The SIMD optimized inner loops in the VMX/Altivec code are trying
to emulate unaligned accesses to the destination buffer. For each
4 pixels (which fit into a 128-bit register) the current
implementation:
1. first performs two aligned reads, which cover the needed data
2. reshuffles bytes to get the needed data in a single vector register
3. does all the necessary calculations
4. reshuffles bytes back to their original location in two registers
5. performs two aligned writes back to the destination buffer
Unfortunately in the case if the destination buffer is unaligned and
the width is a perfect multiple of 4 pixels, we may have some writes
crossing the boundaries of the destination buffer. In a multithreaded
environment this may potentially corrupt the data outside of the
destination buffer if it is concurrently read and written by some
other thread.
The valgrind report for blitters-test is full of:
==23085== Invalid write of size 8
==23085== at 0x1004B0B4: vmx_combine_add_u (pixman-vmx.c:1089)
==23085== by 0x100446EF: general_composite_rect (pixman-general.c:214)
==23085== by 0x10002537: test_composite (blitters-test.c:363)
==23085== by 0x1000369B: fuzzer_test_main._omp_fn.0 (utils.c:733)
==23085== by 0x10004943: fuzzer_test_main (utils.c:728)
==23085== by 0x10002C17: main (blitters-test.c:397)
==23085== Address 0x5188218 is 0 bytes after a block of size 88 alloc'd
==23085== at 0x4051DA0: memalign (vg_replace_malloc.c:581)
==23085== by 0x4051E7B: posix_memalign (vg_replace_malloc.c:709)
==23085== by 0x10004CFF: aligned_malloc (utils.c:833)
==23085== by 0x10001DCB: create_random_image (blitters-test.c:47)
==23085== by 0x10002263: test_composite (blitters-test.c:283)
==23085== by 0x1000369B: fuzzer_test_main._omp_fn.0 (utils.c:733)
==23085== by 0x10004943: fuzzer_test_main (utils.c:728)
==23085== by 0x10002C17: main (blitters-test.c:397)
This patch addresses the problem by first aligning the destination
buffer at a 16 byte boundary in each combiner function. This trick
is borrowed from the pixman SSE2 code.
It allows to pass the new thread-test on PowerPC VMX/Altivec systems and
also resolves the "make check" failure reported for POWER7 hardware:
http://lists.freedesktop.org/archives/pixman/2013-August/002871.html
This test program allocates an array of 16 * 7 uint32_ts and spawns 16
threads that each use 7 of the allocated uint32_ts as a destination
image for a large number of composite operations. Each thread then
computes and returns a checksum for the image. Finally, the main
thread computes a checksum of the checksums and verifies that it
matches expectations.
The purpose of this test is catch errors where memory outside images
is read and then written back. Such out-of-bounds accesses are broken
when multiple threads are involved, because the threads will race to
read and write the shared memory.
V2:
- Incorporate fixes from Siarhei for endianness and undefined behavior
regarding argument evaluation
- Make the images 7 pixels wide since the bug only happens when the
composite width is greater than 4.
- Compute a checksum of the checksums so that you don't have to
update 16 values if something changes.
V3: Remove stray dollar sign
The test for pthread_setspecific() can be used as a general test for
whether pthreads are available, so rename the variable from
HAVE_PTHREAD_SETSPECIFIC to HAVE_PTHREADS and run the test even when
better support for thread local variables are available.
However, the pthread arguments are still only added to CFLAGS and
LDFLAGS when pthread_setspecific() is used for thread local variables.
V2: AC_SUBST(PTHREAD_CFLAGS)
Use a temporary variable s containing the absolute value of the stride
as the upper bound in the inner loops.
V2: Do this for the bpp == 16 case as well
Commit 4312f07736 claimed to have made
print_image() work with negative strides, but it didn't actually
work. When the stride was negative, the image buffer would be accessed
as if the stride were positive.
Fix the bug by not changing the stride variable and instead using a
temporary, s, that contains the absolute value of stride.
Instead of having logic to swap the lines around when one of them
doesn't match, store the two lines in an array and use the least
significant bit of the y coordinate as the index into that
array. Since the two lines always have different least significant
bits, they will never collide.
The effect is that lines corresponding to even y coordinates are
stored in info->lines[0] and lines corresponding to odd y coordinates
are stored in info->lines[1].
Pixman supports negative strides, but up until now they haven't been
tested outside of stress-test. This commit adds testing of negative
strides to blitters-test, scaling-test, affine-test, rotate-test, and
composite-traps-test.
The affine-test, blitters-test, and scaling-test all have the ability
to print out the bytes of the destination image. Share this code by
moving it to utils.c.
At the same time make the code work correctly with negative strides.
Converting a double precision number to 16.16 fixed point should be
done by multiplying with 65536.0, not 65535.0.
The bug could potentially cause certain filters that would otherwise
leave the image bit-for-bit unchanged under an identity
transformation, to not do so, but the numbers are close enough that
there weren't any visual differences.
The separable convolution filter supports a subsample_bits of 0 which
corresponds to no subsampling at all, so allow this value to be used
in the scale demo.
This new iterator uses the SSSE3 instructions pmaddubsw and pabsw to
implement a fast iterator for bilinear scaling.
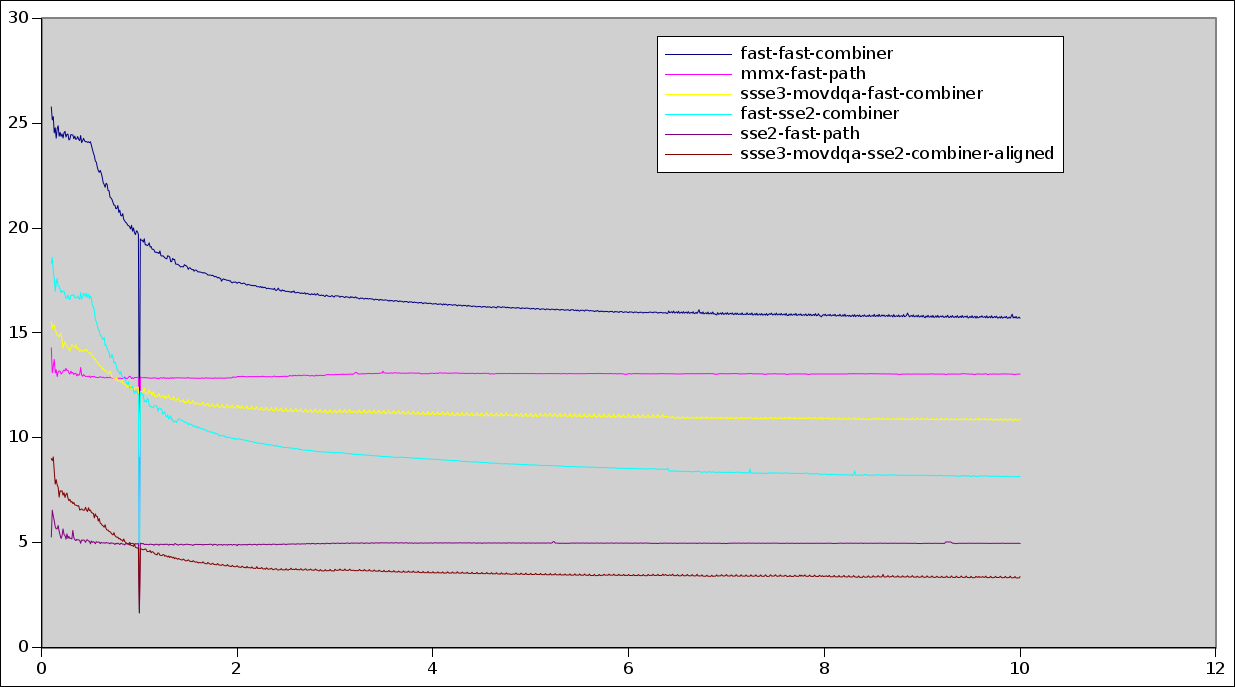
There is a graph here recording the per-pixel time for various
bilinear scaling algorithms as reported by scaling-bench:
http://people.freedesktop.org/~sandmann/ssse3.v2/ssse3.v2.png
As the graph shows, this new iterator is clearly faster than the
existing C iterator, and when used with an SSE2 combiner, it is also
faster than the existing SSE2 fast paths for upscaling, though not for
downscaling.
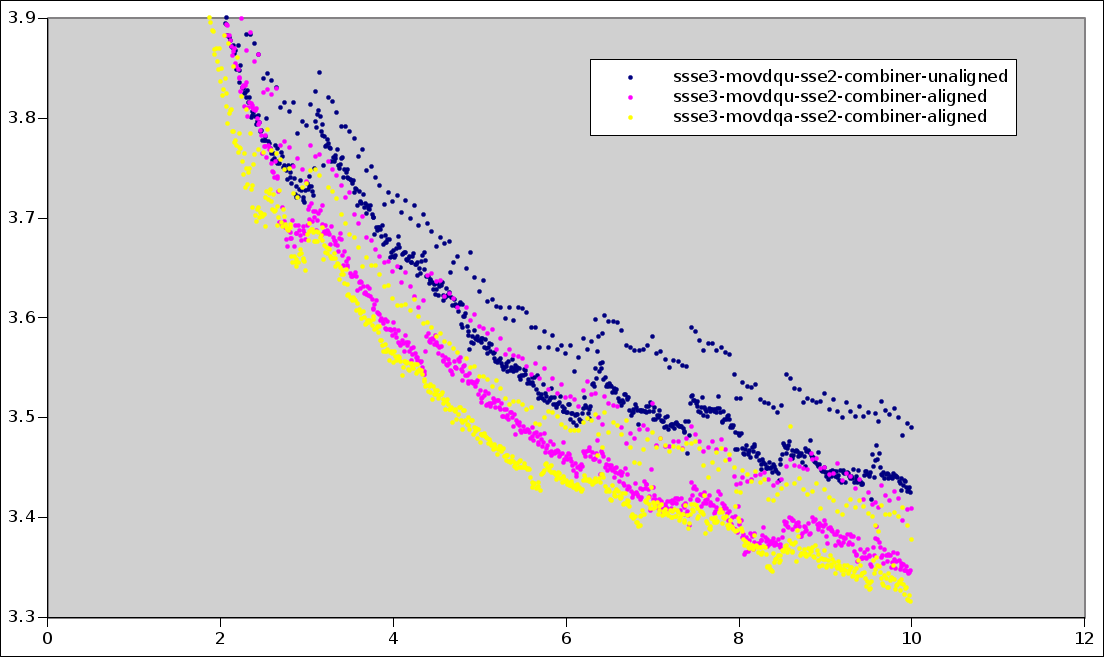
Another graph:
http://people.freedesktop.org/~sandmann/ssse3.v2/movdqu.png
shows the difference between writing to iter->buffer with movdqa,
movdqu on an aligned buffer, and movdqu on a deliberately unaligned
buffer. Since the differences are very small, the patch here avoids
using movdqa because imposing alignment restrictions on iter->buffer
may interfere with other optimizations, such as writing directly to
the destination image.
The data was measured with scaling-bench on a Sandy Bridge Core
i3-2350M @ 2.3GHz and is available in this directory:
http://people.freedesktop.org/~sandmann/ssse3.v2/
where there is also a Gnumeric spreadsheet ssse3.v2.gnumeric
containing the per-pixel values and the graph.
V2:
- Use uintptr_t instead of unsigned long in the ALIGN macro
- Use _mm_storel_epi64 instead of _mm_cvtsi128_si64 as the latter form
is not available on x86-32.
- Use _mm_storeu_si128() instead of _mm_store_si128() to avoid
imposing alignment requirements on iter->buffer
This commit adds a new, empty SSSE3 implementation and the associated
build system support.
configure.ac: detect whether the compiler understands SSSE3
intrinsics and set up the required CFLAGS
Makefile.am: Add libpixman-ssse3.la
pixman-x86.c: Add X86_SSSE3 feature flag and detect it in
detect_cpu_features().
pixman-ssse3.c: New file with an empty SSSE3 implementation
V2: Remove SSSE3_LDFLAGS since it isn't necessary unless Solaris
support is added.
At the moment iter buffers are only guaranteed to be aligned to a 4
byte boundary. SIMD implementations benefit from the buffers being
aligned to 16 bytes, so ensure this is the case.
V2:
- Use uintptr_t instead of unsigned long
- allocate 3 * SCANLINE_BUFFER_LENGTH byte on stack rather than just
SCANLINE_BUFFER_LENGTH
- use sizeof (stack_scanline_buffer) instead of SCANLINE_BUFFER_LENGTH
to determine overflow
The loops are already unrolled, so it was just a matter of packing
4 pixels into a single XMM register and doing aligned 128-bit
writes to memory via MOVDQA instructions for the SRC compositing
operator fast path. For the other fast paths, this XMM register
is also directly routed to further processing instead of doing
extra reshuffling. This replaces "8 PACKSSDW/PACKUSWB + 4 MOVD"
instructions with "3 PACKSSDW/PACKUSWB + 1 MOVDQA" per 4 pixels,
which results in a clear performance improvement.
There are also some other (less important) tweaks:
1. Convert 'pixman_fixed_t' to 'intptr_t' before using it as an
index for addressing memory. The problem is that 'pixman_fixed_t'
is a 32-bit data type and it has to be extended to 64-bit
offsets, which needs extra instructions on 64-bit systems.
2. Allow to recalculate the horizontal interpolation weights only
once per 4 pixels by treating the XMM register as four pairs
of 16-bit values. Each of these 16-bit/16-bit pairs can be
replicated to fill the whole 128-bit register by using PSHUFD
instructions. So we get "3 PADDW/PSRLW + 4 PSHUFD" instructions
per 4 pixels instead of "12 PADDW/PSRLW" per 4 pixels
(or "3 PADDW/PSRLW" per each pixel).
Now a good question is whether replacing "9 PADDW/PSRLW" with
"4 PSHUFD" is a favourable exchange. As it turns out, PSHUFD
instructions are very fast on new Intel processors (including
Atoms), but are rather slow on the first generation of Core2
(Merom) and on the other processors from that time or older.
A good instructions latency/throughput table, covering all the
relevant processors, can be found at:
http://www.agner.org/optimize/instruction_tables.pdf
Enabling this optimization is controlled by the PSHUFD_IS_FAST
define in "pixman-sse2.c".
3. One use of PSHUFD instruction (_mm_shuffle_epi32 intrinsic) in
the older code has been also replaced by PUNPCKLQDQ equivalent
(_mm_unpacklo_epi64 intrinsic) in PSHUFD_IS_FAST=0 configuration.
The PUNPCKLQDQ instruction is usually faster on older processors,
but has some side effects (instead of fully overwriting the
destination register like PSHUFD does, it retains half of the
original value, which may inhibit some compiler optimizations).
Benchmarks with "lowlevel-blt-bench -b src_8888_8888" using GCC 4.8.1 on
x86-64 system and default optimizations. The results are in MPix/s:
====== Intel Core2 T7300 (2GHz) ======
old: src_8888_8888 = L1: 128.69 L2: 125.07 M:124.86
over_8888_8888 = L1: 83.19 L2: 81.73 M: 80.63
over_8888_n_8888 = L1: 79.56 L2: 78.61 M: 77.85
over_8888_8_8888 = L1: 77.15 L2: 75.79 M: 74.63
new (PSHUFD_IS_FAST=0): src_8888_8888 = L1: 168.67 L2: 163.26 M:162.44
over_8888_8888 = L1: 102.91 L2: 100.43 M: 99.01
over_8888_n_8888 = L1: 97.40 L2: 95.64 M: 94.24
over_8888_8_8888 = L1: 98.04 L2: 95.83 M: 94.33
new (PSHUFD_IS_FAST=1): src_8888_8888 = L1: 154.67 L2: 149.16 M:148.48
over_8888_8888 = L1: 95.97 L2: 93.90 M: 91.85
over_8888_n_8888 = L1: 93.18 L2: 91.47 M: 90.15
over_8888_8_8888 = L1: 95.33 L2: 93.32 M: 91.42
====== Intel Core i7 860 (2.8GHz) ======
old: src_8888_8888 = L1: 323.48 L2: 318.86 M:314.81
over_8888_8888 = L1: 187.38 L2: 186.74 M:182.46
new (PSHUFD_IS_FAST=0): src_8888_8888 = L1: 373.06 L2: 370.94 M:368.32
over_8888_8888 = L1: 217.28 L2: 215.57 M:211.32
new (PSHUFD_IS_FAST=1): src_8888_8888 = L1: 401.98 L2: 397.65 M:395.61
over_8888_8888 = L1: 218.89 L2: 217.56 M:213.48
The most interesting benchmark is "src_8888_8888" (because this code can
be reused for a generic non-separable SSE2 bilinear fetch iterator).
The results shows that PSHUFD instructions are bad for Intel Core2 T7300
(Merom core) and good for Intel Core i7 860 (Nehalem core). Both of these
processors support SSSE3 instructions though, so they are not the primary
targets for SSE2 code. But without having any other more relevant hardware
to test, PSHUFD_IS_FAST=0 seems to be a reasonable default for SSE2 code
and old processors (until the runtime CPU features detection becomes
clever enough to recognize different microarchitectures).
(Rebased on top of patch that removes support for 8-bit bilinear
filtering -ssp)
The calloc call from pixman_image_create_bits may still
rely on http://en.wikipedia.org/wiki/Copy-on-write
Explicitly initializing the destination image results in
a more predictable behaviour.
V2:
- allocate 16 bytes aligned buffer with aligned stride instead
of delegating this to pixman_image_create_bits
- use memset for the allocated buffer instead of pixman solid fill
- repeat tests 3 times and select best results in order to filter
out even more measurement noise
The default has been 7-bit for a while now, and the quality
improvement with 8-bit precision is not enough to justify keeping the
code around as a compile-time option.
Scanline fetchers haven't been used for images other than bits for a
long time, so by making the type reflect this fact, a bit of casting
can be saved in various places.
Later versions of gcc-4.7.x are capable of generating iwMMXt
instructions properly, but gcc-4.8 contains better support and other
fixes, including iwMMXt in conjunction with hardfp. The existing 4.5
requirement was based on attempts to have OLPC use a patched gcc to
build pixman. Let's just require gcc-4.8.
This new iterator works in a separable way; that is, for a destination
scaline, it scales the two involved source scanlines and then caches
them so that they can be reused for the next destination scanlines.
There are two versions of the code, one that uses 64 bit arithmetic,
and one that uses 32 bit arithmetic only. The latter version is
used on 32 bit systems, where it is expected to be faster.
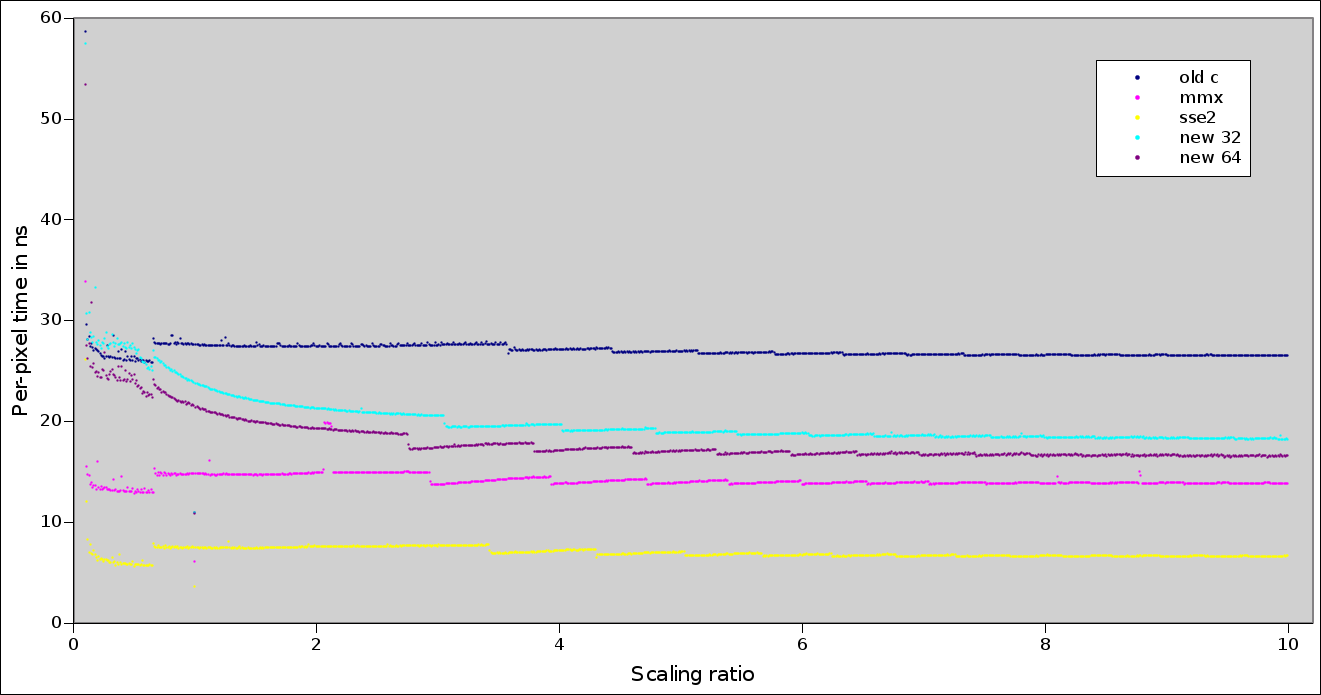
This scheme saves a substantial amount of arithmetic for larger
scalings; the per-pixel times for various configurations as reported
by scaling-bench are graphed here:
http://people.freedesktop.org/~sandmann/separable.v2/v2.png
The "sse2" graph is current default on x86, "mmx" is with sse2
disabled, "old c" is with sse2 and mmx disabled. The "new 32" and "new
64" graphs show times for the new code. As the graphs show, the 64 bit
version of the new code beats the "old c" for all scaling ratios.
The data was taken on a Sandy Bridge Core i3-2350M CPU @ 2.0 GHz
running in 64 bit mode.
The data used to generate the graph is available in this directory:
http://people.freedesktop.org/~sandmann/separable.v2/
There is also a Gnumeric spreadsheet v2.gnumeric containing the
per-pixel values and the graph.
V2:
- Add error message in the OOM/bad matrix case
- Save some shifts by storing the cached scanlines in AGBR order
- Special cased version that uses 32 bit arithmetic when sizeof(long) <= 4
This new benchmark scales a 320 x 240 test a8r8g8b8 image by all
ratios from 0.1, 0.2, ... up to 10.0 and reports the time it to took
to do each of the scaling operations, and the time spent per
destination pixel.
The times reported for the scaling operations are given in
milliseconds, the times-per-pixel are in nanoseconds.
V2: Format output better
The MSVC compiler is very strict about variable declarations after
statements.
Move all the declarations of each block before any statement in the
same block to fix multiple instances of:
alpha-loop.c(XX) : error C2275: 'pixman_image_t' : illegal use of this
type as an expression
I'm got bug in my system:
lcc: "scale.c", line 374: warning: function "gtk_scale_add_mark" declared
implicitly [-Wimplicit-function-declaration]
gtk_scale_add_mark (GTK_SCALE (widget), 0.0, GTK_POS_LEFT, NULL);
^
CCLD scale
scale.o: In function `app_new':
(.text+0x23e4): undefined reference to `gtk_scale_add_mark'
scale.o: In function `app_new':
(.text+0x250c): undefined reference to `gtk_scale_add_mark'
scale.o: In function `app_new':
(.text+0x2634): undefined reference to `gtk_scale_add_mark'
make[2]: *** [scale] Error 1
make[2]: Target `all' not remade because of errors.
$ pkg-config --modversion gtk+-2.0
2.12.1
The demos/scale.c use call to gtk_scale_add_mark() function from 2.16+
version of GTK+. Need do support old GTK+ (rewrite scale.c) or simple
demand of high version of GTK+, like this:
The Loongson code is compiled with -march=loongson2f to enable the MMI
instructions, but binutils refuses to link object code compiled with
different -march settings, leading to link failures later in the
compile. This avoids that problem by checking if we can link code
compiled for Loongson.
Reviewed-by: Matt Turner <mattst88@gmail.com>
Signed-off-by: Markos Chandras <markos.chandras@imgtec.com>
{kind=link}
{kind=link}
{kind=link}