set of
iter flags, plus a pixman_iter_get_scanline_t, a
pixman_iter_write_back_t, and a new function type
pixman_iter_initializer_t.
If the iterator matches an entry, it is first initialized with the
given get_scanline and write_back functions, and then the provided
iter_initializer (if present) is run. Running the iter_initializer
after setting get_scanline and write_back allows the initializer to
override those fields if it wishes.
The table contains both source and destination iterators,
distinguished based on the recently-added ITER_SRC and ITER_DEST;
similarly, wide iterators are recognized with the ITER_WIDE
flag. Having both source and destination iterators in the table means
the noop_src_iter_init() and noop_dest_iter_init() functions become
identical, so this patch factors out their code in a new function
noop_iter_init_common() that both calls.
The following patches in this series will change all the
implementations to use an iterator table, and then move the table
search code to pixman-implementation.c.
We only support alpha maps for BITS images, so it's always to ignore
the alpha map for non-BITS image. This makes it possible get rid of
the check for SOLID images since it will now be subsumed by the check
for FAST_PATH_NO_ALPHA_MAP.
Opaque masks are reduced to NULL images in pixman.c, and those can
also safely be treated as not having an alpha map, so set the
FAST_PATH_NO_ALPHA_MAP bit for those as well.
This will be useful for putting iterators into tables where they can
be looked up by iterator flags. Without this flag, wide iterators can
only be recognized by the absence of ITER_NARROW, which makes testing
for a match difficult.
These indicate whether the iterator is for a source or a destination
image. Note iterator initializers are allowed to rely on one of these
being set, so they can't be left out the way it's generally harmless
(aside from potentil performance degradation) to leave out a
particular fast path flag.
The Loongson code is compiled with -march=loongson2f to enable the MMI
instructions, but binutils refuses to link object code compiled with
different -march settings, leading to link failures later in the
compile. This avoids that problem by checking if we can link code
compiled for Loongson.
Reviewed-by: Matt Turner <mattst88@gmail.com>
Signed-off-by: Markos Chandras <markos.chandras@imgtec.com>
Add necessary support to lowlevel-blt benchmark for benchmarking pixbuf and
rpixbuf fast paths. bench_composite function now checks for pixbuf string in
testname, and if that is detected, use same bits for src and mask images.
Rounding logic was not implemented right.
Instead of using rounding version of the 8-bit shift, logical shifts were used.
Also, code used unnecessary multiplications, which could be avoided by packing
4 destination (a8) pixel into one 32bit register. There were also, unnecessary
spills on stack. Code is rewritten to address mentioned issues.
The bug was revealed by increasing number of the iterations in blitters-test.
Performance numbers on MIPS-74kc @ 1GHz:
lowlevel-blt-bench results
Referent (before):
in_n_8 = L1: 21.20 L2: 22.86 M: 21.42 ( 14.21%) HT: 15.97 VT: 15.69 R: 15.47 RT: 8.00 ( 48Kops/s)
Optimized (first implementation, with bug):
in_n_8 = L1: 89.38 L2: 86.07 M: 65.48 ( 43.44%) HT: 44.64 VT: 41.50 R: 40.77 RT: 16.94 ( 66Kops/s)
Optimized (with bug fix, and code revisited):
in_n_8 = L1: 102.33 L2: 95.65 M: 70.54 ( 46.84%) HT: 48.35 VT: 45.06 R: 43.20 RT: 17.60 ( 66Kops/s)
After introducing new PRNG (pseudorandom number generator) a bug in two DSPr2
routines was revealed. Bug manifested by wrong calculation in composite and
glyph tests, which caused make check to fail for MIPS DSPr2 optimizations.
Bug was in the calculation of the:
*dst = over (src, *dst) when ma == 0xffffffff
In this case src was not negated and shifted right by 24 bits, it was only
negated. When implementing this routine in the first place, I missplaced those
shifts, which alowed me to combine code for over operation and:
UN8x4_MUL_UN8x4 (s, ma);
UN8x4_MUL_UN8 (ma, srca);
ma = ~ma;
UN8x4_MUL_UN8x4_ADD_UN8x4 (d, ma, s);
So I decided to rewrite that piece of code from scratch. I changed logic, so
now assembly code mimics code from pixman-fast-path.c but processes two pixels
at a time. This code should be easier to debug and maintain.
The bug was revealed in commit b31a6962. Errors were detected by composite
and glyph tests.
The old code was calculating horizontal weights for right pixels
in the following way (for simplicity assume 8-bit interpolation
precision):
Start with "x = vx" and do increment "x += ux" after each pixel.
In this case right pixel weight for interpolation can be calculated
as "((x >> 8) ^ 0xFF) + 1", which is the same as "256 - (x >> 8)".
The new code instead:
Starts with "x = -(vx + 1)", performs increment "x += -ux" after
each pixel and calculates right weights as just "(x >> 8) + 1",
eliminating the need for XOR operation in the inner loop.
So we have one instruction less on the critical path. Benchmarks
with "lowlevel-blt-bench -b src_8888_8888" using GCC 4.7.2 on
x86-64 system and default optimizations:
Intel Core i7 860 (2.8GHz):
before: src_8888_8888 = L1: 291.37 L2: 288.58 M:285.38
after: src_8888_8888 = L1: 319.66 L2: 316.47 M:312.06
Intel Core2 T7300 (2GHz):
before: src_8888_8888 = L1: 121.95 L2: 118.38 M:118.52
after: src_8888_8888 = L1: 128.82 L2: 125.12 M:124.88
Intel Atom N450 (1.67GHz):
before: src_8888_8888 = L1: 64.25 L2: 62.37 M: 61.80
after: src_8888_8888 = L1: 64.23 L2: 62.37 M: 61.82
Inspired by the "sse2_bilinear_interpolation" function (single
pixel interpolation) from:
http://lists.freedesktop.org/archives/pixman/2013-January/002575.html
Current blitters-test program had difficulties detecting a bug in
over_n_8888_8888_ca implementation for MIPS DSPr2:
http://lists.freedesktop.org/archives/pixman/2013-March/002645.html
In order to hit the buggy code path, two consecutive mask values had
to be equal to 0xFFFFFFFF because of loop unrolling. The current
blitters-test generates random images in such a way that each byte
has 25% probability for having 0xFF value. Hence each 32-bit mask
value has ~0.4% probability for 0xFFFFFFFF. Because we are testing
many compositing operations with many pixels, encountering at least
one 0xFFFFFFFF mask value reasonably fast is not a problem. If a
bug related to 0xFFFFFFFF mask value is artificialy introduced into
over_n_8888_8888_ca generic C function, it gets detected on 675591
iteration in blitters-test (out of 2000000).
However two consecutive 0xFFFFFFFF mask values are much less likely
to be generated, so the bug was missed by blitters-test.
This patch addresses the problem by also randomly setting the 32-bit
values in images to either 0xFFFFFFFF or 0x00000000 (also with 25%
probability). It allows to have larger clusters of consecutive 0x00
or 0xFF bytes in images which may have special shortcuts for handling
them in unrolled or SIMD optimized code.
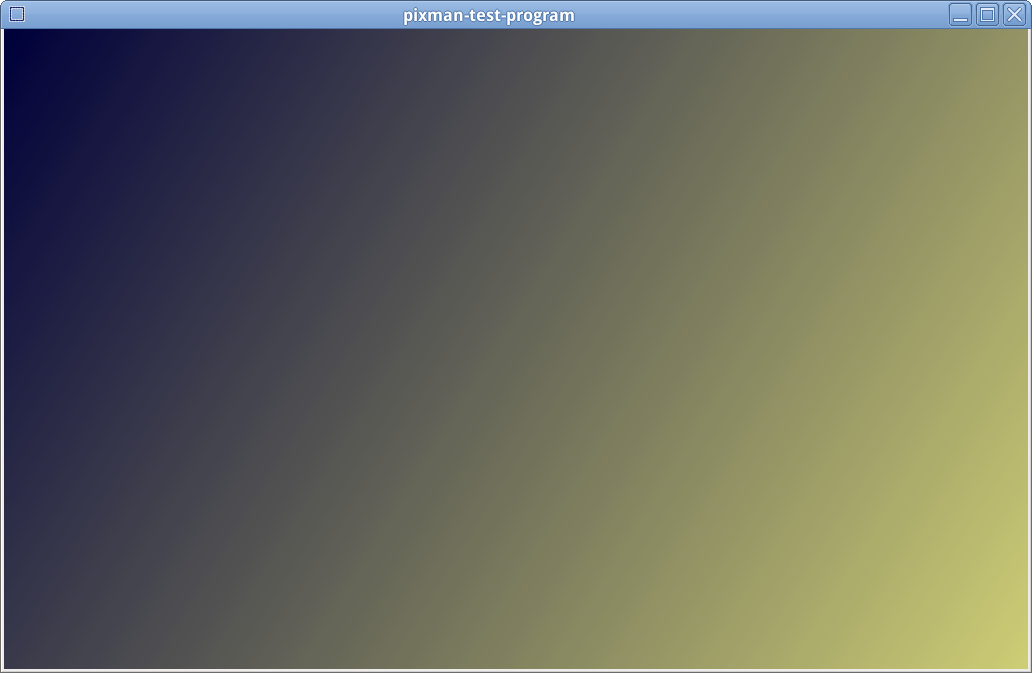
The computations in pixman-gradient-walker.c currently take place at
very limited 8 bit precision which results in quite visible artefacts
in gradients. An example is the one produced by demos/linear-gradient
which currently looks like this:
http://i.imgur.com/kQbX8nd.png
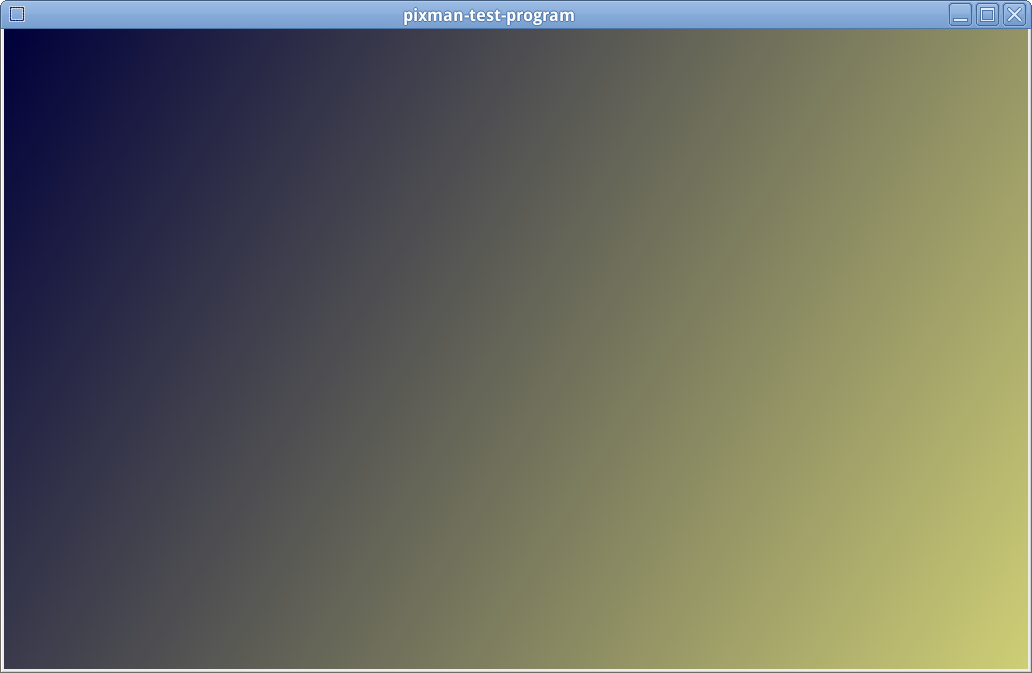
With the changes in this commit, the gradient looks like this:
http://i.imgur.com/nUlyuKI.png
The images are also available here:
http://people.freedesktop.org/~sandmann/gradients/before.pnghttp://people.freedesktop.org/~sandmann/gradients/after.png
This patch computes pixels using floating point, but uses a faster
algorithm, which makes up for the loss of performance.
== Theory:
In both the new and the old algorithm, the various gradient
implementations compute a parameter x that indicates how far along the
gradient the current scanline is. The current algorithm has a cache of
the two color stops surrounding the last parameter; those are used in
a SIMD-within-register fashion in this way:
t1 = walker->left_rb * idist + walker->right_rb * dist;
where dist and idist are the distances to the left and right color
stops respectively normalized to the distance between the left and
right stops. The normalization (which involves a division) is captured
in another cached variable "stepper". The cached values are recomputed
whenever the parameter moves in between two different stops (called
"reset" in the implementation).
Because idist and dist are computed in 8 bits only, a lot of
information is lost, which is quite visible as the image linked above
shows.
The new algorithm caches more information in the following way. When
interpolating between stops, the formula to be used is this:
t = ((x - left) / (right - left));
result = lc * (1 - t) + rc * t;
where
- x is the parameter as computed by the main gradient code,
- left is the position of the left color stop,
- right is the position of the right color stop
- lc is the color of the left color stop
- rc is the color of the right color stop
That formula can also be written like this:
result
= lc * (1 - t) + rc * t;
= lc + (rc - lc) * t
= lc + (rc - lc) * ((x - left) / (right - left))
= (rc - lc) / (right - left) * x +
lc - (left * (rc - lc)) / (right - left)
= s * x + b
where
s = (rc - lc) / (right - left)
and
b = lc - left * (rc - lc) / (right - left)
= (lc * (right - left) - left * (rc - lc)) / (right - left)
= (lc * right - rc * left) / (right - left)
To summarize, setting w = (right - left):
s = (rc - lc) / w
b = (lc * right - rc * left) / w
r = s * x + b
Since s and b only depend on the two active stops, both can be cached
so that the computation only needs to do one multiplication and one
addition per pixel (followed by premultiplication of the alpha
channel). That is, seven multiplications in total, which is the same
number as the old SIMD-within-register implementation had.
== Implementation notes:
The new formula described above is implemented in single precision
floating point, and the eight divisions necessary to compute the
cached values are done by multiplication with the reciprocal of the
distance between the color stops.
The alpha values used in the cached computation are scaled by 255.0,
whereas the RGB values are kept in the [0, 1] interval. The ensures
that after premultiplication, all values will be in the [0, 255]
interval.
This scaling is done by first dividing all the all the channels by
257, and then later on dividing the r, g, b channels by 255. It would
be more natural to do all this scaling in only one place, but
inexplicably, that results in a (substantial) slowdown on Sandy Bridge
with GCC v 4.7.
== Performance impact (median of three runs of radial-perf-test):
== Intel Sandy Bridge, Core i3 @ 1.2GHz
Before: 0.014553
After: 0.014410
Change: 1.0% faster
== AMD Barcelona @ 1.2 GHz
Before: 0.021735
After: 0.021328
Change: 1.9% faster
Ie., slightly faster, though conceivably there could be a negative
impact on machines with a bigger difference between integer and
floating point performance.
V2:
- Use 's' and 'b' in the variable names instead of 'm' and 'd'. This
way they match the explanation above
- Move variable declarations to the top of the function
- Remove unused stepper field
- Some formatting fixes
- Don't pointlessly include pixman-combine32.h
- Don't offset x for each pixel; go back to offsetting left_x and
right_x at reset time. The offsets cancel out in the formula above,
so there is no impact on the calcualations.
This benchmark renders one of the radial gradients used in the
swfdec-youtube cairo trace 500 times and reports the average time it
took.
V2: Update .gitignore
This program displays a linear gradient from blue to yellow. Due to
limited precision in pixman-gradient-walker.c, it currently has some
ugly artefacts that gives it a 'brushed metal' appearance.
V2: Update .gitignore
{kind=link}
{kind=link}
{kind=link}
{kind=link}